Towards Label-Only Membership Inference Attack against Pre-trained Large Language Models
作者: Yu He, Boheng Li, Liu Liu, Zhongjie Ba, Wei Dong, Yiming Li, Zhan Qin, Kui Ren, Chun Chen
分类: cs.CR, cs.CL
发布日期: 2025-02-26
备注: Accepted by USENIX Security 2025
💡 一句话要点
提出PETAL:一种针对预训练大语言模型的仅标签成员推理攻击方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推理攻击 大语言模型 隐私安全 仅标签攻击 语义相似性
📋 核心要点
- 现有成员推理攻击(MIAs)通常需要访问模型输出的logits,但在实际场景中难以获取,限制了其应用。
- 论文提出PETAL,一种仅需访问生成文本的token语义相似性的MIAs方法,通过近似概率和困惑度来推断成员信息。
- 实验表明,PETAL在多个基准数据集和开源LLMs上表现优异,甚至可以与基于logits的攻击相媲美。
📝 摘要(中文)
成员推理攻击(MIAs)旨在预测一个数据样本是否属于模型的训练集。尽管先前的研究已经广泛探索了大语言模型(LLMs)中的MIAs,但它们通常需要访问完整的输出logits(即,基于logits的攻击),这在实践中通常是不可行的。在本文中,我们研究了预训练LLMs在仅标签设置下对MIAs的脆弱性,在这种设置下,攻击者只能访问生成的tokens(文本)。我们首先揭示了现有的仅标签MIAs在攻击预训练LLMs时效果不佳,尽管它们在推断用于个性化LLMs的微调数据集时非常有效。我们发现它们的失败源于两个主要原因,包括更好的泛化和过于粗糙的扰动。为了缓解这些问题,我们提出了PETAL:一种基于token语义相似性的仅标签成员推理攻击。PETAL利用token级别的语义相似性来近似输出概率,并随后计算困惑度。它最终基于成员被“更好”地记忆并且具有更小困惑度的常见假设来暴露成员身份。我们在WikiMIA和更具挑战性的MIMIR基准上进行了广泛的实验。实验表明,我们的PETAL优于现有的针对个性化LLMs的仅标签攻击的扩展,甚至在五个流行的开源LLMs上的所有指标上与其它高级的基于logits的攻击相当。
🔬 方法详解
问题定义:论文旨在解决预训练大语言模型(LLMs)在仅标签设置下的成员推理攻击(MIA)问题。现有的MIAs方法通常需要访问模型的logits输出,这在实际应用中往往不可行。此外,现有的仅标签MIAs方法在攻击预训练LLMs时效果不佳,因为预训练LLMs具有更好的泛化能力,并且token级别的扰动过于粗糙,难以捕捉成员和非成员之间的细微差异。
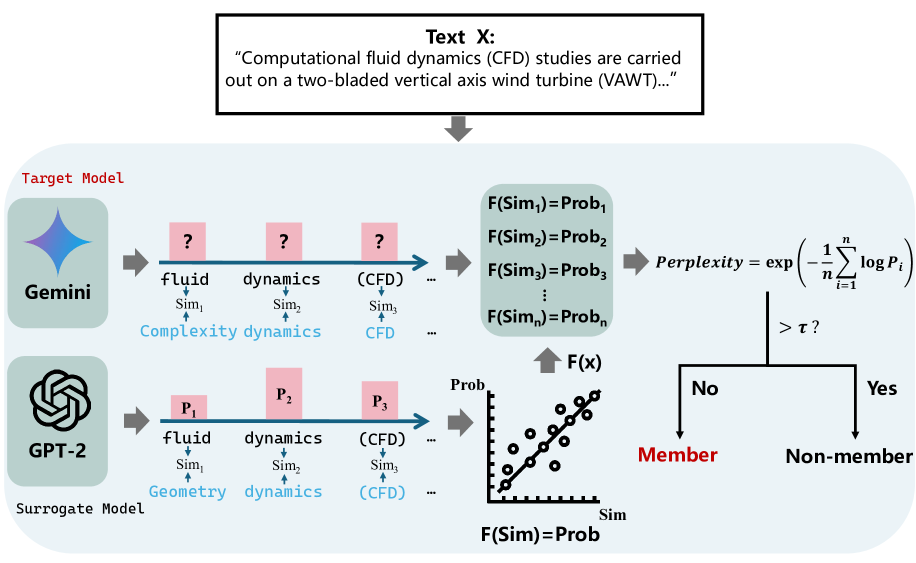
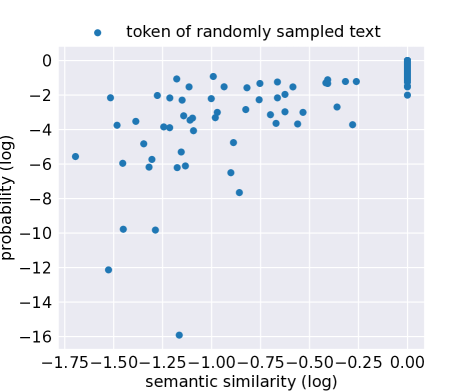
核心思路:PETAL的核心思路是利用token级别的语义相似性来近似输出概率,进而计算困惑度(perplexity)。该方法基于一个假设:模型对于训练集中的成员数据“记忆”得更好,因此在生成文本时,成员数据的困惑度应该更小。通过分析生成文本的困惑度,可以推断出某个样本是否属于模型的训练集。
技术框架:PETAL攻击框架主要包含以下几个步骤:1) 对于给定的输入文本,使用目标LLM生成输出文本;2) 计算生成文本中每个token与其上下文的语义相似性;3) 基于token级别的语义相似性,近似计算输出概率;4) 根据近似的输出概率,计算整个生成文本的困惑度;5) 使用困惑度作为判断依据,推断输入文本是否为训练集成员。
关键创新:PETAL的关键创新在于它提出了一种基于token语义相似性的方法来近似输出概率,从而实现了在仅标签设置下的成员推理攻击。与现有的仅标签MIAs方法相比,PETAL能够更有效地捕捉成员和非成员之间的细微差异,从而提高了攻击的成功率。
关键设计:PETAL的关键设计包括:1) 使用预训练的语言模型(例如BERT或RoBERTa)来计算token之间的语义相似性;2) 设计合适的公式,将token级别的语义相似性转化为近似的输出概率;3) 选择合适的困惑度阈值,用于区分成员和非成员。具体参数设置和阈值选择需要根据不同的LLM和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PETAL在WikiMIA和MIMIR基准数据集上显著优于现有的仅标签MIAs方法,并且在五个流行的开源LLMs上达到了与基于logits的攻击相当的性能。例如,在某些指标上,PETAL的性能提升超过了10%。这表明PETAL是一种有效的针对预训练LLMs的仅标签成员推理攻击方法。
🎯 应用场景
该研究成果可应用于评估和提升预训练大语言模型的隐私安全性,防止模型训练数据泄露。同时,该方法也可用于检测和防御针对LLMs的恶意攻击,例如识别由模型生成的虚假信息或恶意代码。此外,该研究对于开发更安全的AI系统具有重要意义。
📄 摘要(原文)
Membership Inference Attacks (MIAs) aim to predict whether a data sample belongs to the model's training set or not. Although prior research has extensively explored MIAs in Large Language Models (LLMs), they typically require accessing to complete output logits (\ie, \textit{logits-based attacks}), which are usually not available in practice. In this paper, we study the vulnerability of pre-trained LLMs to MIAs in the \textit{label-only setting}, where the adversary can only access generated tokens (text). We first reveal that existing label-only MIAs have minor effects in attacking pre-trained LLMs, although they are highly effective in inferring fine-tuning datasets used for personalized LLMs. We find that their failure stems from two main reasons, including better generalization and overly coarse perturbation. Specifically, due to the extensive pre-training corpora and exposing each sample only a few times, LLMs exhibit minimal robustness differences between members and non-members. This makes token-level perturbations too coarse to capture such differences. To alleviate these problems, we propose \textbf{PETAL}: a label-only membership inference attack based on \textbf{PE}r-\textbf{T}oken sem\textbf{A}ntic simi\textbf{L}arity. Specifically, PETAL leverages token-level semantic similarity to approximate output probabilities and subsequently calculate the perplexity. It finally exposes membership based on the common assumption that members are `better' memorized and have smaller perplexity. We conduct extensive experiments on the WikiMIA benchmark and the more challenging MIMIR benchmark. Empirically, our PETAL performs better than the extensions of existing label-only attacks against personalized LLMs and even on par with other advanced logit-based attacks across all metrics on five prevalent open-source LLMs.