Scalable Best-of-N Selection for Large Language Models via Self-Certainty
作者: Zhewei Kang, Xuandong Zhao, Dawn Song
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-25 (更新: 2025-12-12)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于自确信度的可扩展Best-of-N选择方法,提升大语言模型推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 Best-of-N选择 自确信度 无监督学习
📋 核心要点
- 现有Best-of-N方法依赖计算密集的奖励模型,或在开放任务中表现不佳,限制了LLM推理能力的提升。
- 论文提出自确信度指标,利用LLM自身概率分布评估生成质量,无需额外奖励模型,降低计算成本。
- 实验表明,自确信度可有效扩展,提升思维链推理性能,并泛化到开放式任务,验证了其有效性。
📝 摘要(中文)
Best-of-N选择是一种通过增加测试时计算来提高大型语言模型(LLM)推理性能的关键技术。目前最先进的方法通常采用计算密集型的奖励模型进行响应评估和选择。像自洽性和通用自洽性这样的无奖励替代方案,在处理开放式生成任务或有效扩展方面受到限制。为了解决这些限制,我们提出自确信度,这是一种新颖而有效的指标,它利用LLM输出的固有概率分布来估计响应质量,而无需外部奖励模型。我们假设,在多个样本中聚合的较高分布自确信度与提高的响应准确性相关,因为它反映了对生成输出的更大信心。通过在各种推理任务上的大量实验,我们证明了自确信度(1)可以像奖励模型一样有效地随着样本量N的增加而扩展,但没有计算开销;(2)补充了思维链,提高了超出贪婪解码的推理性能;(3)推广到传统自洽性方法不足的开放式任务。我们的发现确立了自确信度是提高LLM推理能力的实用而有效的方法。
🔬 方法详解
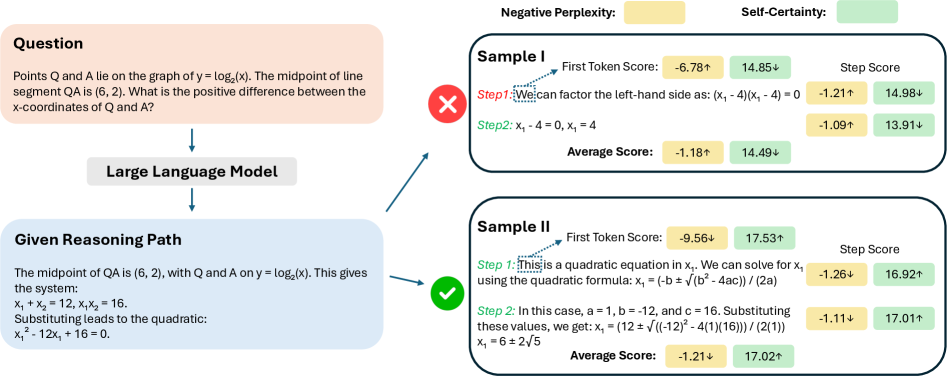
问题定义:现有Best-of-N方法在提升大型语言模型推理性能时,主要面临两个痛点:一是依赖于计算复杂度高的奖励模型进行响应评估,导致计算开销大;二是无奖励模型的方法(如自洽性)在开放式生成任务中表现受限,难以有效评估生成质量。因此,如何设计一种高效且通用的响应质量评估指标,成为提升LLM推理能力的关键问题。
核心思路:论文的核心思路是利用LLM自身输出的概率分布来估计响应质量,提出“自确信度”这一指标。其基本假设是:如果LLM对生成的响应更有信心(即概率分布更集中),则该响应的质量更高。通过聚合多个样本的自确信度,可以更准确地评估响应的整体质量,从而实现更有效的Best-of-N选择。
技术框架:该方法主要包含以下几个阶段:1) 使用LLM生成N个候选响应;2) 计算每个响应的自确信度,具体来说,是对每个token的生成概率取对数,然后求和或平均;3) 将N个响应的自确信度进行聚合,例如取平均值或最大值,得到最终的自确信度得分;4) 选择自确信度得分最高的响应作为最终输出。整个流程无需额外的奖励模型,仅依赖LLM自身的输出。
关键创新:该方法最重要的技术创新点在于提出了自确信度这一指标,它是一种内在的、无监督的响应质量评估方法。与依赖外部奖励模型的方法相比,自确信度无需训练额外的模型,降低了计算成本和部署难度。与传统的自洽性方法相比,自确信度可以更好地处理开放式生成任务,因为它直接评估生成概率,而不是依赖于多个响应之间的一致性。
关键设计:自确信度的计算方式是关键设计之一。论文中可能探讨了不同的聚合方式(例如平均、最大值等)对性能的影响。此外,如何对生成概率进行平滑处理,以避免概率为零的情况,也是一个重要的技术细节。具体的损失函数没有涉及,因为该方法是无监督的,不需要训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,自确信度在多个推理任务上均取得了显著的性能提升。例如,在某些任务上,使用自确信度进行Best-of-N选择,可以达到与使用奖励模型相当的性能,但计算成本更低。此外,自确信度还可以与思维链技术相结合,进一步提高推理准确性。实验还验证了自确信度在开放式任务中的有效性,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于需要高质量LLM推理的场景,如问答系统、文本摘要、代码生成、创意写作等。通过提高LLM的推理准确性和效率,可以提升用户体验,降低计算成本,并推动LLM在更广泛领域的应用。未来,该方法有望与其他技术(如知识图谱、外部检索)相结合,进一步提升LLM的性能。
📄 摘要(原文)
Best-of-N selection is a key technique for improving the reasoning performance of Large Language Models (LLMs) through increased test-time computation. Current state-of-the-art methods often employ computationally intensive reward models for response evaluation and selection. Reward-free alternatives, like self-consistency and universal self-consistency, are limited in their ability to handle open-ended generation tasks or scale effectively. To address these limitations, we propose self-certainty, a novel and efficient metric that leverages the inherent probability distribution of LLM outputs to estimate response quality without requiring external reward models. We hypothesize that higher distributional self-certainty, aggregated across multiple samples, correlates with improved response accuracy, as it reflects greater confidence in the generated output. Through extensive experiments on various reasoning tasks, we demonstrate that self-certainty (1) scales effectively with increasing sample size N, akin to reward models but without the computational overhead; (2) complements chain-of-thought, improving reasoning performance beyond greedy decoding; and (3) generalizes to open-ended tasks where traditional self-consistency methods fall short. Our findings establish self-certainty as a practical and efficient way for improving LLM reasoning capabilities. The code is available at https://github.com/backprop07/Self-Certainty