TextGames: Learning to Self-Play Text-Based Puzzle Games via Language Model Reasoning
作者: Frederikus Hudi, Genta Indra Winata, Ruochen Zhang, Alham Fikri Aji
分类: cs.CL, cs.AI
发布日期: 2025-02-25
💡 一句话要点
提出TextGames基准,评估LLM在文本游戏中的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本游戏 推理能力 基准测试 自我反思
📋 核心要点
- 大型语言模型在复杂推理任务中仍面临挑战,尤其是在需要模式识别、空间感知等高级技能的场景。
- TextGames基准通过设计具有挑战性的文本游戏,评估LLM在单轮和多轮推理中的能力,并考察其自我反思能力。
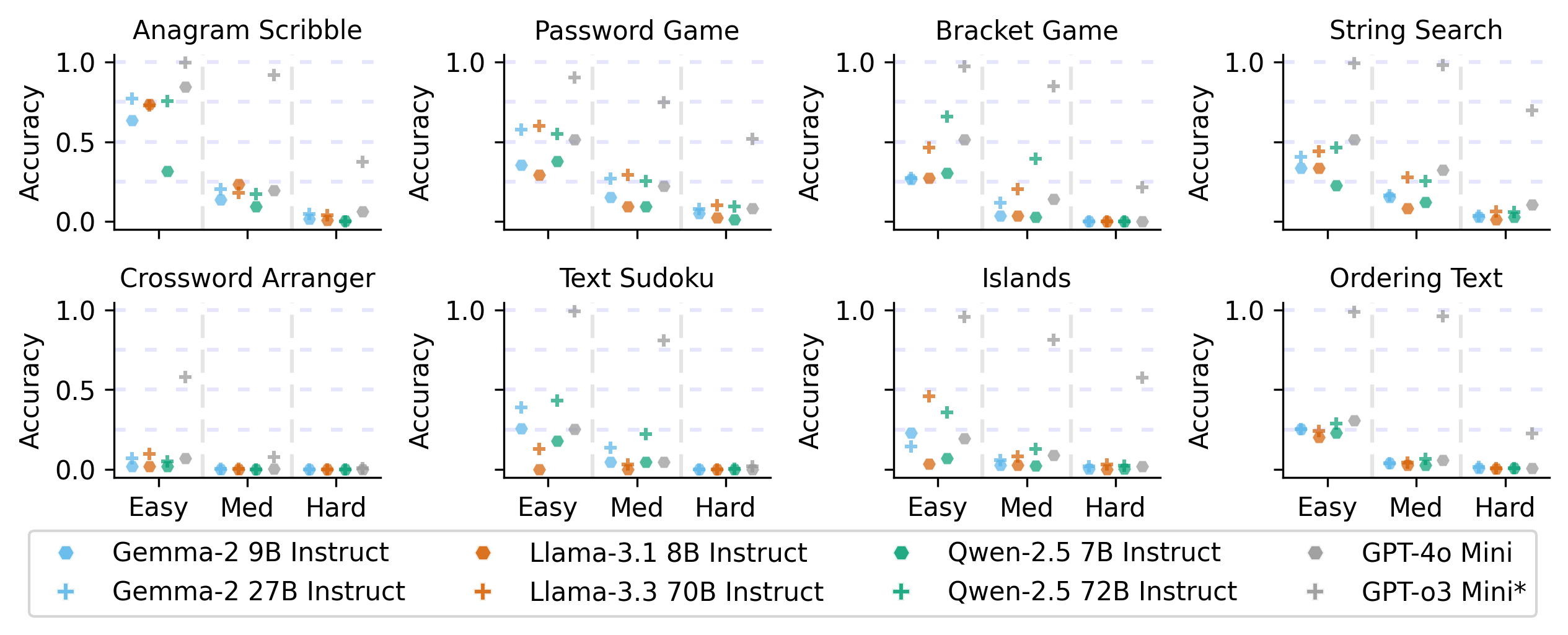
- 实验表明,LLM在简单和中等难度任务中表现良好,但在困难任务中表现不佳,且针对推理优化的模型表现更优。
📝 摘要(中文)
本文介绍了一个名为TextGames的创新基准,旨在通过具有挑战性的文本游戏评估大型语言模型(LLM)的推理能力。这些游戏需要模式识别、空间感知、算术和逻辑推理等高级技能。分析考察了LLM在单轮和多轮推理中的表现,以及它们利用反馈通过自我反思来纠正后续答案的能力。研究结果表明,尽管LLM在解决大多数简单和中等难度的问题时表现出熟练程度,但它们在更困难的任务中面临重大挑战。相比之下,人类在有足够时间的情况下能够解决所有任务。此外,我们观察到LLM通过自我反思在多轮预测中表现出改进的性能,但它们仍然难以一致地进行排序、计数和遵循复杂的规则。此外,针对推理优化的模型优于优先考虑指令遵循的预训练LLM,突出了推理技能在解决高度复杂问题中的关键作用。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在复杂推理任务中的能力,特别是在文本游戏环境中。现有方法通常侧重于指令遵循,而忽略了LLM在需要高级推理技能(如模式识别、空间感知、算术和逻辑推理)的任务中的表现。因此,现有的基准测试可能无法充分反映LLM在解决现实世界复杂问题时的能力。
核心思路:论文的核心思路是创建一个新的基准测试,即TextGames,该基准包含一系列具有挑战性的文本游戏,这些游戏需要LLM进行多步推理和自我反思。通过分析LLM在这些游戏中的表现,可以更全面地了解LLM的推理能力,并确定其优势和劣势。这种方法能够更有效地评估LLM在解决复杂问题时的潜力。
技术框架:TextGames基准包含一系列文本游戏,每个游戏都设计为测试LLM的不同推理能力。LLM通过与游戏环境交互来解决游戏。交互过程包括:1) LLM接收游戏描述和当前状态;2) LLM生成一个动作;3) 游戏环境执行该动作并返回新的状态和奖励。该过程重复进行,直到LLM成功解决游戏或达到最大步数。论文还分析了LLM在单轮和多轮推理中的表现,以及它们利用反馈进行自我反思的能力。
关键创新:TextGames基准的主要创新在于其专注于评估LLM在需要高级推理技能的文本游戏中的表现。与现有基准测试相比,TextGames更具挑战性,并且更能够反映LLM在解决现实世界复杂问题时的能力。此外,论文还提出了一种新的评估方法,该方法可以分析LLM在单轮和多轮推理中的表现,以及它们利用反馈进行自我反思的能力。
关键设计:TextGames中的游戏设计涵盖多种推理类型,包括模式识别、空间感知、算术和逻辑推理。游戏难度分为简单、中等和困难三个等级。评估指标包括游戏解决率、平均步数和奖励。论文还使用了不同的LLM架构,包括预训练的LLM和针对推理优化的LLM。此外,论文还研究了不同的自我反思策略对LLM性能的影响。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在简单和中等难度的TextGames游戏中表现出一定的解决能力,但在困难游戏中面临挑战。针对推理优化的LLM优于预训练的LLM。通过自我反思,LLM在多轮预测中的性能有所提高,但仍难以处理排序、计数和复杂规则等问题。人类在有足够时间的情况下可以解决所有任务。
🎯 应用场景
该研究成果可应用于开发更强大的AI游戏智能体,提升LLM在复杂问题解决、决策制定和规划方面的能力。TextGames基准的提出,有助于推动LLM在需要高级推理能力的实际应用场景中的发展,例如智能助手、自动化推理系统等。
📄 摘要(原文)
Reasoning is a fundamental capability of large language models (LLMs), enabling them to comprehend, analyze, and solve complex problems. In this paper, we introduce TextGames, an innovative benchmark specifically crafted to assess LLMs through demanding text-based games that require advanced skills in pattern recognition, spatial awareness, arithmetic, and logical reasoning. Our analysis probes LLMs' performance in both single-turn and multi-turn reasoning, and their abilities in leveraging feedback to correct subsequent answers through self-reflection. Our findings reveal that, although LLMs exhibit proficiency in addressing most easy and medium-level problems, they face significant challenges with more difficult tasks. In contrast, humans are capable of solving all tasks when given sufficient time. Moreover, we observe that LLMs show improved performance in multi-turn predictions through self-reflection, yet they still struggle with sequencing, counting, and following complex rules consistently. Additionally, models optimized for reasoning outperform pre-trained LLMs that prioritize instruction following, highlighting the crucial role of reasoning skills in addressing highly complex problems.