OmniRouter: Budget and Performance Controllable Multi-LLM Routing
作者: Kai Mei, Wujiang Xu, Minghao Guo, Shuhang Lin, Yongfeng Zhang
分类: cs.DB, cs.CL
发布日期: 2025-02-27 (更新: 2025-11-28)
🔗 代码/项目: GITHUB
💡 一句话要点
OmniRouter:提出预算和性能可控的多LLM路由框架,优化资源分配。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM路由 资源分配 约束优化 拉格朗日对偶分解 检索增强预测 多LLM服务 成本优化
📋 核心要点
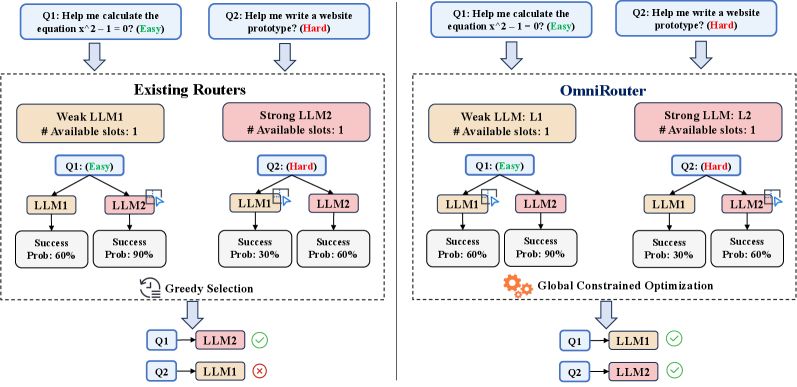
- 现有LLM路由方法通常采用局部最优决策,忽略全局预算约束,导致资源分配效率低下。
- OmniRouter将LLM路由建模为约束优化问题,在满足性能要求下最小化总成本,实现全局最优分配。
- 实验表明,OmniRouter在提升响应准确率的同时,显著降低了计算成本,优于现有基线方法。
📝 摘要(中文)
大型语言模型(LLMs)虽然性能卓越,但需要大量的计算资源且效率相对较低,而较小的模型可以高效地处理资源需求较少的简单任务。LLM路由是一种关键范式,它从候选模型池中动态选择最适合的大型语言模型来处理不同的输入,从而确保最佳的资源利用率并保持响应质量。现有的路由框架通常将此建模为局部最优的决策问题,即为每个查询单独选择假定的最佳LLM,这忽略了全局预算约束,导致资源分配效率低下。为了解决这个问题,我们引入了OmniRouter,这是一个从根本上可控的用于多LLM服务的路由框架。OmniRouter没有做出每个查询的贪婪选择,而是将路由任务建模为一个约束优化问题,分配能够最小化总成本同时确保所需性能水平的模型。具体来说,我们设计了一个混合检索增强预测器来预测LLM的能力和成本。在获得预测的成本和性能后,我们利用一个约束优化器进行成本最优分配,该优化器采用带有自适应乘数的拉格朗日对偶分解。它迭代地收敛到全局最优的查询-模型分配,动态地平衡延迟最小化与质量阈值,同时遵守异构容量约束。实验表明,与有竞争力的路由器基线相比,OmniRouter在响应准确率方面提高了高达6.30%,同时将计算成本降低了至少10.15%。代码和数据集可在https://github.com/dongyuanjushi/OmniRouter获取。
🔬 方法详解
问题定义:论文旨在解决多LLM服务场景下,如何根据全局预算和性能要求,高效地进行LLM路由选择的问题。现有方法通常采用贪婪算法,为每个查询独立选择最优LLM,忽略了全局资源约束,导致整体资源利用率不高,无法在预算限制下达到最佳性能。
核心思路:OmniRouter的核心思路是将LLM路由问题建模为一个约束优化问题。通过预测每个LLM处理特定查询的成本和性能,然后在全局预算约束下,寻找最优的LLM分配方案,从而在满足性能要求的同时,最小化总成本。
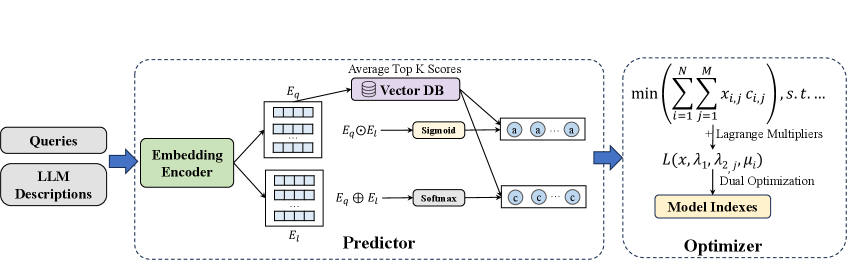
技术框架:OmniRouter包含以下主要模块:1) 混合检索增强预测器:用于预测LLM处理特定查询的成本和性能。该预测器结合了检索和预测模型,以提高预测的准确性。2) 约束优化器:基于拉格朗日对偶分解,寻找满足预算约束和性能要求的成本最优LLM分配方案。该优化器采用自适应乘数,以加速收敛并提高解的质量。
关键创新:OmniRouter的关键创新在于将LLM路由问题建模为一个全局约束优化问题,并采用拉格朗日对偶分解进行求解。与现有方法相比,OmniRouter能够更好地利用全局信息,实现更优的资源分配。此外,混合检索增强预测器也提高了LLM成本和性能预测的准确性。
关键设计:混合检索增强预测器可能包含以下设计:1) 使用检索模块从历史数据中检索相似的查询和LLM组合,以提供先验信息。2) 使用预测模型(例如,神经网络)基于查询和LLM的特征,预测成本和性能。约束优化器可能采用以下设计:1) 定义成本函数,表示总计算成本。2) 定义约束条件,包括预算约束和性能要求。3) 使用拉格朗日对偶分解将约束优化问题转化为无约束优化问题,并采用梯度下降等方法进行求解。
🖼️ 关键图片
📊 实验亮点
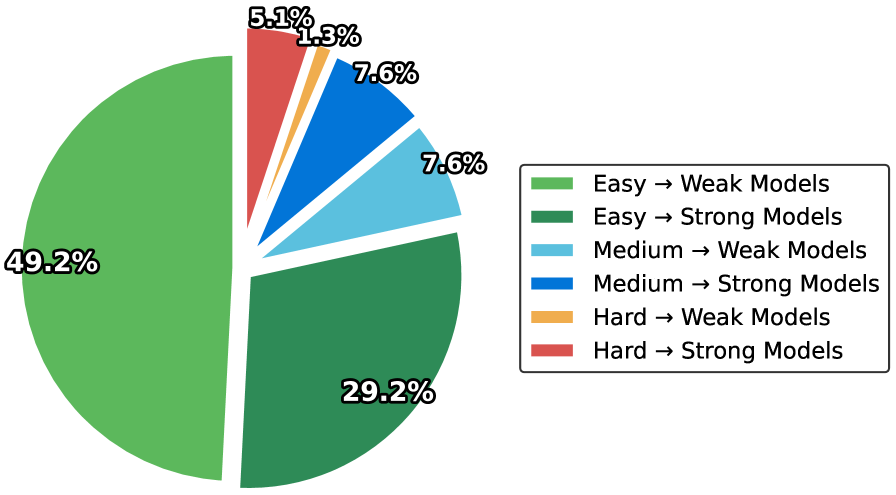
实验结果表明,OmniRouter在响应准确率方面比现有基线方法提高了高达6.30%,同时将计算成本降低了至少10.15%。这些结果表明,OmniRouter能够有效地平衡性能和成本,实现更优的LLM路由。
🎯 应用场景
OmniRouter可应用于各种需要多LLM服务的场景,例如智能客服、内容生成、代码生成等。通过优化LLM路由,OmniRouter可以降低服务成本,提高响应速度,并提升用户体验。该研究对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large language models (LLMs) deliver superior performance but require substantial computational resources and operate with relatively low efficiency, while smaller models can efficiently handle simpler tasks with fewer resources. LLM routing is a crucial paradigm that dynamically selects the most suitable large language models from a pool of candidates to process diverse inputs, ensuring optimal resource utilization while maintaining response quality. Existing routing frameworks typically model this as a locally optimal decision-making problem, selecting the presumed best-fit LLM for each query individually, which overlooks global budget constraints, resulting in ineffective resource allocation. To tackle this problem, we introduce OmniRouter, a fundamentally controllable routing framework for multi-LLM serving. Instead of making per-query greedy choices, OmniRouter models the routing task as a constrained optimization problem, assigning models that minimize total cost while ensuring the required performance level. Specifically, a hybrid retrieval-augmented predictor is designed to predict the capabilities and costs of LLMs. After obtaining the predicted cost and performance, we utilize a constrained optimizer for cost-optimal assignments that employs Lagrangian dual decomposition with adaptive multipliers. It iteratively converges toward the globally optimal query-model allocation, dynamically balancing latency minimization against quality thresholds while adhering to heterogeneous capacity constraints. Experiments show that OmniRouter achieves up to 6.30% improvement in response accuracy while simultaneously reducing computational costs by at least 10.15% compared to competitive router baselines. The code and the dataset are available at https://github.com/dongyuanjushi/OmniRouter.