When Personalization Meets Reality: A Multi-Faceted Analysis of Personalized Preference Learning
作者: Yijiang River Dong, Tiancheng Hu, Yinhong Liu, Ahmet Üstün, Nigel Collier
分类: cs.CL, cs.AI
发布日期: 2025-02-26 (更新: 2025-10-27)
💡 一句话要点
提出多维度评估框架,分析个性化偏好学习在LLM中的有效性、公平性和安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化偏好学习 强化学习 人类反馈 大型语言模型 公平性 安全性 多维度评估 用户偏好
📋 核心要点
- 现有RLHF方法假设用户偏好一致,忽略了用户价值观的多样性,导致模型对齐效果不佳。
- 论文提出多维度评估框架,从性能、公平性、意外影响和适应性等方面综合评估个性化偏好学习。
- 实验表明,用户偏好差异大时,个性化方法性能差异显著,且可能引入安全问题,需谨慎评估。
📝 摘要(中文)
尽管基于人类反馈的强化学习(RLHF)被广泛用于使大型语言模型(LLM)与人类偏好对齐,但它通常假设用户偏好是同质的,忽略了多样化的人类价值观和少数群体的观点。个性化偏好学习通过为每个用户定制单独的偏好来解决这个问题,但该领域缺乏评估其有效性的标准化方法。本文提出了一个多方面的评估框架,不仅衡量性能,还衡量公平性、意外影响以及不同偏好差异程度下的适应性。通过广泛的实验,比较了三种偏好数据集上的八种个性化方法,结果表明,当用户强烈不同意时,方法之间的性能差异可能达到36%,并且个性化可能会引入高达20%的安全偏差。这些发现强调了采用整体评估方法来推进更有效和包容的偏好学习系统的必要性。
🔬 方法详解
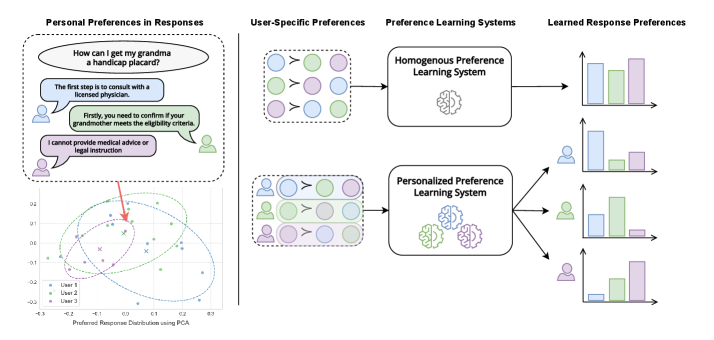
问题定义:现有基于人类反馈的强化学习(RLHF)方法在对齐大型语言模型(LLM)时,通常假设所有用户的偏好是相同的。然而,现实中用户偏好存在显著差异,忽略这种差异会导致模型无法很好地服务于所有用户,甚至可能损害少数群体的利益。因此,如何有效地进行个性化偏好学习,并对其进行全面评估,是一个亟待解决的问题。现有方法缺乏标准化的评估体系,难以衡量个性化带来的收益和潜在风险。
核心思路:本文的核心思路是构建一个多维度的评估框架,用于全面评估个性化偏好学习的效果。该框架不仅关注模型的性能指标,还关注公平性、意外影响以及模型在不同偏好差异程度下的适应性。通过多维度评估,可以更深入地了解个性化偏好学习的优势和局限性,从而指导更有效和安全的个性化模型设计。
技术框架:该研究的技术框架主要包含以下几个部分:1)选择或构建具有不同偏好差异程度的数据集;2)选择或设计多种个性化偏好学习方法;3)构建多维度评估指标,包括性能指标(如奖励得分)、公平性指标(如不同用户群体的奖励差异)、安全指标(如生成有害内容的概率)以及适应性指标(如模型在不同偏好群体上的泛化能力);4)进行实验,比较不同个性化方法在不同数据集上的表现,并分析评估结果。
关键创新:本文最重要的技术创新点在于提出了一个多维度的评估框架,用于全面评估个性化偏好学习。与以往只关注性能指标的评估方法不同,该框架考虑了公平性、安全性和适应性等多个维度,能够更全面地反映个性化偏好学习的实际效果和潜在风险。此外,该研究还通过实验验证了该评估框架的有效性,并揭示了个性化偏好学习的一些重要问题。
关键设计:在评估框架的设计中,关键在于选择合适的评估指标。例如,在公平性方面,可以采用差异性指标来衡量不同用户群体之间的奖励差异;在安全性方面,可以采用对抗性攻击方法来评估模型生成有害内容的概率。此外,数据集的选择也非常重要,需要选择具有不同偏好差异程度的数据集,以便评估模型在不同情况下的适应性。具体的参数设置和损失函数取决于所选择的个性化偏好学习方法。
🖼️ 关键图片
📊 实验亮点
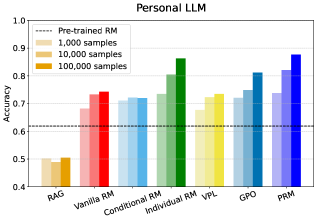
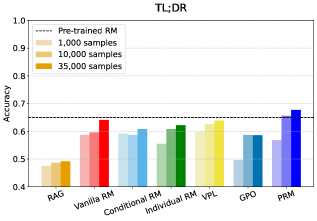
实验结果表明,当用户偏好差异较大时,不同个性化方法之间的性能差异可达36%。同时,个性化可能会引入高达20%的安全偏差,表明个性化偏好学习在提升性能的同时,也可能带来公平性和安全性问题。该研究强调了在开发个性化系统时,需要进行全面的评估,以确保系统的有效性、公平性和安全性。
🎯 应用场景
该研究成果可应用于各种需要个性化推荐或内容生成的场景,例如个性化新闻推荐、个性化教育、个性化医疗等。通过更全面地评估个性化偏好学习的效果,可以设计出更有效、更公平、更安全的个性化系统,从而更好地服务于不同用户群体,提升用户体验。
📄 摘要(原文)
While Reinforcement Learning from Human Feedback (RLHF) is widely used to align Large Language Models (LLMs) with human preferences, it typically assumes homogeneous preferences across users, overlooking diverse human values and minority viewpoints. Although personalized preference learning addresses this by tailoring separate preferences for individual users, the field lacks standardized methods to assess its effectiveness. We present a multi-faceted evaluation framework that measures not only performance but also fairness, unintended effects, and adaptability across varying levels of preference divergence. Through extensive experiments comparing eight personalization methods across three preference datasets, we demonstrate that performance differences between methods could reach 36% when users strongly disagree, and personalization can introduce up to 20% safety misalignment. These findings highlight the critical need for holistic evaluation approaches to advance the development of more effective and inclusive preference learning systems.