LinguaLens: Towards Interpreting Linguistic Mechanisms of Large Language Models via Sparse Auto-Encoder
作者: Yi Jing, Zijun Yao, Hongzhu Guo, Lingxu Ran, Xiaozhi Wang, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2025-02-27 (更新: 2025-09-15)
备注: Accepted by EMNLP 2025 MainConference
💡 一句话要点
LinguaLens:通过稀疏自编码器解析大型语言模型的语言机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语言机制 稀疏自编码器 反事实分析 可解释性
📋 核心要点
- 现有研究在分析LLM的语言机制时,存在粒度粗糙、分析规模有限以及关注点狭窄等问题。
- LinguaLens框架利用稀疏自编码器和反事实方法,系统性地分析LLM中的语言机制。
- 研究揭示了LLM中语言知识的内在表示,发现了跨层和跨语言的分布模式,并展示了控制模型输出的潜力。
📝 摘要(中文)
大型语言模型(LLMs)在需要复杂语言能力的任务上表现出卓越的性能,例如指代消歧和隐喻识别/生成。尽管LLMs具有令人印象深刻的能力,但它们处理和表示语言知识的内部机制在很大程度上仍然不透明。以往对语言机制的研究受到粗粒度、有限的分析规模和狭窄的关注点的限制。在本研究中,我们提出了LinguaLens,这是一个系统而全面的框架,用于分析基于稀疏自编码器(SAEs)的大型语言模型的语言机制。我们提取了跨四个维度(形态学、句法、语义学和语用学)的广泛的中英文语言特征。通过采用反事实方法,我们构建了一个大规模的反事实语言特征数据集,用于机制分析。我们的发现揭示了LLMs中语言知识的内在表示,揭示了跨层和跨语言分布的模式,并展示了控制模型输出的潜力。这项工作提供了一套系统的资源和方法来研究语言机制,为LLMs拥有真正的语言知识提供了强有力的证据,并为未来研究中更可解释和可控的语言建模奠定了基础。
🔬 方法详解
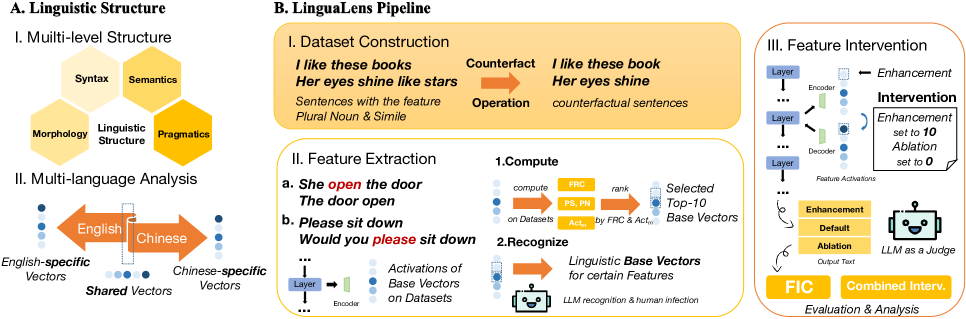
问题定义:大型语言模型在语言理解和生成方面表现出色,但其内部如何处理和表示语言知识仍然是一个黑盒。现有的语言机制研究存在粒度粗、规模小、范围窄等问题,难以深入理解LLM的语言能力来源。
核心思路:本论文的核心思路是通过稀疏自编码器(SAEs)来解剖LLM的内部表示,并结合反事实分析方法,探究LLM如何利用语言特征进行推理和决策。SAEs能够学习到稀疏的、可解释的特征表示,从而帮助理解LLM的内部运作机制。
技术框架:LinguaLens框架主要包含以下几个阶段:1) 语言特征提取:从形态学、句法、语义学和语用学四个维度提取中英文语言特征。2) 稀疏自编码器训练:利用LLM的激活值训练SAEs,学习语言特征的稀疏表示。3) 反事实数据集构建:通过修改语言特征,构建反事实数据集,用于分析LLM对不同语言特征的敏感度。4) 机制分析:分析SAEs学习到的特征表示,以及LLM对反事实数据的响应,从而理解LLM的语言机制。
关键创新:该论文的关键创新在于:1) 提出了一个系统而全面的框架LinguaLens,用于分析LLM的语言机制。2) 利用稀疏自编码器学习LLM的内部表示,并结合反事实分析方法,深入探究LLM的语言能力来源。3) 构建了一个大规模的反事实语言特征数据集,用于机制分析。
关键设计:在SAEs的训练过程中,采用了L1正则化来保证特征的稀疏性。反事实数据集的构建过程中,需要仔细设计修改语言特征的方式,以保证反事实数据的合理性和有效性。机制分析过程中,需要设计合适的指标来衡量LLM对不同语言特征的敏感度。
🖼️ 关键图片

📊 实验亮点
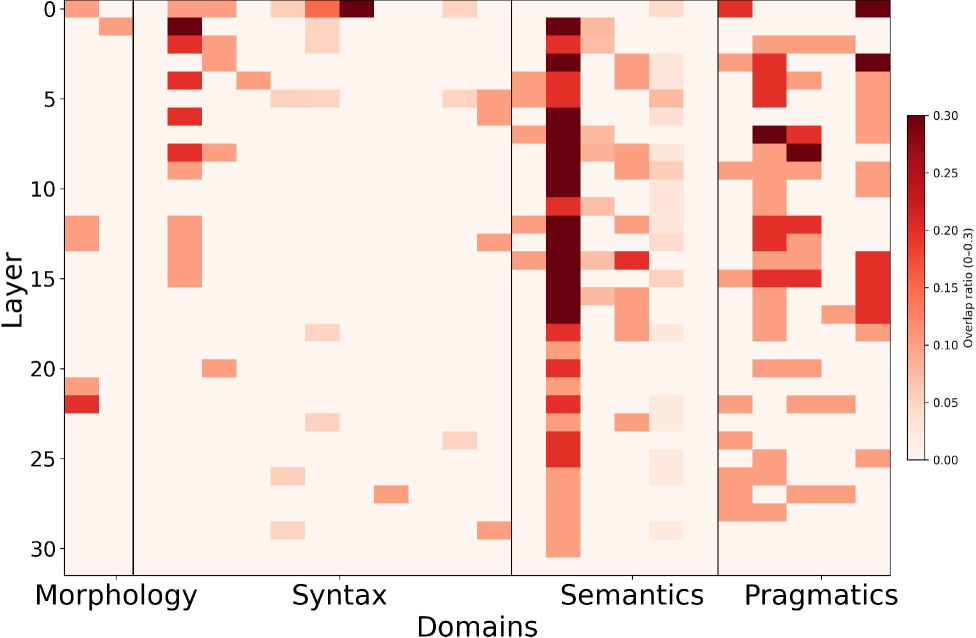
LinguaLens框架通过实验揭示了LLM中语言知识的内在表示,发现了跨层和跨语言的分布模式。例如,研究发现LLM的不同层级对不同类型的语言特征具有不同的敏感度。此外,研究还展示了通过控制SAEs学习到的特征表示,可以控制LLM的输出。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性和可控性,例如,通过理解LLM的语言机制,可以更好地控制模型的生成结果,避免生成不符合要求的文本。此外,该研究还可以帮助我们更好地理解人类语言的本质,促进自然语言处理领域的发展。
📄 摘要(原文)
Large language models (LLMs) demonstrate exceptional performance on tasks requiring complex linguistic abilities, such as reference disambiguation and metaphor recognition/generation. Although LLMs possess impressive capabilities, their internal mechanisms for processing and representing linguistic knowledge remain largely opaque. Prior research on linguistic mechanisms is limited by coarse granularity, limited analysis scale, and narrow focus. In this study, we propose LinguaLens, a systematic and comprehensive framework for analyzing the linguistic mechanisms of large language models, based on Sparse Auto-Encoders (SAEs). We extract a broad set of Chinese and English linguistic features across four dimensions (morphology, syntax, semantics, and pragmatics). By employing counterfactual methods, we construct a large-scale counterfactual dataset of linguistic features for mechanism analysis. Our findings reveal intrinsic representations of linguistic knowledge in LLMs, uncover patterns of cross-layer and cross-lingual distribution, and demonstrate the potential to control model outputs. This work provides a systematic suite of resources and methods for studying linguistic mechanisms, offers strong evidence that LLMs possess genuine linguistic knowledge, and lays the foundation for more interpretable and controllable language modeling in future research.