Norm Growth and Stability Challenges in Localized Sequential Knowledge Editing
作者: Akshat Gupta, Christine Fang, Atahan Ozdemir, Maochuan Lu, Ahmed Alaa, Thomas Hartvigsen, Gopala Anumanchipalli
分类: cs.CL, cs.AI
发布日期: 2025-02-26
备注: Accepted for Oral Presentation at KnowFM @ AAAI 2025. arXiv admin note: text overlap with arXiv:2502.01636
💡 一句话要点
研究揭示LLM局部知识编辑中范数增长与稳定性挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 大型语言模型 范数增长 模型稳定性 局部更新
📋 核心要点
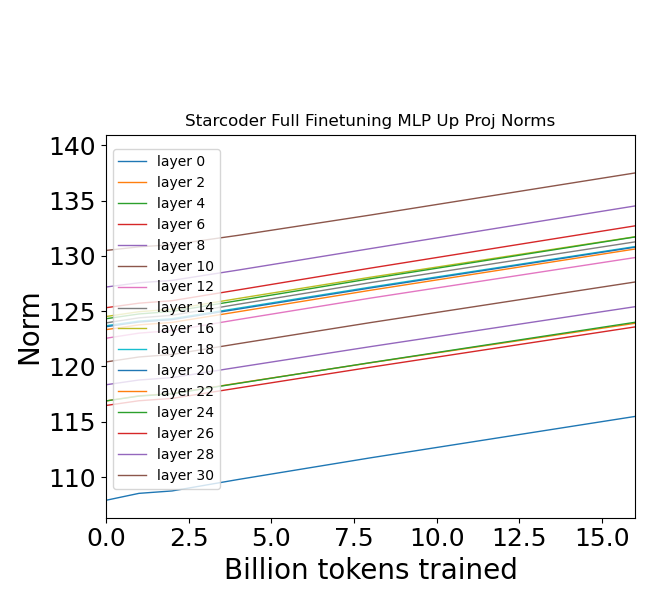
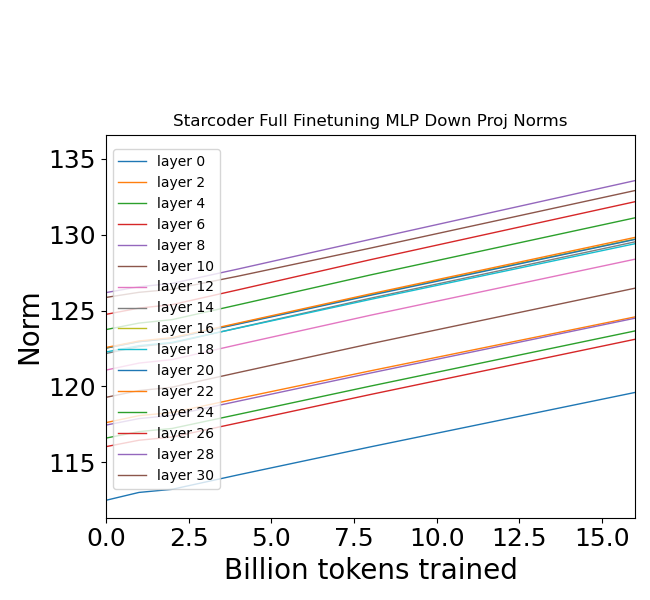
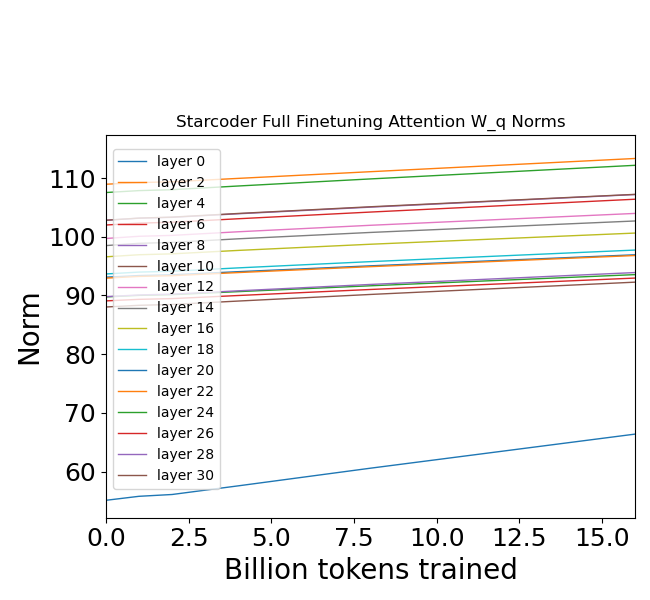
- 现有知识编辑方法在局部更新LLM时,存在更新矩阵范数持续增长的问题,导致模型不稳定。
- 论文通过分析中间激活向量,发现激活范数减小且子空间发生偏移,揭示了模型内部表示的变化。
- 研究表明,连续局部知识编辑会影响模型稳定性与效用,为后续研究提供了重要的技术挑战。
📝 摘要(中文)
本研究调查了对大型语言模型(LLM)进行局部更新的影响,特别是在知识编辑的背景下——该任务旨在整合或修改特定事实,而不改变更广泛的模型能力。我们首先表明,在不同的后训练干预(如连续预训练、完全微调和基于LORA的微调)中,更新矩阵的Frobenius范数总是增加。这种增长的范数对于局部知识编辑尤其不利,因为只有模型中的一部分矩阵被更新。我们揭示了各种编辑技术(包括微调、基于超网络的方法和定位-编辑方法)中一个一致的现象:更新矩阵的范数随着连续更新而不可避免地增加。这种增长扰乱了模型平衡,特别是当孤立的矩阵被更新而模型的其余部分保持静态时,导致潜在的不稳定性和下游性能的下降。通过对中间激活向量的深入研究,我们发现内部激活的范数减小,并且伴随着这些激活所占据的子空间的移动,这表明这些激活向量现在占据了与未编辑模型完全不同的表示空间区域。通过我们的论文,我们强调了连续和局部顺序知识编辑的技术挑战及其对维持模型稳定性和效用的影响。
🔬 方法详解
问题定义:论文关注的是大型语言模型(LLM)的知识编辑问题,即如何在不影响模型整体性能的前提下,修改或添加特定的知识。现有的知识编辑方法,特别是局部知识编辑方法,在进行连续的知识更新时,会导致模型参数(尤其是更新矩阵)的范数不断增长,从而破坏模型的平衡和稳定性。这种范数增长会使得模型在下游任务上的表现下降,并且难以维护模型的知识一致性。
核心思路:论文的核心思路是揭示局部知识编辑过程中范数增长的现象,并分析其对模型内部表示和稳定性的影响。通过实验观察和理论分析,论文发现更新矩阵的范数随着连续更新而增加,同时中间激活向量的范数减小,并且激活向量所占据的子空间发生偏移。这些现象表明,局部知识编辑会显著改变模型的内部表示,从而导致模型不稳定。
技术框架:论文的研究框架主要包括以下几个部分:1) 实验设置:选择不同的LLM模型和知识编辑方法(如微调、LORA、超网络等),进行连续的局部知识编辑。2) 范数分析:测量更新矩阵的Frobenius范数,观察其随更新次数的变化趋势。3) 激活分析:提取模型中间层的激活向量,计算其范数,并分析其所占据的子空间的变化。4) 性能评估:在下游任务上评估模型的性能,观察其随更新次数的变化。
关键创新:论文的关键创新在于揭示了局部知识编辑中范数增长的普遍性及其对模型稳定性的影响。以往的研究主要关注知识编辑的准确性和效率,而忽略了模型内部表示的变化和稳定性问题。论文通过实验和分析,证明了范数增长是各种知识编辑方法中普遍存在的现象,并且会导致模型性能下降。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM模型和知识编辑方法,以保证研究结果的普适性。2) 使用Frobenius范数作为衡量矩阵大小的指标,能够有效地反映矩阵的整体变化。3) 通过分析中间激活向量的范数和子空间变化,深入了解模型内部表示的变化。4) 在多个下游任务上评估模型性能,以全面评估知识编辑对模型的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,无论采用何种知识编辑方法(微调、LORA、超网络),更新矩阵的Frobenius范数都随着连续更新而增加。同时,中间激活向量的范数减小,且激活向量所占据的子空间发生显著偏移。这些变化导致模型在下游任务上的性能下降,验证了范数增长对模型稳定性的负面影响。
🎯 应用场景
该研究成果对知识密集型应用具有重要意义,例如智能客服、问答系统和信息检索。通过理解局部知识编辑带来的模型稳定性问题,可以开发更可靠、可控的知识更新策略,提升LLM在实际应用中的性能和用户体验。未来的研究可以探索如何缓解范数增长,从而实现更安全、高效的知识编辑。
📄 摘要(原文)
This study investigates the impact of localized updates to large language models (LLMs), specifically in the context of knowledge editing - a task aimed at incorporating or modifying specific facts without altering broader model capabilities. We first show that across different post-training interventions like continuous pre-training, full fine-tuning and LORA-based fine-tuning, the Frobenius norm of the updated matrices always increases. This increasing norm is especially detrimental for localized knowledge editing, where only a subset of matrices are updated in a model . We reveal a consistent phenomenon across various editing techniques, including fine-tuning, hypernetwork-based approaches, and locate-and-edit methods: the norm of the updated matrix invariably increases with successive updates. Such growth disrupts model balance, particularly when isolated matrices are updated while the rest of the model remains static, leading to potential instability and degradation of downstream performance. Upon deeper investigations of the intermediate activation vectors, we find that the norm of internal activations decreases and is accompanied by shifts in the subspaces occupied by these activations, which shows that these activation vectors now occupy completely different regions in the representation space compared to the unedited model. With our paper, we highlight the technical challenges with continuous and localized sequential knowledge editing and their implications for maintaining model stability and utility.