Medical Hallucinations in Foundation Models and Their Impact on Healthcare
作者: Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, Rodrigo Gameiro, Lizhou Fan, Eugene Park, Tristan Lin, Joonsik Yoon, Wonjin Yoon, Maarten Sap, Yulia Tsvetkov, Paul Liang, Xuhai Xu, Xin Liu, Chunjong Park, Hyeonhoon Lee, Hae Won Park, Daniel McDuff, Samir Tulebaev, Cynthia Breazeal
分类: cs.CL, cs.AI, cs.CY
发布日期: 2025-02-26 (更新: 2025-11-02)
💡 一句话要点
揭示医学领域大模型幻觉问题:通用模型优于专用模型,CoT推理显著缓解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学幻觉 大型语言模型 思维链提示 临床决策 医学人工智能
📋 核心要点
- 现有医学专用大模型在临床决策中存在幻觉问题,可能导致错误的诊断和治疗方案。
- 研究表明,通用大模型在医学任务中幻觉更少,思维链提示(CoT)能有效减少幻觉。
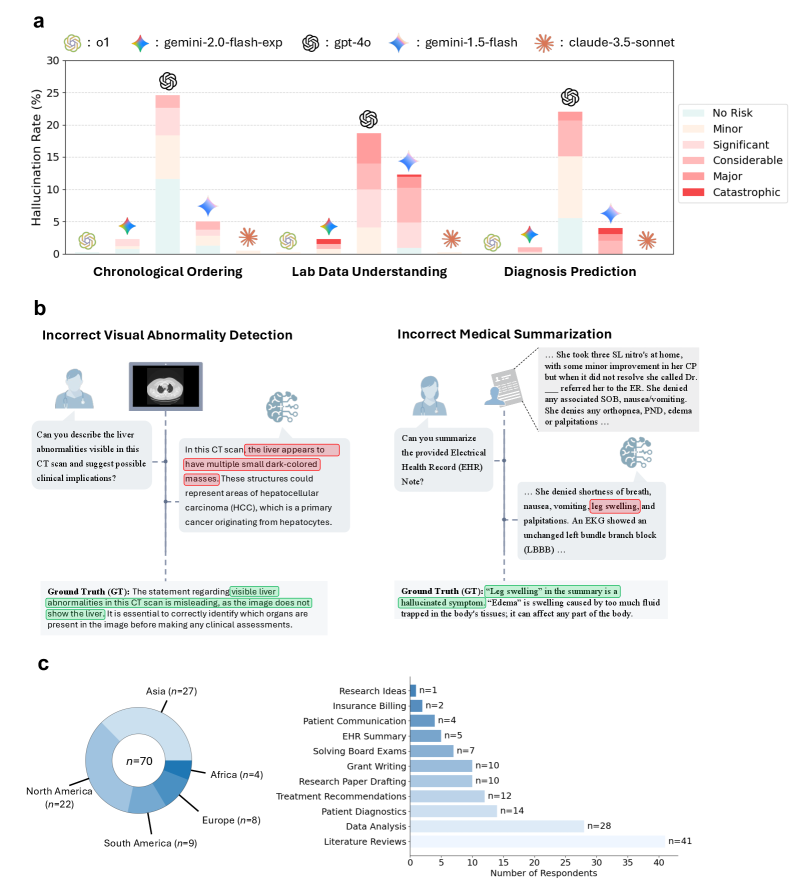
- 医生调查显示,医学幻觉普遍存在且可能危害患者,推理能力是解决幻觉的关键。
📝 摘要(中文)
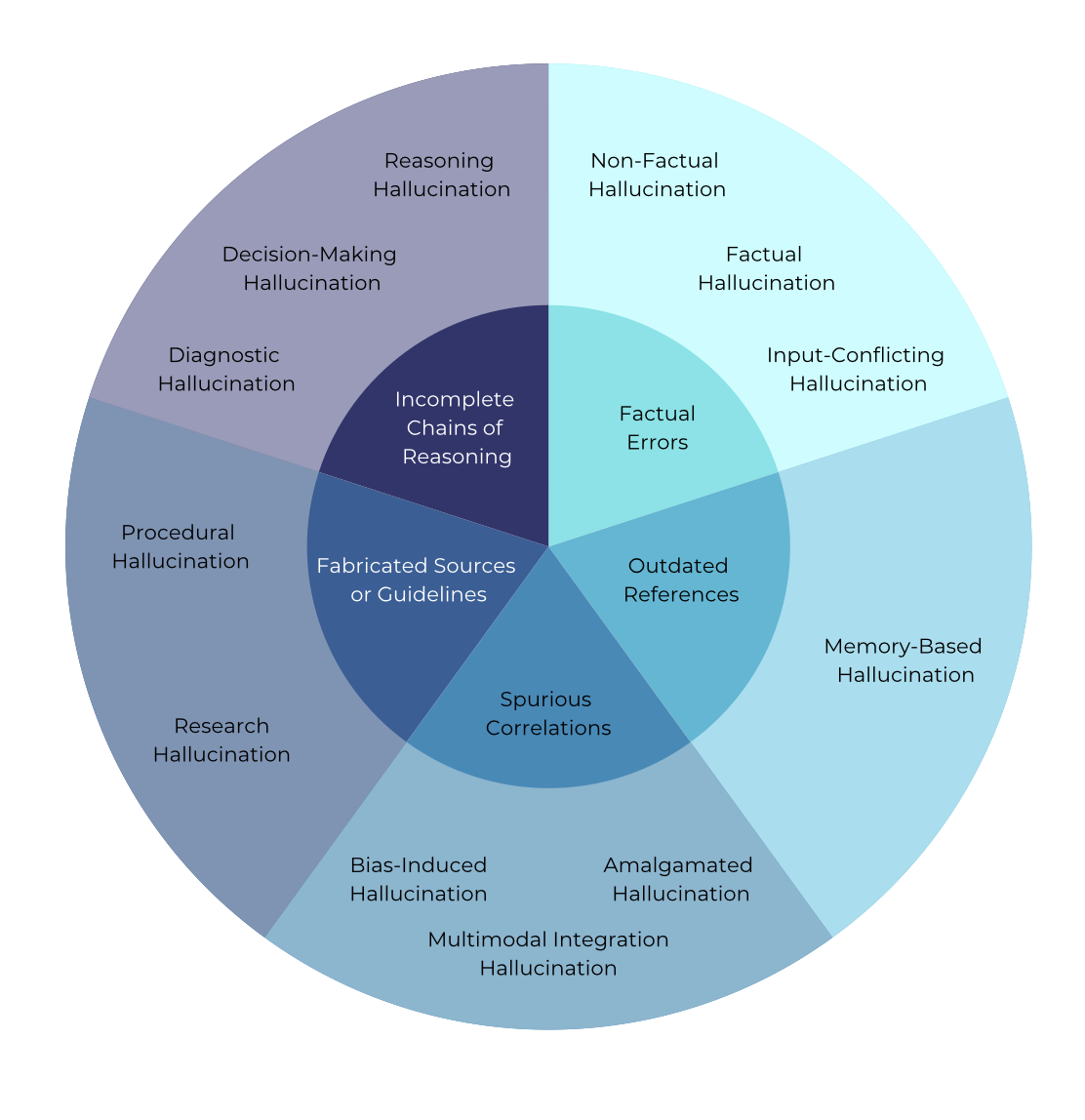
大型语言模型中的幻觉源于自回归训练目标,该目标优先考虑token似然优化而非认知准确性,从而导致过度自信和校准不良的不确定性。本文将医学幻觉定义为模型生成的任何在事实上不正确、逻辑上不一致或缺乏权威临床证据支持,并可能改变临床决策的输出。研究评估了11个基础模型(7个通用模型,4个医学专用模型)在七个医学幻觉任务中的表现,涵盖医学推理和生物医学信息检索。通用模型的无幻觉响应比例显著高于医学专用模型(中位数:76.6% vs 51.3%)。通过思维链提示增强后,Gemini-2.5 Pro等表现最佳的模型准确率超过97%(基础:87.6%),而MedGemma等医学专用模型的准确率仅为28.6-61.9%。思维链推理在经过FDR校正后显著减少了86.4%的测试比较中的幻觉。医生审核证实,64-72%的残余幻觉源于因果或时间推理失败,而非知识差距。一项针对临床医生的全球调查(n = 70)验证了实际影响:91.8%的人遇到过医学幻觉,84.7%的人认为它们可能对患者造成伤害。医学专用模型尽管经过领域训练,但表现不佳,这表明安全性源于大规模预训练期间发展出的复杂推理能力和广泛知识整合,而非狭隘的优化。
🔬 方法详解
问题定义:论文旨在解决医学领域大型语言模型(LLM)中存在的“医学幻觉”问题。医学幻觉指的是模型生成的在医学事实上不正确、逻辑上不一致或缺乏临床证据支持,并可能导致错误临床决策的输出。现有医学专用模型虽然经过医学知识训练,但仍然存在较高的幻觉率,这限制了它们在临床实践中的应用。
核心思路:论文的核心思路是评估不同类型(通用和医学专用)的LLM在医学任务中的幻觉程度,并探究减少幻觉的方法。研究假设,通用模型通过大规模预训练获得的更广泛的知识和更强的推理能力可能使其在医学任务中表现更好。此外,研究还探索了思维链(Chain-of-Thought, CoT)提示方法在减少幻觉方面的作用。
技术框架:研究的技术框架主要包括以下几个部分: 1. 模型选择:选择了11个基础模型,包括7个通用模型和4个医学专用模型。 2. 任务设计:设计了7个医学幻觉任务,涵盖医学推理和生物医学信息检索。 3. 评估指标:使用准确率和无幻觉响应比例等指标评估模型的性能。 4. 思维链提示:使用CoT提示方法增强模型的推理能力。 5. 医生审核:邀请医生对模型的输出进行审核,分析残余幻觉的原因。 6. 临床医生调查:进行全球临床医生调查,了解医学幻觉的实际影响。
关键创新:论文的关键创新点在于: 1. 对比了通用模型和医学专用模型在医学任务中的幻觉程度,发现通用模型表现更好。 2. 验证了思维链提示(CoT)在减少医学幻觉方面的有效性。 3. 通过医生审核和临床医生调查,揭示了医学幻觉的实际影响和潜在危害。
关键设计: 1. 思维链提示(CoT):通过在提示中加入“让我们一步一步思考”等引导语,鼓励模型生成推理过程,从而提高准确率并减少幻觉。 2. 任务选择:选择了涵盖不同医学领域的任务,以评估模型在不同场景下的表现。 3. 统计分析:使用了Mann-Whitney U检验和FDR校正等统计方法,以确保结果的可靠性。
🖼️ 关键图片

📊 实验亮点
研究发现,通用模型在医学任务中的无幻觉响应比例显著高于医学专用模型(76.6% vs 51.3%)。通过思维链提示(CoT)增强后,Gemini-2.5 Pro的准确率超过97%(基础:87.6%)。思维链推理在86.4%的测试比较中显著减少了幻觉。医生审核表明,64-72%的残余幻觉源于因果或时间推理失败。
🎯 应用场景
该研究成果可应用于改进医学人工智能系统的安全性,减少临床决策中的错误。通过优化模型架构和推理方法,降低医学幻觉的发生率,提高医疗诊断和治疗的准确性。未来,可将该研究应用于开发更可靠的智能医疗助手,辅助医生进行决策,提升患者的医疗服务质量。
📄 摘要(原文)
Hallucinations in foundation models arise from autoregressive training objectives that prioritize token-likelihood optimization over epistemic accuracy, fostering overconfidence and poorly calibrated uncertainty. We define medical hallucination as any model-generated output that is factually incorrect, logically inconsistent, or unsupported by authoritative clinical evidence in ways that could alter clinical decisions. We evaluated 11 foundation models (7 general-purpose, 4 medical-specialized) across seven medical hallucination tasks spanning medical reasoning and biomedical information retrieval. General-purpose models achieved significantly higher proportions of hallucination-free responses than medical-specialized models (median: 76.6% vs 51.3%, difference = 25.2%, 95% CI: 18.7-31.3%, Mann-Whitney U = 27.0, p = 0.012, rank-biserial r = -0.64). Top-performing models such as Gemini-2.5 Pro exceeded 97% accuracy when augmented with chain-of-thought prompting (base: 87.6%), while medical-specialized models like MedGemma ranged from 28.6-61.9% despite explicit training on medical corpora. Chain-of-thought reasoning significantly reduced hallucinations in 86.4% of tested comparisons after FDR correction (q < 0.05), demonstrating that explicit reasoning traces enable self-verification and error detection. Physician audits confirmed that 64-72% of residual hallucinations stemmed from causal or temporal reasoning failures rather than knowledge gaps. A global survey of clinicians (n = 70) validated real-world impact: 91.8% had encountered medical hallucinations, and 84.7% considered them capable of causing patient harm. The underperformance of medical-specialized models despite domain training indicates that safety emerges from sophisticated reasoning capabilities and broad knowledge integration developed during large-scale pre-training, not from narrow optimization.