Do Large Language Models Know How Much They Know?
作者: Gabriele Prato, Jerry Huang, Prasanna Parthasarathi, Shagun Sodhani, Sarath Chandar
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-26 (更新: 2025-10-24)
备注: Published as a long paper at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). Official version of paper within conference proceedings is available at https://aclanthology.org/2024.emnlp-main.348/
💡 一句话要点
评估大型语言模型知识范围:提出基准测试模型认知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识认知 基准测试 模型评估 认知能力
📋 核心要点
- 现有大型语言模型的能力边界尚不清晰,缺乏对其知识范围的有效评估方法。
- 论文提出一种基准测试,通过考察模型能否准确枚举其拥有的关于特定主题的所有信息,来评估其知识认知能力。
- 实验结果表明,达到一定规模的LLMs展现出对自身知识量的理解,暗示知识认知可能是LLMs的通用属性。
📝 摘要(中文)
大型语言模型(LLMs)已成为功能强大的系统,并日益融入各种应用。然而,其快速部署的速度超过了对其内部机制的全面理解以及对其能力和局限性的界定。智能系统的一个理想属性是能够识别自身知识的范围。为了研究LLMs是否具有这一特性,我们开发了一个基准,旨在挑战这些模型枚举它们所拥有的关于特定主题的所有信息。该基准评估模型是否回忆了过多、不足或精确数量的信息,从而表明它们对自身知识的认知。我们的研究结果表明,所有经过测试的LLMs,在达到足够的规模后,都表现出对它们对特定主题了解多少的理解。虽然不同的架构表现出不同的这种能力出现的速度,但结果表明,对知识的认知可能是LLMs的一个普遍属性。需要进一步的研究来证实这种潜力并充分阐明其潜在机制。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的知识认知问题,即LLMs是否知道自己知道多少。现有方法缺乏有效的评估手段,无法准确衡量LLMs对自身知识范围的认知程度。这使得我们难以信任LLMs在实际应用中的表现,尤其是在需要精确知识的场景下。
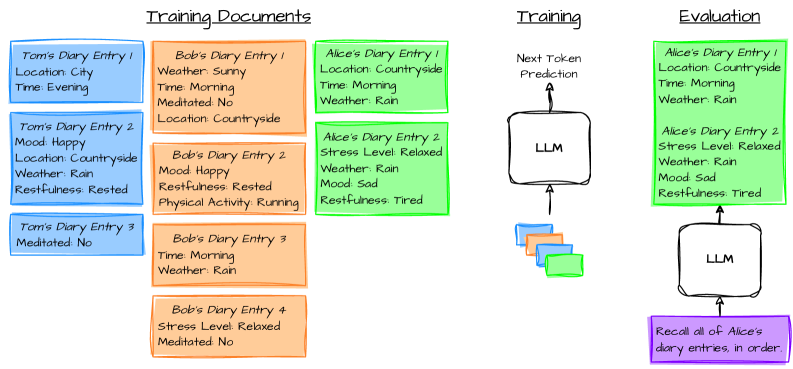
核心思路:论文的核心思路是设计一个基准测试,通过要求LLMs枚举其拥有的关于特定主题的所有信息,来评估其知识认知能力。如果LLM能够准确地回忆起所有相关信息,而不会遗漏或添加不相关的信息,则可以认为它具有较好的知识认知能力。这种方法类似于评估人类对自身知识的认知程度。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择一系列主题作为测试对象;2) 设计提示语,要求LLMs枚举其拥有的关于每个主题的所有信息;3) 评估LLMs的回忆结果,判断其回忆的信息量是否过多、不足或精确;4) 分析不同规模和架构的LLMs在基准测试中的表现,从而得出关于LLMs知识认知能力的结论。
关键创新:该研究的关键创新在于提出了一种新的基准测试方法,用于评估LLMs的知识认知能力。与以往的研究不同,该方法侧重于考察LLMs能否准确地枚举其拥有的知识,而不仅仅是评估其知识的准确性或完整性。这种方法能够更全面地了解LLMs的知识水平和局限性。
关键设计:基准测试的关键设计包括:1) 主题的选择需要具有代表性,涵盖不同领域和难度;2) 提示语的设计需要清晰明确,避免歧义;3) 评估指标的设计需要能够准确地衡量LLMs的回忆结果,例如可以使用精确率、召回率和F1值等指标。
🖼️ 关键图片
📊 实验亮点
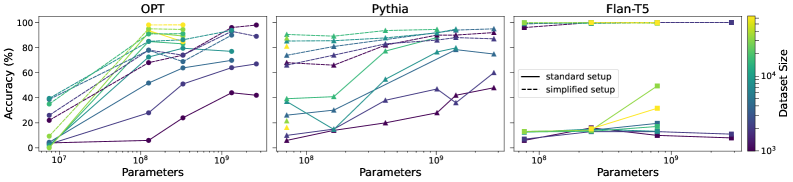
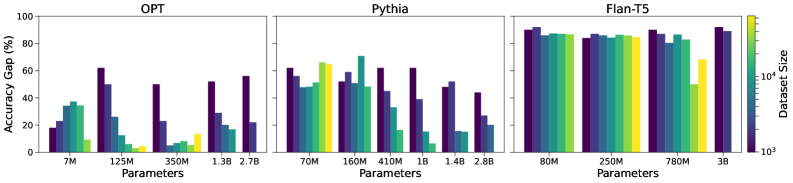
实验结果表明,达到一定规模的LLMs展现出对自身知识量的理解。不同架构的模型表现出不同的能力涌现速度,但整体趋势表明,知识认知能力是LLMs的一个普遍属性。这一发现为进一步研究LLMs的认知能力和提升其可靠性提供了重要依据。具体性能数据和对比基线在论文中未明确给出,需要查阅原文。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可信度和可靠性。通过评估模型的知识认知能力,可以更好地了解模型的优势和局限性,从而在实际应用中做出更明智的决策。例如,在医疗诊断、法律咨询等领域,需要模型具备准确的知识和清晰的认知,以避免误导用户。此外,该研究还可以促进对LLMs内部机制的理解,为未来的模型设计和训练提供指导。
📄 摘要(原文)
Large Language Models (LLMs) have emerged as highly capable systems and are increasingly being integrated into various uses. However, the rapid pace of their deployment has outpaced a comprehensive understanding of their internal mechanisms and a delineation of their capabilities and limitations. A desired attribute of an intelligent system is its ability to recognize the scope of its own knowledge. To investigate whether LLMs embody this characteristic, we develop a benchmark designed to challenge these models to enumerate all information they possess on specific topics. This benchmark evaluates whether the models recall excessive, insufficient, or the precise amount of information, thereby indicating their awareness of their own knowledge. Our findings reveal that all tested LLMs, given sufficient scale, demonstrate an understanding of how much they know about specific topics. While different architectures exhibit varying rates of this capability's emergence, the results suggest that awareness of knowledge may be a generalizable attribute of LLMs. Further research is needed to confirm this potential and fully elucidate the underlying mechanisms.