The Emergence of Grammar through Reinforcement Learning
作者: Stephen Wechsler, James W. Shearer, Katrin Erk
分类: cs.CL, cs.IT
发布日期: 2025-03-03
备注: 49 pages, 8 figures
💡 一句话要点
提出基于强化学习的语法演化模型,探索语言表达目的对语法形成的影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 语法演化 自然语言处理 语言模型 功能主义语言学
📋 核心要点
- 现有语法演化模型缺乏对说话者表达目的的有效建模,难以解释语言的形成。
- 提出一种基于强化学习的框架,将语言学习分解为简单步骤,并融入信息概率。
- 通过数值模拟和案例研究,验证了该模型在模拟语言历史和解释语言现象方面的潜力。
📝 摘要(中文)
本文利用强化学习理论,对句法和语义组合的语法系统的演化进行建模。为了验证功能主义的观点,即说话者的表达目的塑造了他们的语言,该模型包含了一个概率分布,用于表示在给定上下文中可能表达的不同信息。所提出的学习和生成算法将语言学习分解为一系列简单的步骤,每个步骤都受益于信息概率。研究结果以语言历史的数值模拟和分析证明的形式呈现。通过对英语历史的两个案例研究,说明了将这些数学模型应用于自然语言研究的潜力。
🔬 方法详解
问题定义:论文旨在模拟语法系统的演化过程,特别是句法和语义组合规则的形成。现有方法通常忽略了说话者的表达目的,即在特定语境下选择表达特定信息的概率分布,这限制了对语言功能主义视角的理解。因此,论文要解决的问题是如何将说话者的表达目的纳入语法演化模型中,从而更真实地模拟语言的形成过程。
核心思路:论文的核心思路是利用强化学习框架,将语言学习过程建模为一个序列决策问题。智能体(说话者)通过与环境(听者)交互,学习如何使用语法规则来表达信息。关键在于,智能体的奖励函数不仅取决于表达是否成功,还取决于表达的信息是否符合说话者的意图,即信息概率分布。通过这种方式,模型能够学习到更符合人类语言使用习惯的语法规则。
技术框架:该模型包含以下主要模块:1) 信息生成器:根据给定的上下文,生成一个信息概率分布,表示说话者可能想要表达的不同信息。2) 语法规则学习器:使用强化学习算法,学习句法和语义组合规则,用于将信息编码成语言表达。3) 语言生成器:根据学习到的语法规则,将信息编码成语言表达。4) 听者模型:用于评估语言表达的质量,并提供奖励信号给语法规则学习器。整个流程是一个循环迭代的过程,通过不断地学习和反馈,语法规则学习器逐渐优化语法规则,最终形成一个稳定的语法系统。
关键创新:该论文最重要的技术创新点在于将信息概率分布纳入强化学习框架中,从而能够更真实地模拟说话者的表达意图。与传统的语法演化模型相比,该模型能够更好地解释语言的功能主义视角,即语言的形成受到说话者表达目的的影响。
关键设计:论文中关键的设计包括:1) 使用概率分布来表示信息,从而能够处理不确定性和模糊性。2) 使用强化学习算法来学习语法规则,从而能够自动地发现最优的语法规则。3) 使用听者模型来评估语言表达的质量,从而能够保证语言表达的有效性。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
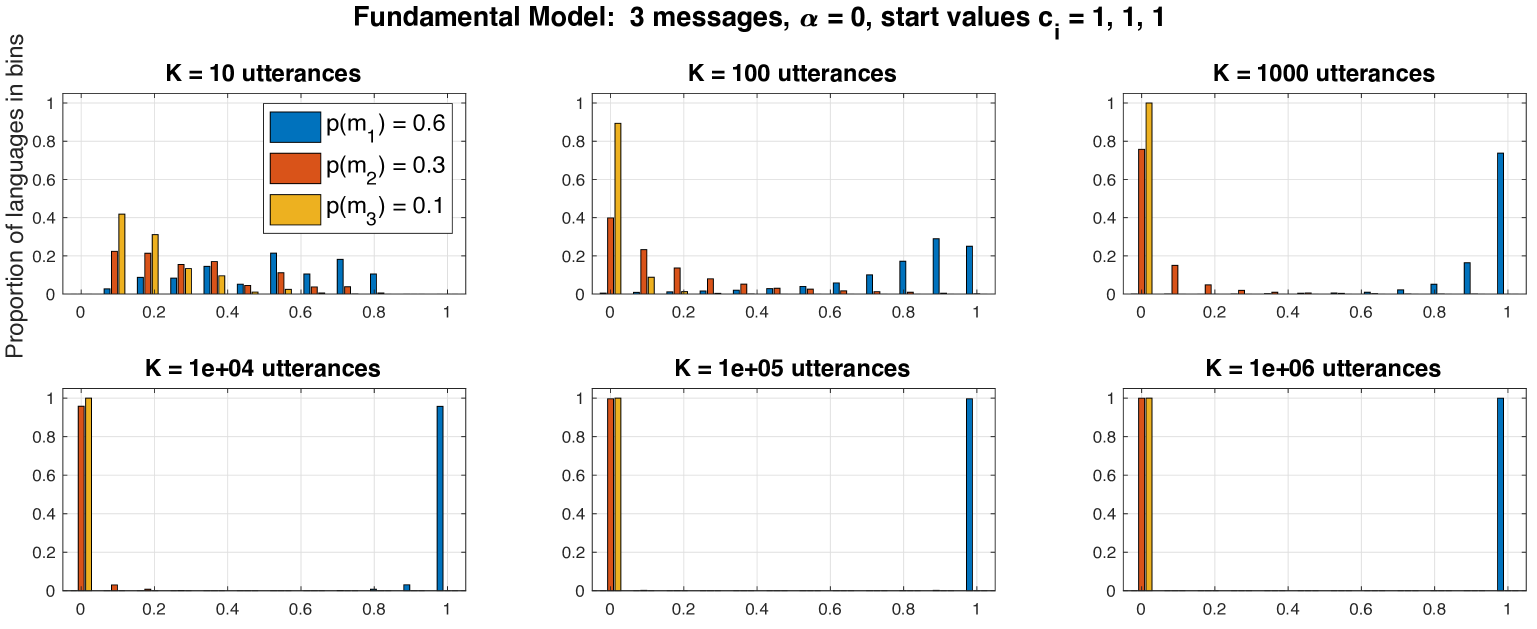
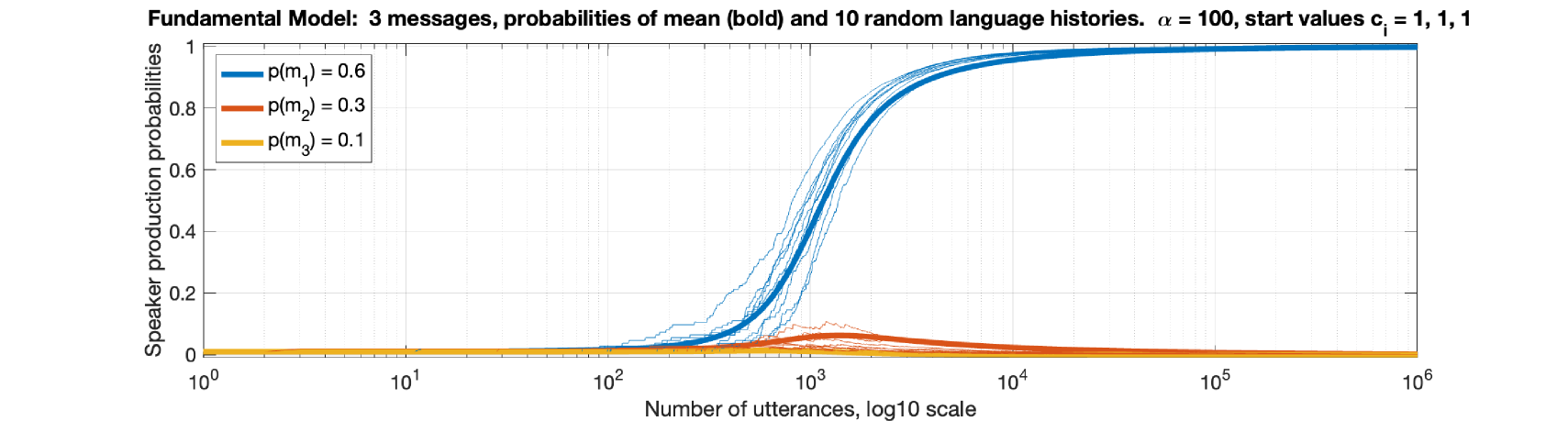
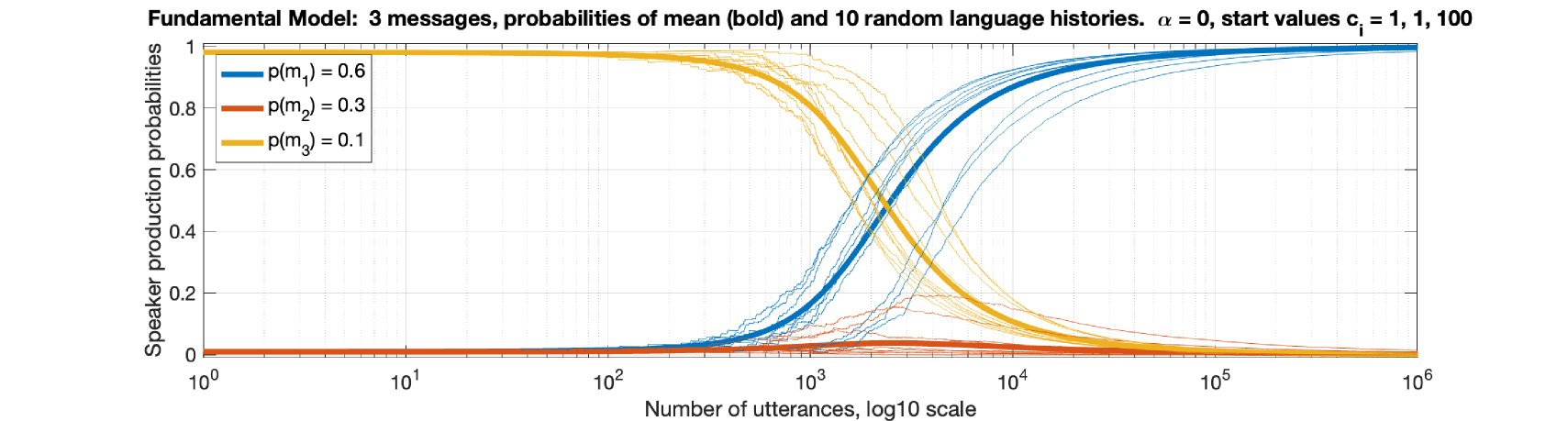
📊 实验亮点
论文通过数值模拟展示了该模型能够成功地演化出简单的语法系统,并且能够捕捉到一些真实的语言现象。此外,论文还通过对英语历史的两个案例研究,说明了该模型能够用于解释语言的演化和变迁。具体的性能数据和提升幅度在摘要中没有提及,属于未知信息。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、语言学和认知科学。它可以用于开发更智能的语言生成系统,帮助我们更好地理解人类语言的本质,并为语言教学和学习提供新的思路。此外,该模型还可以用于研究语言的演化和变迁,从而揭示语言的深层规律。
📄 摘要(原文)
The evolution of grammatical systems of syntactic and semantic composition is modeled here with a novel application of reinforcement learning theory. To test the functionalist thesis that speakers' expressive purposes shape their language, we include within the model a probability distribution over different messages that could be expressed in a given context. The proposed learning and production algorithm then breaks down language learning into a sequence of simple steps, such that each step benefits from the message probabilities. The results are presented in the form of numerical simulations of language histories and analytic proofs. The potential for applying these mathematical models to the study of natural language is illustrated with two case studies from the history of English.