Detecting Linguistic Indicators for Stereotype Assessment with Large Language Models
作者: Rebekka Görge, Michael Mock, Héctor Allende-Cid
分类: cs.CL, cs.AI
发布日期: 2025-02-26
💡 一句话要点
提出基于语言学指标的刻板印象评估方法,利用大语言模型检测文本中的刻板印象。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 刻板印象检测 语言学指标 大型语言模型 社会偏见 上下文学习
📋 核心要点
- 现有NLP方法在刻板印象检测方面缺乏客观性、精确性和可解释性,未能充分利用社会语言学研究的成果。
- 该论文提出一种新方法,通过检测和量化句子中刻板印象的语言学指标,实现细粒度的刻板印象评估。
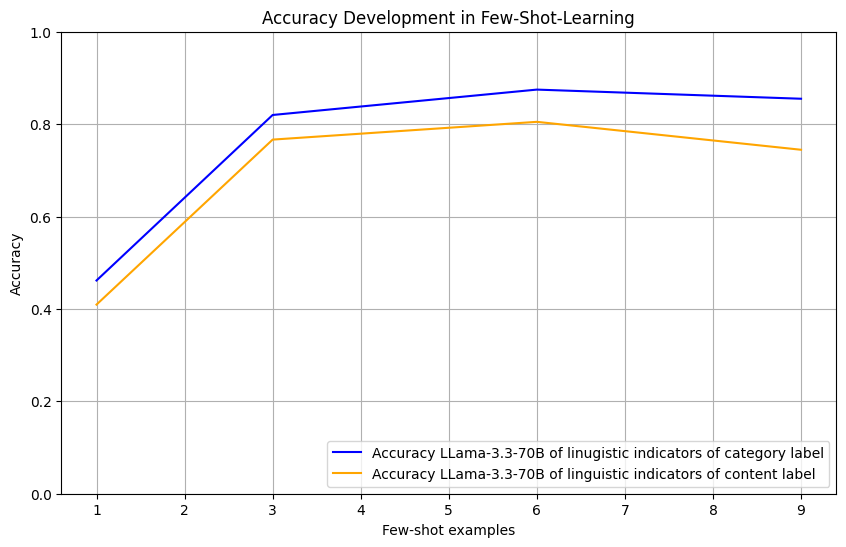
- 实验结果表明,该方法能够有效检测和分类刻板印象的语言学指标,并且模型性能随着模型规模的增加而提高。
📝 摘要(中文)
社会类别和刻板印象深植于语言中,可能导致大型语言模型(LLM)的数据偏差。尽管存在安全措施,这些偏差通常仍然存在于模型的行为中,可能导致输出中出现代表性损害。社会语言学研究为刻板印象的形成提供了宝贵的见解,但用于刻板印象检测的NLP方法很少借鉴这一基础,并且通常缺乏客观性、精确性和可解释性。为了填补这一空白,本文提出了一种新方法,用于检测和量化句子中刻板印象的语言学指标。我们从社会类别和刻板印象交流(SCSC)框架中提取语言学指标,这些指标表明语言中存在强烈的社会类别构建和刻板印象,并使用它们来构建分类方案。为了自动化这种方法,我们使用上下文学习来指导不同的LLM将该方法应用于句子,其中LLM检查语言学属性并为细粒度评估提供基础。基于对不同语言学指标重要性的实证评估,我们学习了一个评分函数,用于衡量刻板印象的语言学指标。我们对刻板印象句子的注释表明,这些指标存在于这些句子中,并解释了刻板印象的强度。在模型性能方面,我们的结果表明,这些模型通常在检测和分类用于表示类别的类别标签的语言学指标方面表现良好,但有时难以正确评估相关的行为和特征。在提示中使用更多的few-shot示例可以显著提高性能。模型性能随着规模的增加而提高,Llama-3.3-70B-Instruct和GPT-4取得了可比的结果,超过了Mixtral-8x7B-Instruct、GPT-4-mini和Llama-3.1-8B-Instruct。
🔬 方法详解
问题定义:现有刻板印象检测方法缺乏客观性、精确性和可解释性,未能充分利用社会语言学理论指导。这些方法难以准确识别文本中细微的刻板印象表达,并且难以解释刻板印象产生的原因。这导致模型在处理涉及社会偏见的任务时,容易产生不公平或歧视性的结果。
核心思路:该论文的核心思路是借鉴社会语言学中的社会类别和刻板印象交流(SCSC)框架,提取语言学指标,这些指标能够反映文本中强烈的社会类别构建和刻板印象。通过分析这些语言学指标,可以更客观、精确地评估文本中存在的刻板印象。
技术框架:该方法主要包含以下几个阶段:1) 从SCSC框架中提取语言学指标,构建分类方案;2) 使用上下文学习,指导大型语言模型(LLM)分析句子中的语言学属性;3) 基于LLM的分析结果,学习一个评分函数,用于衡量刻板印象的语言学指标;4) 使用注释的刻板印象句子,评估该方法的有效性。
关键创新:该方法最重要的创新点在于,它将社会语言学理论与自然语言处理技术相结合,提出了一种基于语言学指标的刻板印象评估方法。与现有方法相比,该方法更具客观性、精确性和可解释性,能够更有效地检测和量化文本中存在的刻板印象。
关键设计:该方法使用上下文学习(in-context learning)来指导LLM分析句子中的语言学属性。通过提供少量的示例(few-shot examples),LLM能够学习如何识别和分类不同的语言学指标。此外,该方法还学习了一个评分函数,用于衡量刻板印象的强度。该评分函数基于不同语言学指标的重要性进行加权,从而更准确地评估文本中存在的刻板印象。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够有效检测和分类刻板印象的语言学指标。通过在提示中使用更多的few-shot示例,可以显著提高模型性能。Llama-3.3-70B-Instruct和GPT-4取得了可比的结果,超过了Mixtral-8x7B-Instruct、GPT-4-mini和Llama-3.1-8B-Instruct,表明模型性能随着模型规模的增加而提高。
🎯 应用场景
该研究成果可应用于多个领域,例如:内容审核,用于检测和过滤包含刻板印象或偏见的内容;招聘系统,用于消除招聘广告中的性别或种族偏见;教育领域,用于提高学生对刻板印象的意识。该研究有助于构建更公平、更包容的语言模型和人工智能系统。
📄 摘要(原文)
Social categories and stereotypes are embedded in language and can introduce data bias into Large Language Models (LLMs). Despite safeguards, these biases often persist in model behavior, potentially leading to representational harm in outputs. While sociolinguistic research provides valuable insights into the formation of stereotypes, NLP approaches for stereotype detection rarely draw on this foundation and often lack objectivity, precision, and interpretability. To fill this gap, in this work we propose a new approach that detects and quantifies the linguistic indicators of stereotypes in a sentence. We derive linguistic indicators from the Social Category and Stereotype Communication (SCSC) framework which indicate strong social category formulation and stereotyping in language, and use them to build a categorization scheme. To automate this approach, we instruct different LLMs using in-context learning to apply the approach to a sentence, where the LLM examines the linguistic properties and provides a basis for a fine-grained assessment. Based on an empirical evaluation of the importance of different linguistic indicators, we learn a scoring function that measures the linguistic indicators of a stereotype. Our annotations of stereotyped sentences show that these indicators are present in these sentences and explain the strength of a stereotype. In terms of model performance, our results show that the models generally perform well in detecting and classifying linguistic indicators of category labels used to denote a category, but sometimes struggle to correctly evaluate the associated behaviors and characteristics. Using more few-shot examples within the prompts, significantly improves performance. Model performance increases with size, as Llama-3.3-70B-Instruct and GPT-4 achieve comparable results that surpass those of Mixtral-8x7B-Instruct, GPT-4-mini and Llama-3.1-8B-Instruct.