Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
作者: Haochen Sun, Shuwen Zhang, Lujie Niu, Lei Ren, Hao Xu, Hao Fu, Fangkun Zhao, Caixia Yuan, Xiaojie Wang
分类: cs.CL, cs.AI, cs.MA
发布日期: 2025-02-27 (更新: 2025-09-25)
备注: Accepted to EMNLP 2025 Main Conference. Camera-Ready Version. 30 pages, 17 figures
DOI: 10.18653/v1/2025.emnlp-main.249
🔗 代码/项目: GITHUB
💡 一句话要点
提出Collab-Overcooked基准测试,用于评估LLM在协作环境中的智能体能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 协作智能体 基准测试 Overcooked-AI 自然语言交流 过程评估
📋 核心要点
- 现有LLM多智能体系统缺乏在复杂交互环境中细粒度协作能力的有效评估。
- Collab-Overcooked基准通过多智能体框架和面向过程的评估指标,促进自然语言交流和协作。
- 实验表明LLM在目标理解方面表现出色,但在主动协作和持续适应方面存在不足。
📝 摘要(中文)
本文提出了一种新的基于大型语言模型的多智能体系统(LLM-MAS)基准测试,名为Collab-Overcooked。该基准建立在流行的Overcooked-AI游戏之上,并在交互环境中提供更具实用性和挑战性的任务。Collab-Overcooked通过两种新颖的方式扩展了现有基准。首先,它提供了一个多智能体框架,支持多样化的任务和目标,并通过自然语言交流促进协作。其次,它引入了一系列面向过程的评估指标,以评估不同LLM智能体的细粒度协作能力,这是先前工作中经常被忽视的一个维度。我们使用13个流行的LLM进行了广泛的实验,结果表明,虽然LLM在目标解释方面表现出强大的能力,但在主动协作和持续适应方面存在显著的不足,而这些对于高效完成复杂任务至关重要。值得注意的是,我们强调了LLM-MAS的优势和劣势,并为在一个统一的开源基准上改进和评估LLM-MAS提供了见解。环境、30个开放式任务和评估包已在https://github.com/YusaeMeow/Collab-Overcooked上公开发布。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在复杂协作环境中的多智能体系统(MAS)能力的问题。现有方法通常侧重于通用NLP任务,缺乏对LLM在交互式环境中细粒度协作能力的评估,例如主动沟通、持续适应等。Overcooked-AI游戏虽然提供了一个协作环境,但缺乏对LLM智能体协作过程的深入评估。
核心思路:论文的核心思路是构建一个基于Overcooked-AI游戏的新的LLM-MAS基准测试,Collab-Overcooked。该基准通过扩展Overcooked-AI游戏,提供多样化的任务和目标,并引入面向过程的评估指标,从而能够更全面地评估LLM智能体的协作能力。通过自然语言交流,鼓励智能体之间的协作,并提供更具挑战性的任务。
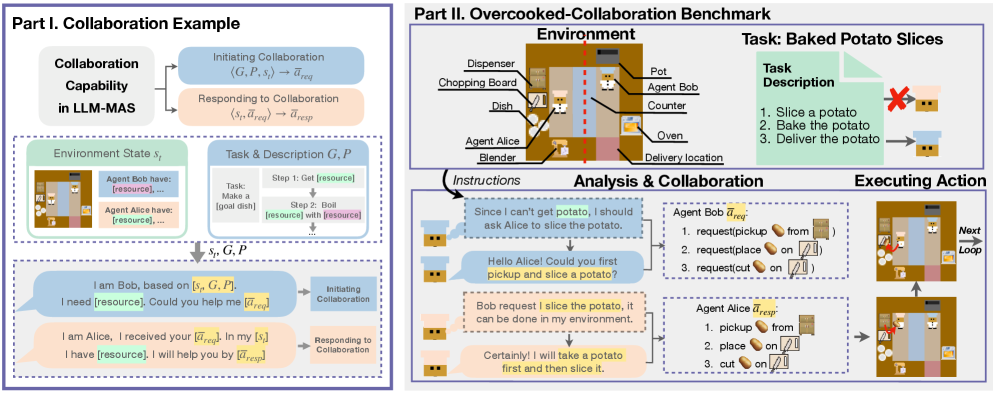
技术框架:Collab-Overcooked基准测试包含以下主要模块:1) Overcooked-AI游戏环境的扩展,提供更复杂的任务和目标;2) 多智能体框架,支持多个LLM智能体在环境中进行交互;3) 自然语言交流模块,允许智能体之间通过自然语言进行沟通;4) 面向过程的评估指标,用于评估智能体的协作能力,例如沟通效率、适应性等;5) 包含30个开放式任务的测试集,用于评估不同LLM智能体的性能。
关键创新:Collab-Overcooked的关键创新在于:1) 提出了一个专门用于评估LLM在协作环境中多智能体系统能力的基准测试;2) 引入了面向过程的评估指标,能够更细粒度地评估LLM智能体的协作能力;3) 通过自然语言交流,鼓励智能体之间的协作,使其更接近真实世界的协作场景。与现有方法相比,Collab-Overcooked更关注LLM在复杂交互环境中的协作能力。
关键设计:Collab-Overcooked的关键设计包括:1) 任务设计:设计了30个开放式任务,涵盖了不同的协作场景和难度级别;2) 评估指标:设计了面向过程的评估指标,包括沟通效率、适应性、目标对齐等;3) LLM选择:选择了13个流行的LLM进行实验,涵盖了不同规模和架构的模型;4) 实验设置:设计了不同的实验设置,例如不同的智能体数量、不同的任务目标等,以评估LLM在不同场景下的性能。
🖼️ 关键图片

📊 实验亮点
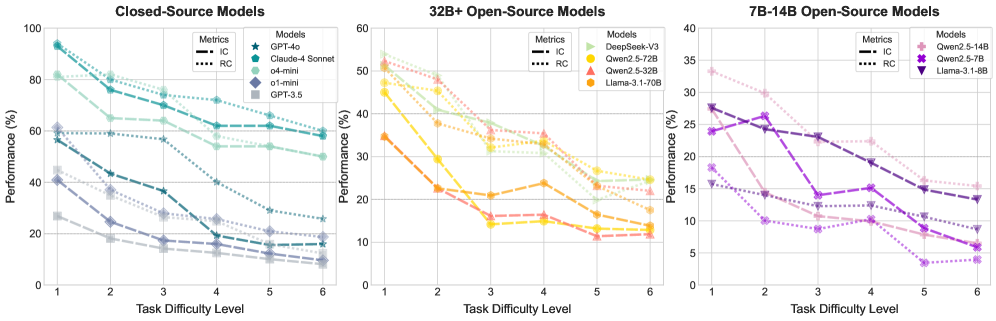
实验结果表明,虽然LLM在目标理解方面表现出强大的能力,但在主动协作和持续适应方面存在显著的不足。例如,某些LLM在沟通效率方面表现较差,无法有效地与其他智能体进行交流。此外,LLM在面对突发情况时,往往难以快速适应并调整策略。该研究强调了LLM-MAS的优势和劣势,并为改进和评估LLM-MAS提供了有价值的见解。
🎯 应用场景
该研究成果可应用于开发更智能、更协作的AI智能体,例如在机器人协作、自动驾驶、智能家居等领域。通过Collab-Overcooked基准测试,可以更好地评估和改进LLM在复杂协作环境中的能力,从而推动多智能体系统的发展,并最终实现更高效、更智能的人机协作。
📄 摘要(原文)
Large Language Models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-based Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks in two novel ways. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments with 13 popular LLMs and show that, while the LLMs exhibit a strong ability in goal interpretation, there are significant shortcomings in active collaboration and continuous adaptation, which are critical for efficiently fulfilling complex tasks. Notably, we highlight the strengths and weaknesses of LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-source benchmark. The environments, 30 open-ended tasks, and the evaluation package are publicly available at https://github.com/YusaeMeow/Collab-Overcooked.