Low-Confidence Gold: Refining Low-Confidence Samples for Efficient Instruction Tuning
作者: Hongyi Cai, Jie Li, Mohammad Mahdinur Rahman, Wenzhen Dong
分类: cs.CL, cs.AI
发布日期: 2025-02-26 (更新: 2025-11-23)
备注: Accepted to EMNLP Findings 2025
💡 一句话要点
提出低置信度黄金(LCG)框架,高效过滤指令微调数据集,提升大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 大语言模型 半监督学习 数据过滤 低置信度 质心聚类 高效训练
📋 核心要点
- 指令微调的有效性受限于训练数据集的质量和效率,高质量数据筛选是关键。
- LCG框架通过质心聚类和置信度引导选择,筛选出高质量且多样性的指令对。
- 实验表明,使用LCG过滤后的数据集进行微调,模型性能优于现有方法,尤其在MT-bench上提升显著。
📝 摘要(中文)
本文提出了一种名为低置信度黄金(LCG)的新型过滤框架,用于识别有价值的指令对,从而提高指令微调的效率。LCG采用基于质心的聚类和置信度引导的选择方法。通过使用在代表性样本上训练的轻量级分类器,LCG采用半监督方法来管理高质量的子集,同时保留数据的多样性。实验评估表明,在LCG过滤的6K样本子集上微调的模型,与现有方法相比,表现出卓越的性能,在MT-bench上取得了显著的改进,并在全面的评估指标上获得了持续的收益。该框架在保持模型性能的同时,其有效性为高效指令微调建立了一个有希望的方向。
🔬 方法详解
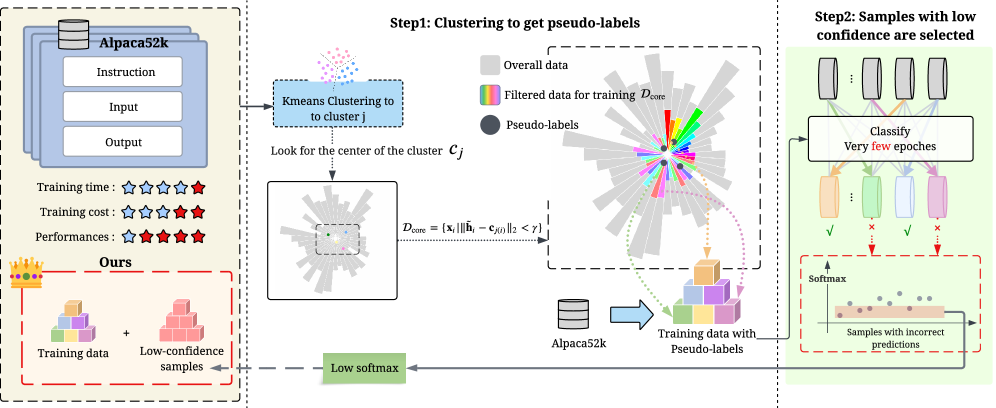
问题定义:现有指令微调方法受限于训练数据的质量和效率,高质量数据的获取成本高昂。如何从大量数据中筛选出高质量、多样性的指令对,以更少的训练数据达到更好的微调效果,是本文要解决的问题。现有方法通常依赖人工标注或简单的启发式规则,效率低且难以保证数据质量。
核心思路:本文的核心思路是利用半监督学习,通过一个轻量级的分类器,自动识别并筛选出高质量的指令对。该分类器基于少量代表性样本进行训练,并利用置信度作为筛选标准,从而在保证数据质量的同时,保留数据的多样性。
技术框架:LCG框架主要包含以下几个阶段:1) 数据预处理:对原始指令数据进行清洗和格式化。2) 特征提取:使用预训练语言模型提取指令对的特征向量。3) 质心聚类:使用聚类算法(如K-means)将特征向量聚类成若干个簇,每个簇的中心代表一类指令。4) 代表性样本选择:从每个簇中选择若干个具有代表性的样本,进行人工标注,构建少量高质量的训练集。5) 轻量级分类器训练:使用标注的训练集训练一个轻量级的分类器,用于预测指令对的质量。6) 低置信度样本筛选:使用训练好的分类器对剩余的未标注数据进行预测,选择置信度较低的样本作为高质量的指令对。
关键创新:LCG框架的关键创新在于其半监督的筛选方法,它结合了质心聚类和置信度引导的选择策略。与传统的完全依赖人工标注或启发式规则的方法相比,LCG能够更高效地筛选出高质量、多样性的指令对,从而提高指令微调的效率和效果。
关键设计:LCG框架的关键设计包括:1) 轻量级分类器的选择:选择计算复杂度较低的模型,如逻辑回归或支持向量机,以提高筛选效率。2) 置信度阈值的设置:根据实际情况调整置信度阈值,以控制筛选出的指令对的数量和质量。3) 聚类算法的选择:选择合适的聚类算法,如K-means或DBSCAN,以保证聚类效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在LCG过滤的6K样本子集上微调的模型,在MT-bench上取得了显著的改进,超过了现有方法。具体而言,LCG在保持模型性能的同时,显著减少了训练数据量,证明了其在高效指令微调方面的有效性。此外,LCG在其他评估指标上也获得了持续的收益,表明其具有良好的泛化能力。
🎯 应用场景
LCG框架可广泛应用于大语言模型的指令微调,尤其是在数据资源有限的情况下。它可以帮助研究人员和开发者更高效地构建高质量的训练数据集,从而提升模型的性能和泛化能力。此外,该框架还可以应用于其他自然语言处理任务,如文本分类、情感分析等,通过筛选高质量的训练数据来提高模型的效果。
📄 摘要(原文)
The effectiveness of instruction fine-tuning for Large Language Models is fundamentally constrained by the quality and efficiency of training datasets. This work introduces Low-Confidence Gold (LCG), a novel filtering framework that employs centroid-based clustering and confidence-guided selection for identifying valuable instruction pairs. Through a semi-supervised approach using a lightweight classifier trained on representative samples, LCG curates high-quality subsets while preserving data diversity. Experimental evaluation demonstrates that models fine-tuned on LCG-filtered subsets of 6K samples achieve superior performance compared to existing methods, with substantial improvements on MT-bench and consistent gains across comprehensive evaluation metrics. The framework's efficacy while maintaining model performance establishes a promising direction for efficient instruction tuning.