Word Form Matters: LLMs' Semantic Reconstruction under Typoglycemia
作者: Chenxi Wang, Tianle Gu, Zhongyu Wei, Lang Gao, Zirui Song, Xiuying Chen
分类: cs.CL, cs.AI
发布日期: 2025-03-03
备注: 14 pages, 10 figures, submitted to ACL Rolling Review, February 2025 cycle, see https://github.com/Aurora-cx/TypoLLM
💡 一句话要点
研究发现LLM在乱序词理解中过度依赖词形,并提出SemRecScore评估语义重构能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 乱序词理解 语义重构 注意力机制 词形信息
📋 核心要点
- 现有LLM在乱序词理解方面表现出一定能力,但其内在机制尚不明确,需要深入研究。
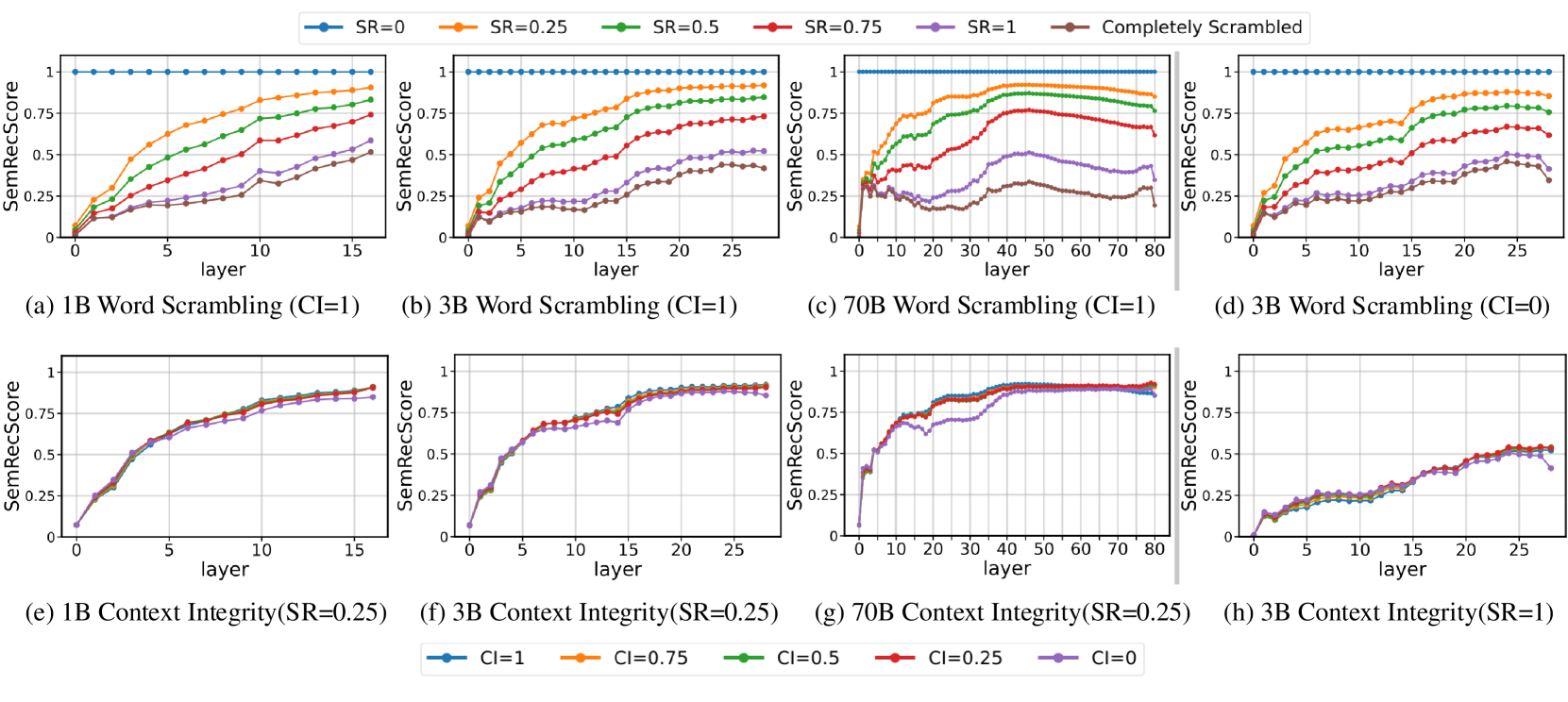
- 论文提出SemRecScore指标量化语义重构程度,并分析词形和上下文信息对LLM的影响。
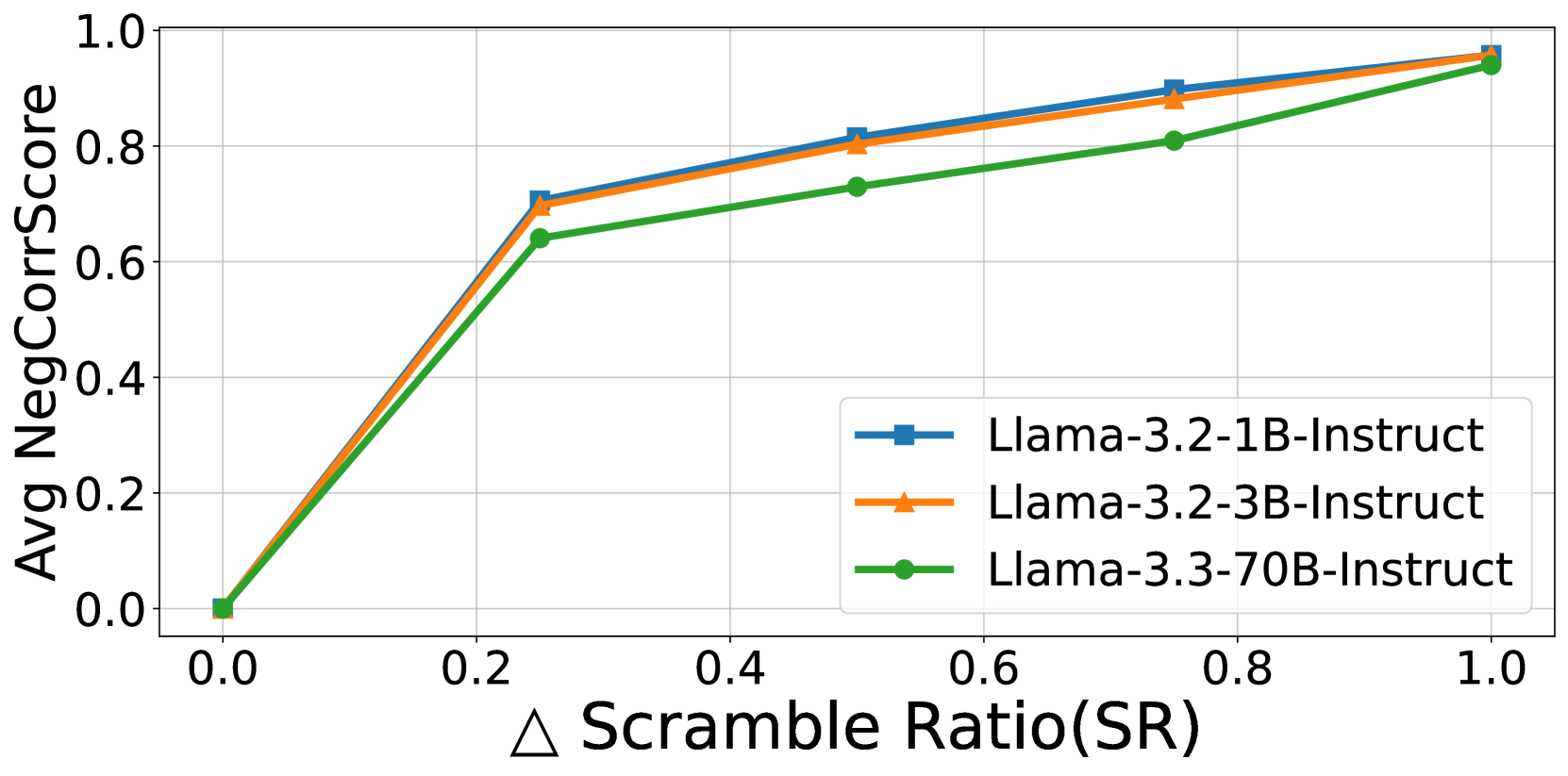
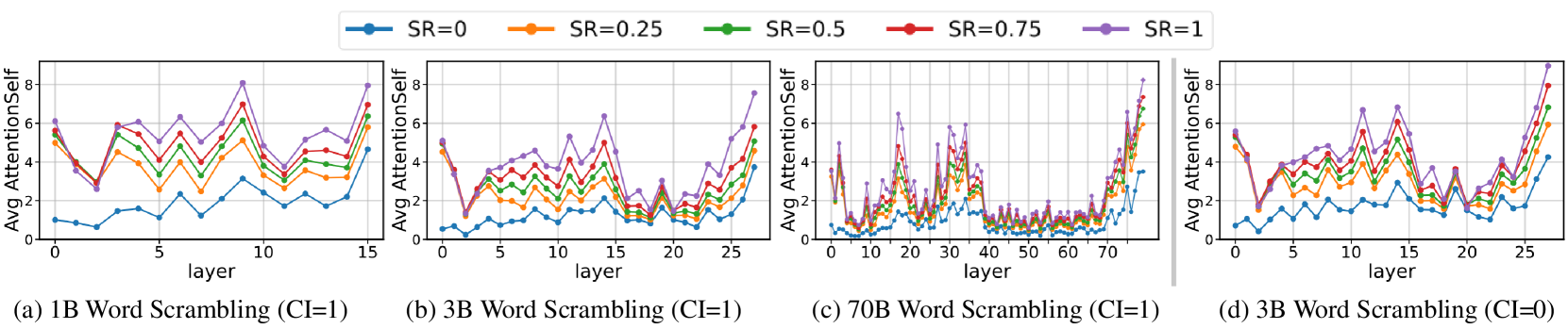
- 实验表明LLM过度依赖词形信息,且使用专门的注意力头处理词形,与人类的策略不同。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在乱序词(Typoglycemia)下的语义重构能力,即人类读者能够有效理解乱序单词的现象。研究表明,LLM虽然表现出类似的能力,但其内在机制尚不明确。通过控制实验,分析了词形和上下文信息在语义重构中的作用,并检查了LLM的注意力模式。首先,提出了SemRecScore,一种量化语义重构程度的可靠指标,并验证了其有效性。然后,使用该指标研究了词形和上下文信息如何影响LLM的语义重构能力,发现词形是这一过程中的核心因素。此外,分析了LLM如何利用词形,发现它们依赖于专门的注意力头来提取和处理词形信息,且这种机制在不同程度的单词乱序下保持稳定。LLM主要关注词形的固定注意力模式与人类读者在词形和上下文信息之间进行自适应平衡的策略不同,这为通过结合类人、上下文感知机制来增强LLM性能提供了见解。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLM)在处理乱序词(Typoglycemia)时,如何进行语义重构。现有研究对LLM如何利用词形和上下文信息进行语义理解的内在机制缺乏深入了解,特别是与人类的认知方式相比,LLM是否存在差异。
核心思路:论文的核心思路是通过设计控制实验,量化LLM在不同乱序程度下对词形的依赖程度,并分析其注意力机制,从而揭示LLM与人类在乱序词理解上的差异。通过对比LLM和人类对词形和上下文信息的利用方式,为改进LLM的性能提供新的思路。
技术框架:论文的技术框架主要包括三个部分:1) 提出SemRecScore指标,用于量化LLM的语义重构能力;2) 设计控制实验,操纵词形和上下文信息,观察LLM的语义重构表现;3) 分析LLM的注意力模式,特别是与词形相关的注意力头的行为。
关键创新:论文的关键创新在于:1) 提出了SemRecScore指标,为量化语义重构能力提供了一种新的方法;2) 揭示了LLM在乱序词理解中过度依赖词形信息,与人类的上下文感知策略存在差异;3) 发现了LLM使用专门的注意力头来处理词形信息,为理解LLM的内部机制提供了新的视角。
关键设计:SemRecScore指标的具体计算方法未知,但其目的是量化LLM在给定乱序词的情况下,能够多大程度上恢复其原始语义。控制实验通过改变单词的乱序程度和上下文信息的丰富程度,来观察LLM的语义重构表现。注意力模式分析则关注LLM中不同注意力头的权重分布,特别是那些与词形相关的注意力头。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在乱序词理解中主要依赖词形信息,即使在上下文信息丰富的情况下,也未能有效利用上下文。通过分析注意力模式发现,LLM使用专门的注意力头来提取和处理词形信息,且这种机制在不同乱序程度下保持稳定。SemRecScore指标的有效性也得到了验证。
🎯 应用场景
该研究成果可应用于提升LLM在自然语言处理任务中的鲁棒性和泛化能力,尤其是在处理拼写错误、OCR识别错误等场景下。通过引入类人、上下文感知的机制,可以使LLM更好地理解和处理不规范的文本输入,提高其在实际应用中的可靠性。
📄 摘要(原文)
Human readers can efficiently comprehend scrambled words, a phenomenon known as Typoglycemia, primarily by relying on word form; if word form alone is insufficient, they further utilize contextual cues for interpretation. While advanced large language models (LLMs) exhibit similar abilities, the underlying mechanisms remain unclear. To investigate this, we conduct controlled experiments to analyze the roles of word form and contextual information in semantic reconstruction and examine LLM attention patterns. Specifically, we first propose SemRecScore, a reliable metric to quantify the degree of semantic reconstruction, and validate its effectiveness. Using this metric, we study how word form and contextual information influence LLMs' semantic reconstruction ability, identifying word form as the core factor in this process. Furthermore, we analyze how LLMs utilize word form and find that they rely on specialized attention heads to extract and process word form information, with this mechanism remaining stable across varying levels of word scrambling. This distinction between LLMs' fixed attention patterns primarily focused on word form and human readers' adaptive strategy in balancing word form and contextual information provides insights into enhancing LLM performance by incorporating human-like, context-aware mechanisms.