DataMan: Data Manager for Pre-training Large Language Models
作者: Ru Peng, Kexin Yang, Yawen Zeng, Junyang Lin, Dayiheng Liu, Junbo Zhao
分类: cs.CL, cs.AI
发布日期: 2025-02-26 (更新: 2025-04-08)
备注: ICLR2025 paper
💡 一句话要点
DataMan:用于预训练大型语言模型的数据管理器,提升数据质量与领域混合。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据 数据质量评估 领域混合 逆向思维
📋 核心要点
- 现有LLM预训练数据选择依赖启发式方法和人工,缺乏系统性指导,影响模型性能。
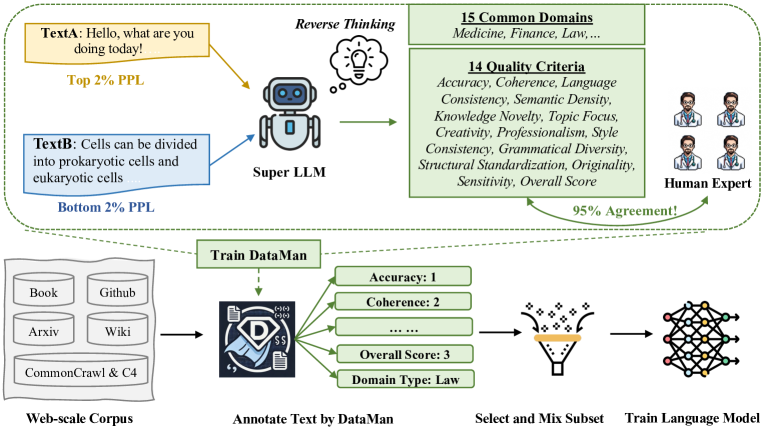
- DataMan通过逆向思维,让LLM自我评估数据质量标准,并学习对数据进行质量和领域标注。
- 实验证明,DataMan选择的数据训练的模型,在ICL、困惑度和指令遵循方面显著优于基线模型。
📝 摘要(中文)
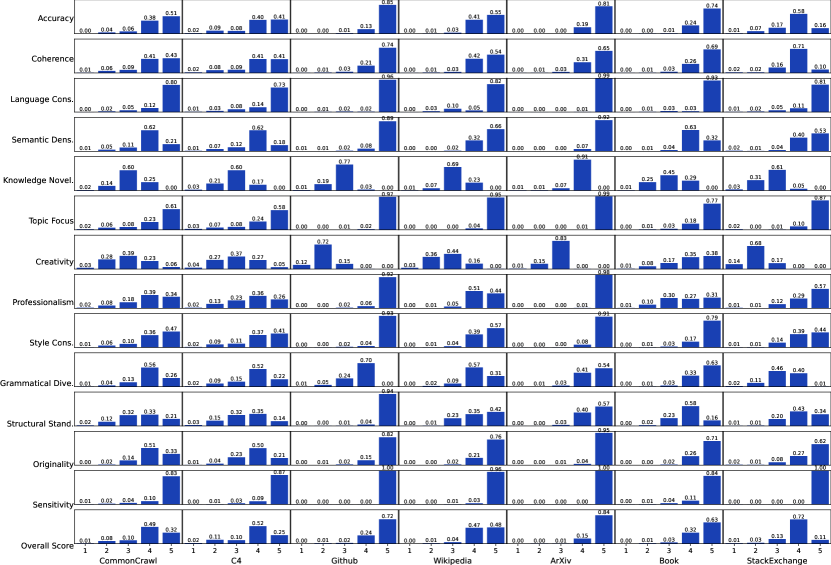
本文提出了一种名为DataMan的数据管理器,旨在解决大型语言模型(LLM)预训练数据选择的问题。现有方法依赖于有限的启发式方法和人类直觉,缺乏全面的指导。DataMan受到“逆向思维”的启发,通过提示LLM自我识别哪些标准有利于其性能。基于文本困惑度(PPL)的原因,推导出14个质量标准,并引入15个常见应用领域以支持领域混合。DataMan通过点式评分学习质量评级和领域识别,并使用它来注释一个包含4470亿token的预训练语料库,标注14个质量评级和领域类型。实验表明,使用DataMan选择的300亿token训练的13亿参数语言模型,在上下文学习(ICL)、困惑度和指令遵循能力方面,均优于最先进的基线模型。最佳模型基于总体得分l=5,性能超过了使用均匀采样训练的、数据量多50%的模型。通过使用DataMan标注的高质量、特定领域数据进行持续预训练,增强了特定领域的ICL性能,验证了DataMan的领域混合能力。研究结果强调了质量排序的重要性、质量标准的互补性以及它们与困惑度之间的低相关性,并分析了PPL和ICL性能之间的不一致性。此外,还深入分析了预训练数据集的组成、质量评级的分布以及原始文档来源。
🔬 方法详解
问题定义:现有大型语言模型预训练数据选择方法主要依赖于人工经验和启发式规则,缺乏系统性的数据质量评估和领域选择机制。这导致预训练数据质量参差不齐,领域分布不均衡,最终影响模型的性能和泛化能力。现有方法难以充分利用数据缩放定律带来的优势,无法有效提升模型的上下文学习能力和指令遵循能力。
核心思路:DataMan的核心思路是利用大型语言模型自身的知识和能力,通过“逆向思维”的方式,让模型自我评估哪些数据特征和领域分布对其性能提升有益。具体而言,DataMan首先基于困惑度(PPL)异常的原因,推导出14个数据质量标准,并引入15个常见应用领域。然后,DataMan学习对数据进行质量评级和领域识别,从而实现对预训练数据的精细化管理和选择。
技术框架:DataMan的整体框架包括以下几个主要模块:1) 质量标准和领域定义:基于困惑度分析和领域知识,定义14个质量标准和15个应用领域。2) 数据标注:使用DataMan模型对大规模预训练语料库进行质量评级和领域标注。3) 数据选择:根据质量评级和领域分布,选择高质量、领域相关的数据进行预训练。4) 模型训练:使用选择的数据训练大型语言模型。5) 性能评估:评估模型在上下文学习、困惑度和指令遵循等方面的性能。
关键创新:DataMan的关键创新在于:1) 逆向思维的数据选择方法:利用LLM自身的能力评估数据质量,避免了人工经验的局限性。2) 基于困惑度的质量标准:从模型学习的角度出发,定义了更具针对性的数据质量标准。3) 领域混合策略:通过领域识别和选择,实现了更有效的领域混合,提升了模型的泛化能力。
关键设计:DataMan的关键设计包括:1) 质量评级模型:使用一个神经网络模型学习对数据进行质量评级,损失函数采用点式评分损失。2) 领域识别模型:使用另一个神经网络模型学习对数据进行领域识别,损失函数采用交叉熵损失。3) 数据选择策略:根据质量评级和领域分布,设计不同的数据选择策略,例如基于总体得分的选择、基于特定领域的选择等。
🖼️ 关键图片
📊 实验亮点
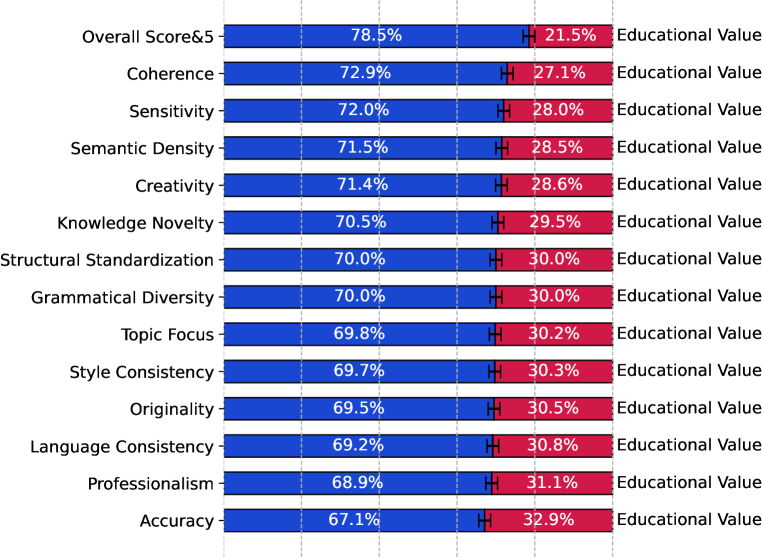
实验结果表明,使用DataMan选择的300亿token训练的13亿参数语言模型,在上下文学习(ICL)、困惑度和指令遵循能力方面,均优于最先进的基线模型。最佳模型基于总体得分l=5,性能超过了使用均匀采样训练的、数据量多50%的模型。通过使用DataMan标注的高质量、特定领域数据进行持续预训练,增强了特定领域的ICL性能,验证了DataMan的领域混合能力。
🎯 应用场景
DataMan可应用于各种需要大规模预训练语言模型的场景,例如智能客服、机器翻译、文本生成、代码生成等。通过DataMan,可以更有效地利用预训练数据,提升模型的性能和泛化能力,降低训练成本。未来,DataMan可以扩展到更多模态的数据管理,例如图像、音频、视频等,为多模态大模型的预训练提供支持。
📄 摘要(原文)
The performance emergence of large language models (LLMs) driven by data scaling laws makes the selection of pre-training data increasingly important. However, existing methods rely on limited heuristics and human intuition, lacking comprehensive and clear guidelines. To address this, we are inspired by ``reverse thinking'' -- prompting LLMs to self-identify which criteria benefit its performance. As its pre-training capabilities are related to perplexity (PPL), we derive 14 quality criteria from the causes of text perplexity anomalies and introduce 15 common application domains to support domain mixing. In this paper, we train a Data Manager (DataMan) to learn quality ratings and domain recognition from pointwise rating, and use it to annotate a 447B token pre-training corpus with 14 quality ratings and domain type. Our experiments validate our approach, using DataMan to select 30B tokens to train a 1.3B-parameter language model, demonstrating significant improvements in in-context learning (ICL), perplexity, and instruction-following ability over the state-of-the-art baseline. The best-performing model, based on the Overall Score l=5 surpasses a model trained with 50% more data using uniform sampling. We continue pre-training with high-rated, domain-specific data annotated by DataMan to enhance domain-specific ICL performance and thus verify DataMan's domain mixing ability. Our findings emphasize the importance of quality ranking, the complementary nature of quality criteria, and their low correlation with perplexity, analyzing misalignment between PPL and ICL performance. We also thoroughly analyzed our pre-training dataset, examining its composition, the distribution of quality ratings, and the original document sources.