Erasing Without Remembering: Implicit Knowledge Forgetting in Large Language Models
作者: Huazheng Wang, Yongcheng Jing, Haifeng Sun, Yingjie Wang, Jingyu Wang, Jianxin Liao, Dacheng Tao
分类: cs.CL, cs.LG
发布日期: 2025-02-27 (更新: 2025-10-09)
🔗 代码/项目: GITHUB
💡 一句话要点
提出PerMU,通过概率扰动实现大语言模型中更广义的隐式知识遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识遗忘 大语言模型 概率扰动 隐式知识 对抗学习
📋 核心要点
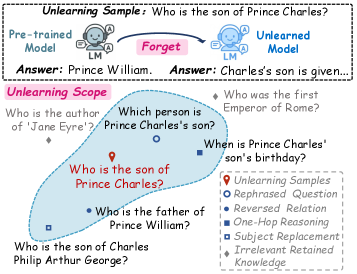
- 现有大语言模型遗忘方法难以泛化,无法彻底删除与目标数据相关的隐式知识,如释义或推理。
- PerMU通过概率扰动模拟对抗性遗忘样本,降低与事实相关的token概率,从而实现更广义的知识遗忘。
- 实验结果表明,PerMU在遗忘目标数据和隐式知识方面均有显著提升,最高分别达50.40%和40.73%。
📝 摘要(中文)
本文研究大语言模型中的知识遗忘,重点关注其泛化能力,确保模型不仅遗忘特定的训练样本,还能遗忘相关的隐式知识。为此,我们首先确定了一个更广泛的遗忘范围,包括目标数据和逻辑上相关的样本,如释义、主体替换、关系反转和单跳推理数据。然后,我们对三种数据集上的15种最先进的方法进行了严格评估,发现未学习的模型仍然可以回忆释义的答案,并在其中间层保留目标事实。这促使我们朝着更广义的隐式知识遗忘迈出初步一步,提出了PerMU,一种新颖的基于概率扰动的遗忘范式。PerMU模拟对抗性遗忘样本,以消除logit分布中与事实相关的token,从而集体降低所有答案相关token的概率。在包括TOFU、Harry Potter、ZsRE、WMDP和MUSE在内的各种数据集上,使用规模从1.3B到13B的模型进行了实验。结果表明,PerMU在遗忘原始目标数据方面提高了高达50.40%,同时在遗忘隐式知识方面提高了40.73%。
🔬 方法详解
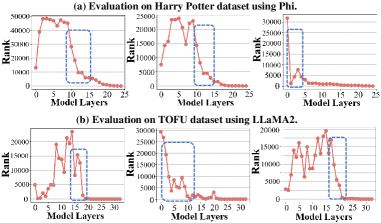
问题定义:现有的大语言模型遗忘方法主要集中在遗忘特定的训练样本,而忽略了与这些样本相关的隐式知识,例如对同一事实的不同表达方式(释义)、基于该事实的简单推理等。这意味着即使模型忘记了原始数据,仍然可能通过其他方式回忆起相关信息,导致遗忘效果不彻底。现有方法的痛点在于缺乏对隐式知识的有效处理,使得模型遗忘能力受限。
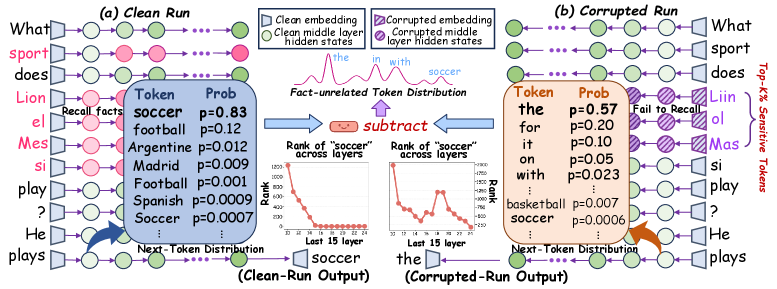
核心思路:PerMU的核心思路是通过概率扰动来模拟对抗性遗忘样本,从而消除logit分布中与事实相关的token。具体来说,PerMU不是直接修改模型的参数,而是通过调整模型输出的概率分布,降低所有与答案相关的token的概率。这样做的目的是让模型在预测时,即使遇到与已遗忘事实相关的输入,也不太可能给出正确的答案,从而实现更彻底的知识遗忘。
技术框架:PerMU的整体框架主要包含以下几个阶段:1) 确定遗忘范围:不仅包括目标数据,还包括释义、主体替换、关系反转和单跳推理等逻辑相关的样本。2) 生成对抗性遗忘样本:通过概率扰动模拟对抗性样本,旨在消除与事实相关的token。3) 概率扰动:调整模型的logit分布,降低与答案相关的token的概率。4) 评估遗忘效果:在目标数据和相关隐式知识上评估模型的遗忘效果。
关键创新:PerMU最重要的技术创新点在于其基于概率扰动的遗忘范式。与传统的参数修改方法不同,PerMU直接作用于模型的输出概率分布,通过降低与事实相关的token的概率来实现知识遗忘。这种方法更加灵活,可以有效地处理隐式知识,并且对模型的参数影响较小,从而更好地保持模型的通用能力。
关键设计:PerMU的关键设计在于如何有效地进行概率扰动。具体来说,PerMU通过模拟对抗性样本,识别出与事实相关的token,并降低这些token在logit分布中的概率。这种概率降低的程度可以通过超参数进行控制,以平衡遗忘效果和模型性能。此外,PerMU还采用了多种策略来生成对抗性样本,例如使用不同的释义方法、替换实体等,以确保遗忘的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PerMU在多个数据集上均取得了显著的遗忘效果提升。在遗忘原始目标数据方面,PerMU相比现有方法提高了高达50.40%。更重要的是,PerMU在遗忘隐式知识方面也表现出色,提升幅度达到40.73%。这些结果表明,PerMU能够更彻底地删除模型中的知识,并且具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于需要保护用户隐私、防止模型泄露敏感信息的场景,例如医疗、金融等领域。通过更彻底的知识遗忘,可以有效避免模型在未经授权的情况下泄露用户数据或敏感知识,提高模型的安全性和可靠性。此外,该技术还可以用于模型的持续学习和知识更新,帮助模型更好地适应新的环境和任务。
📄 摘要(原文)
In this paper, we investigate knowledge forgetting in large language models with a focus on its generalisation, ensuring that models forget not only specific training samples but also related implicit knowledge. To this end, we begin by identifying a broader unlearning scope that includes both target data and logically associated samples, including rephrased, subject-replaced, relation-reversed, and one-hop reasoned data. We then conduct a rigorous evaluation of 15 state-of-the-art methods across three datasets, revealing that unlearned models still recall paraphrased answers and retain target facts in their intermediate layers. This motivates us to take a preliminary step toward more generalised implicit knowledge forgetting by proposing PerMU, a novel probability perturbation-based unlearning paradigm. PerMU simulates adversarial unlearning samples to eliminate fact-related tokens from the logit distribution, collectively reducing the probabilities of all answer-associated tokens. Experiments are conducted on a diverse range of datasets, including TOFU, Harry Potter, ZsRE, WMDP, and MUSE, using models ranging from 1.3B to 13B in scale. The results demonstrate that PerMU delivers up to a 50.40% improvement in unlearning vanilla target data while maintaining a 40.73% boost in forgetting implicit knowledge. Our code can be found in https://github.com/MaybeLizzy/PERMU.