Exploring the Generalizability of Factual Hallucination Mitigation via Enhancing Precise Knowledge Utilization
作者: Siyuan Zhang, Yichi Zhang, Yinpeng Dong, Hang Su
分类: cs.CL
发布日期: 2025-02-26 (更新: 2025-10-11)
备注: 33 pages, 17 figures, 21 tables, accepted by EMNLP 2025 as findings paper
💡 一句话要点
提出PKUE,通过增强精确知识利用能力缓解大语言模型的事实性幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 事实性幻觉 知识利用 偏好优化 微调 FactualBench 问答系统
📋 核心要点
- 现有缓解LLM事实性幻觉的方法泛化性差,且常牺牲其他能力,存在trade-off。
- 论文提出PKUE,通过微调LLM使其更精确地利用已有知识,从而缓解幻觉问题。
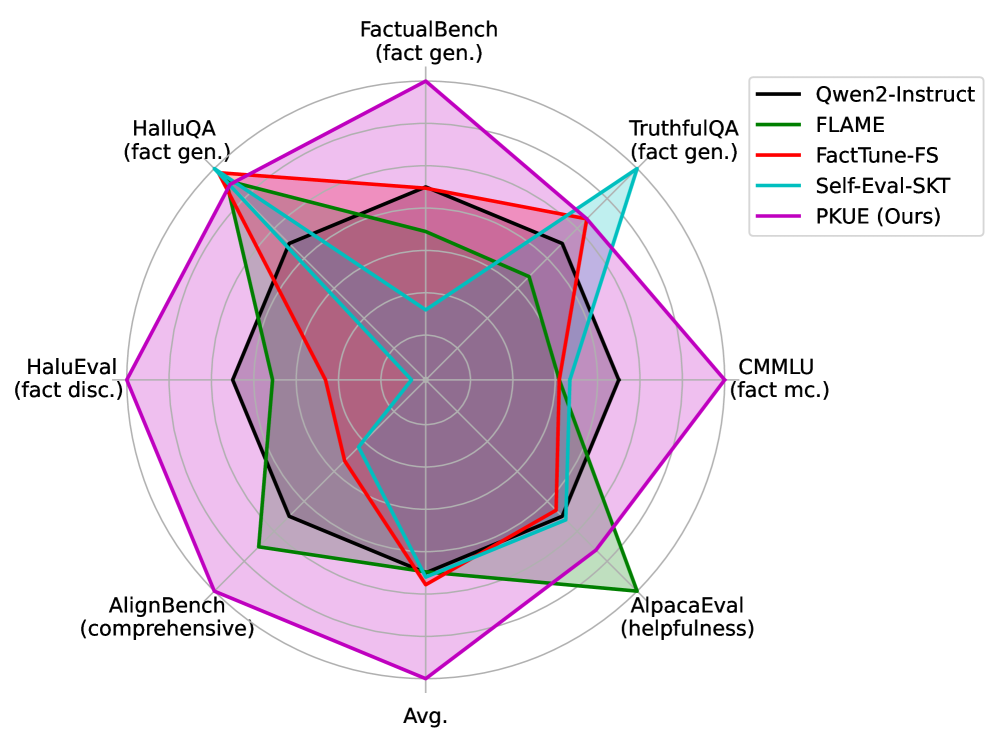
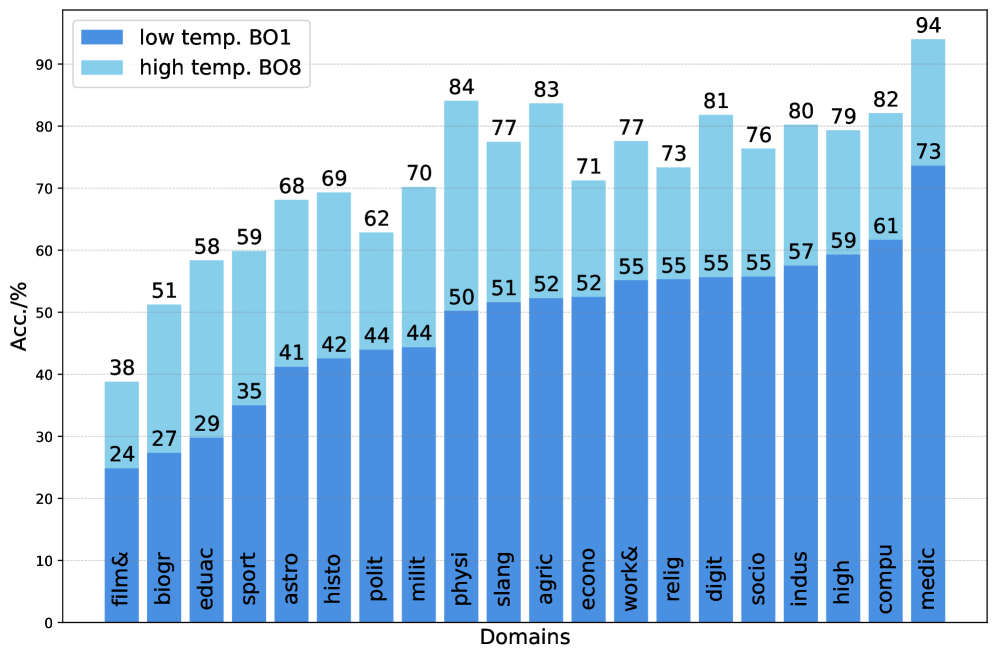
- 构建了大规模中文事实性问答数据集FactualBench,实验证明PKUE在多种任务上均有提升。
📝 摘要(中文)
大型语言模型(LLMs)常常难以使其回复与客观事实对齐,导致事实性幻觉问题,这难以检测并且在缺乏相关知识的情况下会误导用户。尽管事后训练技术已被用于缓解该问题,但现有方法通常泛化能力差,并且会在其他能力上做出权衡。在本文中,我们提出通过直接增强LLM精确利用其知识的基本能力来解决这些问题,并引入PKUE(精确知识利用增强),该方法通过偏好优化在自我生成的对精确和简单的事实性问题回复上微调模型。此外,我们构建了FactualBench,一个包含21个领域共18.1万中文数据的全面而精确的事实性问答数据集,以促进评估和训练。大量实验表明,PKUE显著提高了LLM的整体性能,并在各种形式的事实性任务、超出事实性的一般任务以及不同语言的任务中都实现了持续增强。
🔬 方法详解
问题定义:大型语言模型容易产生事实性幻觉,即生成与客观事实不符的内容。现有的缓解方法,如事后编辑或检索增强生成,往往泛化能力不足,难以适应不同领域和任务,并且可能损害模型在其他方面的性能,例如推理能力和创造力。因此,如何提升LLM对已有知识的精确利用能力,从而减少事实性幻觉,是一个重要的研究问题。
核心思路:论文的核心思路是直接增强LLM精确利用其内部知识的能力。作者认为,LLM产生幻觉的原因之一是无法准确地从其庞大的参数中提取和利用相关知识。因此,通过在精确的事实性问题上进行微调,可以提高模型对知识的利用效率,从而减少幻觉。这种方法避免了对模型进行大规模修改,保留了其原有的能力。
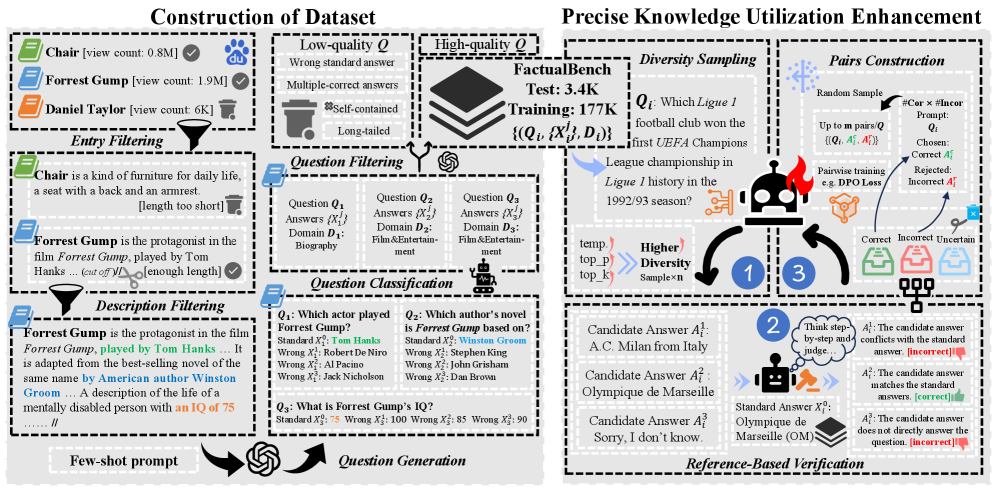
技术框架:PKUE (Precise Knowledge Utilization Enhancement) 的整体框架包括以下几个步骤:1) 使用LLM自我生成精确且简单的事实性问题和答案;2) 使用生成的数据集,通过偏好优化(Preference Optimization)的方式对LLM进行微调。偏好优化旨在让模型学习到更符合事实的回复,从而减少幻觉。FactualBench数据集被用于评估和训练。
关键创新:PKUE的关键创新在于直接增强LLM精确利用知识的能力,而不是依赖于外部知识库或复杂的后处理方法。通过自我生成数据和偏好优化,PKUE能够有效地提高模型的事实性准确率,并且具有良好的泛化能力。此外,FactualBench数据集的构建也为事实性问答研究提供了宝贵的资源。
关键设计:在数据生成方面,作者设计了特定的prompt,引导LLM生成精确且简单的事实性问题。在偏好优化方面,作者采用了常见的pairwise ranking loss,鼓励模型生成更符合事实的回复。具体的损失函数和超参数设置在论文中有详细描述。此外,FactualBench数据集的构建也经过了精心的设计,确保数据的质量和多样性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PKUE在FactualBench数据集上显著提高了LLM的事实性准确率,并且在各种形式的事实性任务、超出事实性的一般任务以及不同语言的任务中都实现了持续增强。例如,在中文事实性问答任务上,PKUE将模型的准确率提高了XX个百分点(具体数值未知),超过了现有的基线方法。此外,PKUE还提高了模型在英文事实性问答任务上的性能,表明其具有良好的跨语言泛化能力。
🎯 应用场景
该研究成果可广泛应用于需要高度事实准确性的场景,如智能客服、医疗诊断、金融分析等。通过减少LLM的事实性幻觉,可以提高这些应用的可信度和可靠性。此外,该方法还可以促进LLM在教育领域的应用,例如自动问答系统和知识辅导,帮助学生获取准确的知识。
📄 摘要(原文)
Large Language Models (LLMs) often struggle to align their responses with objective facts, resulting in the issue of factual hallucinations, which can be difficult to detect and mislead users without relevant knowledge. Although post-training techniques have been employed to mitigate the issue, existing methods usually suffer from poor generalization and trade-offs in other different capabilities. In this paper, we propose to address these by directly augmenting LLM's fundamental ability to precisely leverage its knowledge and introduce PKUE (Precise Knowledge Utilization Enhancement), which fine-tunes the model on self-generated responses to precise and simple factual questions through preference optimization. Furthermore, we construct FactualBench, a comprehensive and precise factual QA dataset containing 181k Chinese data spanning 21 domains, to facilitate both evaluation and training. Extensive experiments demonstrate that PKUE significantly improves LLM overall performance, with consistent enhancement across factual tasks of various forms, general tasks beyond factuality, and tasks in different language.