A Causal Lens for Evaluating Faithfulness Metrics
作者: Kerem Zaman, Shashank Srivastava
分类: cs.CL, cs.AI, cs.LG, stat.ME
发布日期: 2025-02-26 (更新: 2025-12-24)
备注: Published at EMNLP 2025; 25 pages, 22 figures, 9 tables
💡 一句话要点
提出因果诊断框架,评估自然语言解释忠实度指标的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释性 忠实度评估 因果推理 大型语言模型 模型编辑
📋 核心要点
- 现有忠实度指标评估方法缺乏统一标准,难以进行有效比较和选择。
- 论文提出因果诊断框架,通过模型编辑生成忠实/不忠实解释对,评估指标区分能力。
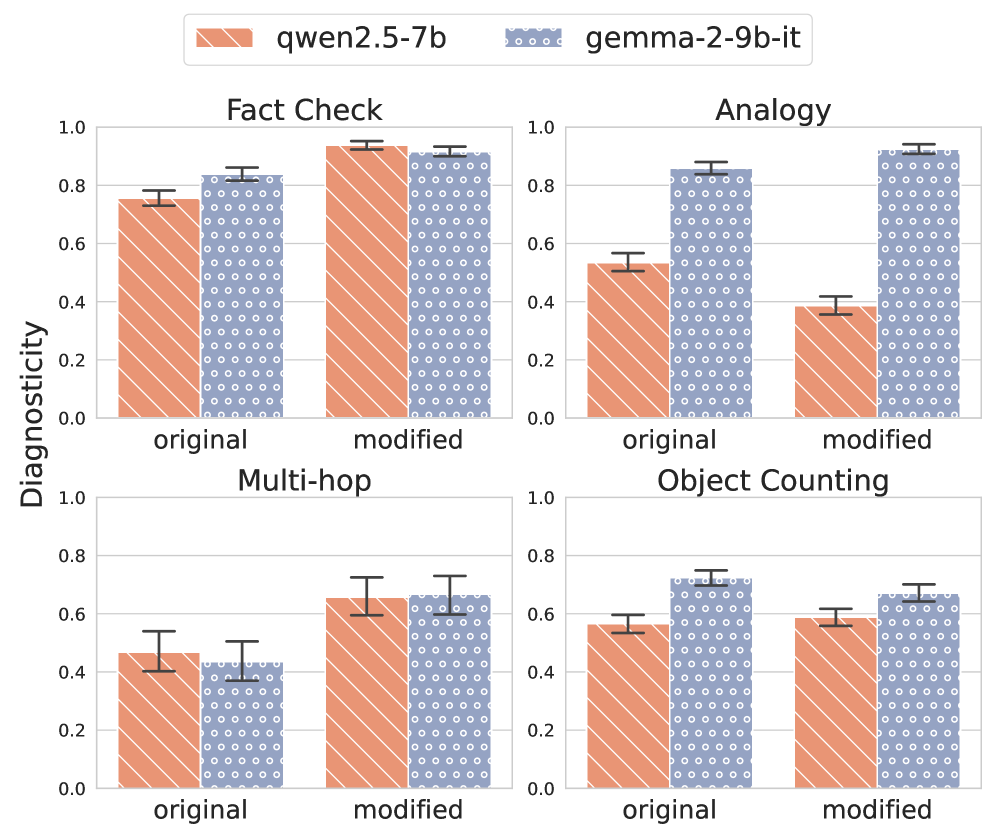
- 实验表明,不同指标在不同任务上表现差异显著,连续指标优于二元指标,但更易受噪声影响。
📝 摘要(中文)
大型语言模型(LLM)提供自然语言解释,作为模型可解释性的特征归因方法的替代方案。然而,尽管这些解释看似合理,但它们可能无法忠实地反映模型真实的推理过程。虽然已经提出了几种忠实度指标,但它们通常是孤立地进行评估,这使得它们之间的原则性比较变得困难。我们提出了因果诊断(Causal Diagnosticity),这是一个用于评估自然语言解释忠实度指标的测试平台框架。我们使用诊断性的概念,并采用模型编辑方法来生成忠实-不忠实解释对。我们的基准测试包括四个任务:事实核查、类比、对象计数和多跳推理。我们评估了突出的忠实度指标,包括事后解释和思维链方法。诊断性能因任务和模型而异,其中填充词(Filler Tokens)总体表现最佳。此外,连续指标通常比二元指标更具诊断性,但可能对噪声和模型选择敏感。我们的结果强调了需要更强大的忠实度指标。
🔬 方法详解
问题定义:现有的大型语言模型解释方法,如自然语言解释和思维链,虽然在表面上看起来合理,但缺乏对模型真实推理过程的忠实性保证。现有的忠实度指标评估方法通常是孤立的,缺乏一个统一的、可比较的框架,难以判断哪个指标更有效,以及在什么情况下适用。因此,需要一种能够系统性地评估和比较不同忠实度指标的方法。
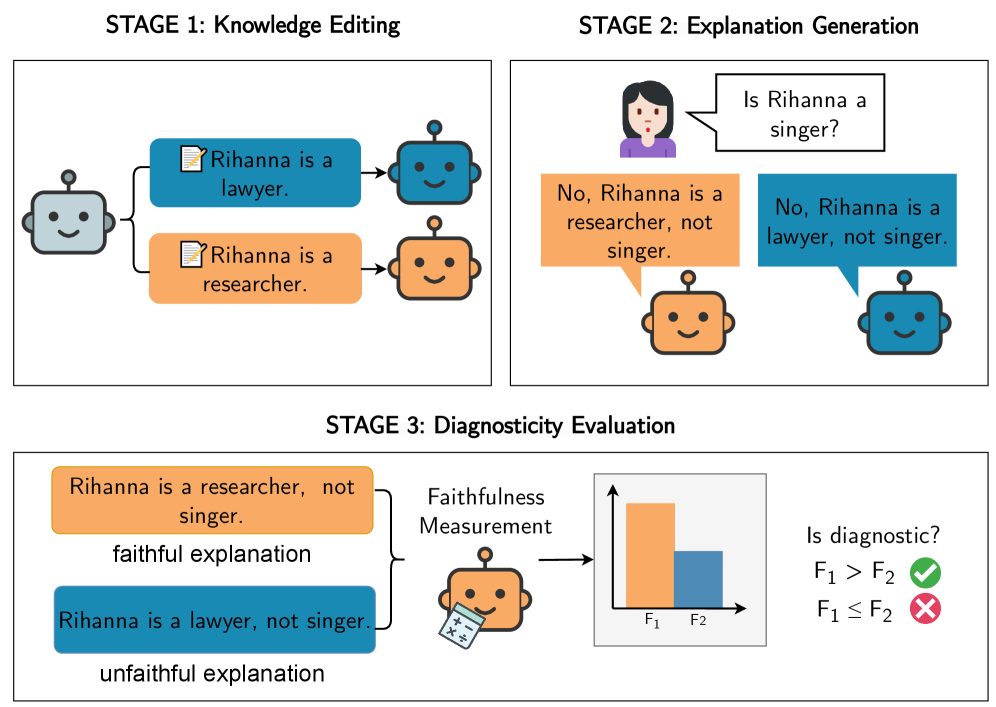
核心思路:论文的核心思路是借鉴因果推理中的诊断性概念,构建一个测试平台,通过人为干预(模型编辑)来生成已知忠实或不忠实的解释,然后使用这些解释来评估各种忠实度指标区分忠实和不忠实解释的能力。如果一个指标能够准确地区分这两种类型的解释,那么它就被认为是更具诊断性的,也就是更可靠的。
技术框架:该框架包含以下几个主要步骤:1) 选择一个需要解释的模型和任务;2) 使用模型编辑技术,对模型进行干预,使其产生已知忠实或不忠实的解释;3) 使用各种忠实度指标对这些解释进行评分;4) 根据指标的评分结果,评估其区分忠实和不忠实解释的能力,即诊断性。框架的核心是模型编辑技术,用于生成可控的解释。
关键创新:该论文的关键创新在于将因果推理中的诊断性概念引入到自然语言解释的评估中,并提出了一个基于模型编辑的测试平台。这种方法能够系统性地评估和比较不同忠实度指标的有效性,而不仅仅是依赖于主观判断或间接指标。此外,论文还通过实验验证了该框架的有效性,并发现了一些有趣的现象,例如不同指标在不同任务上的表现差异。
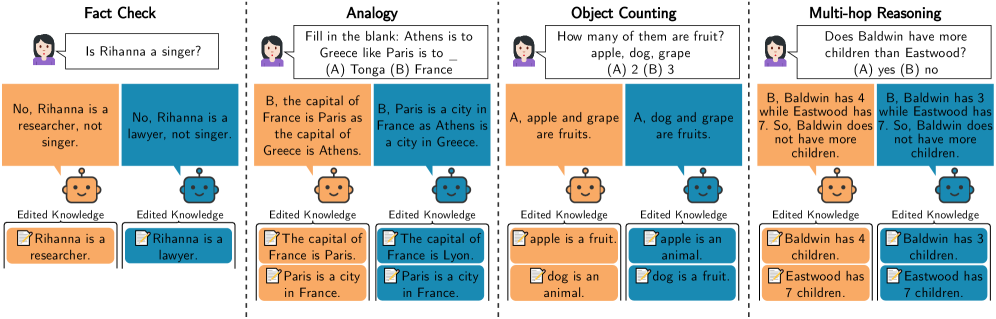
关键设计:模型编辑技术是关键设计之一,用于控制模型生成解释的忠实性。论文使用了多种模型编辑方法,例如修改模型的参数或输入,以使其产生与真实推理过程一致或不一致的解释。此外,论文还设计了一系列评估指标,用于衡量忠实度指标的诊断性,例如准确率、召回率和F1值。具体任务包括事实核查、类比、对象计数和多跳推理,涵盖了不同类型的推理能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同忠实度指标在不同任务上表现差异显著,例如Filler Tokens方法在总体上表现最佳。连续型指标通常比二元型指标更具诊断性,但更容易受到噪声和模型选择的影响。这些发现为选择合适的忠实度指标提供了重要参考,并揭示了现有指标的局限性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可信度和可靠性,例如在医疗诊断、金融分析等高风险领域,确保模型提供的解释能够真实反映其推理过程,避免因不忠实解释导致错误决策。此外,该框架也可用于指导新型忠实度指标的开发,推动可解释人工智能领域的发展。
📄 摘要(原文)
Large Language Models (LLMs) offer natural language explanations as an alternative to feature attribution methods for model interpretability. However, despite their plausibility, they may not reflect the model's true reasoning faithfully. While several faithfulness metrics have been proposed, they are often evaluated in isolation, making principled comparisons between them difficult. We present Causal Diagnosticity, a testbed framework for evaluating faithfulness metrics for natural language explanations. We use the concept of diagnosticity, and employ model-editing methods to generate faithful-unfaithful explanation pairs. Our benchmark includes four tasks: fact-checking, analogy, object counting, and multi-hop reasoning. We evaluate prominent faithfulness metrics, including post-hoc explanation and chain-of-thought methods. Diagnostic performance varies across tasks and models, with Filler Tokens performing best overall. Additionally, continuous metrics are generally more diagnostic than binary ones but can be sensitive to noise and model choice. Our results highlight the need for more robust faithfulness metrics.