League: Leaderboard Generation on Demand
作者: Jian Wu, Jiayu Zhang, Dongyuan Li, Linyi Yang, Aoxiao Zhong, Renhe Jiang, Qingsong Wen, Yue Zhang
分类: cs.CL, cs.AI
发布日期: 2025-02-25 (更新: 2025-10-04)
💡 一句话要点
提出Leaderboard Auto Generation (LAG)框架,自动生成AI研究领域排行榜。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 排行榜生成 自动化 大型语言模型 人工智能 信息提取
📋 核心要点
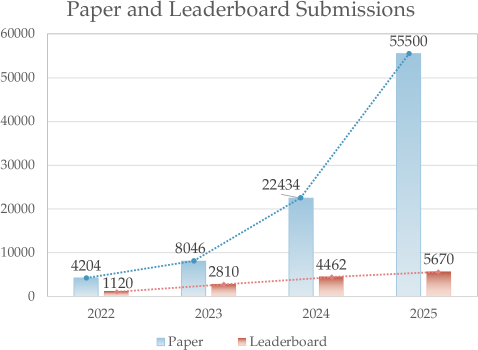
- 人工智能领域论文数量激增,研究人员难以追踪所有论文的方法和结果,需要自动化的排行榜构建方法。
- LAG框架通过论文收集、结果提取整合、排行榜生成和质量评估等步骤,系统地解决了排行榜自动生成问题。
- 实验结果表明,LAG框架生成的排行榜质量高,为研究人员提供有价值的参考信息。
📝 摘要(中文)
本文介绍了一种新颖且组织良好的框架——Leaderboard Auto Generation (LAG),用于在快速发展的人工智能(AI)等领域中,针对给定的研究主题自动生成排行榜。面对每天大量更新的AI论文,研究人员难以追踪每篇论文提出的方法、实验结果和设置,因此需要高效的自动排行榜构建方法。虽然大型语言模型(LLM)在自动化此过程方面展现出潜力,但多文档摘要、排行榜生成和实验公平比较等挑战仍有待探索。LAG通过系统的方法解决了这些挑战,包括论文收集、实验结果提取和整合、排行榜生成和质量评估。我们的贡献包括针对排行榜构建问题的全面解决方案、可靠的评估方法以及展示排行榜高质量的实验结果。
🔬 方法详解
问题定义:当前人工智能领域论文数量庞大且更新迅速,研究人员难以有效跟踪和比较不同论文提出的方法和实验结果。现有的手动构建排行榜的方式效率低下,且容易受到主观因素的影响。因此,需要一种自动化的方法来生成高质量的排行榜,以便研究人员快速了解特定研究领域的最新进展。
核心思路:LAG框架的核心思路是利用大型语言模型(LLM)的强大能力,自动化地从大量的论文中提取实验结果,并将其整合到统一的排行榜中。通过系统化的流程,确保提取的信息准确可靠,并进行公平的比较。
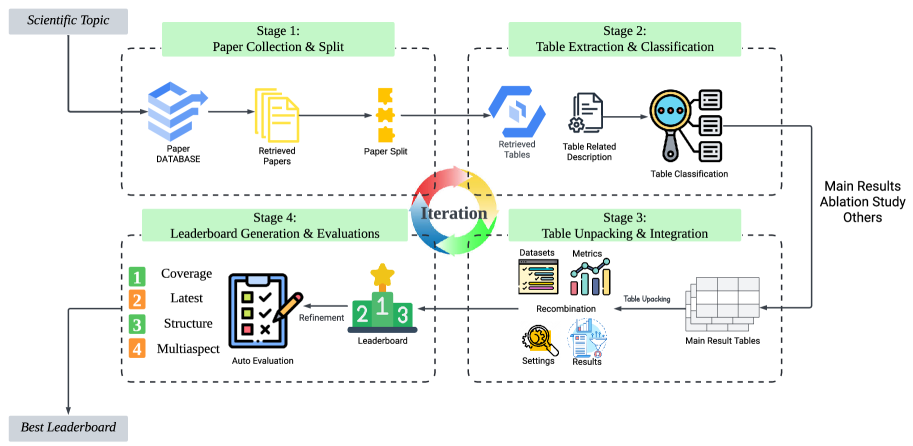
技术框架:LAG框架包含以下几个主要模块:1) 论文收集:收集特定研究主题的相关论文。2) 实验结果提取和整合:利用LLM从论文中提取实验结果,并将不同论文的结果整合到统一的格式中。3) 排行榜生成:根据整合后的实验结果,生成排行榜。4) 质量评估:对生成的排行榜进行质量评估,确保其准确性和可靠性。
关键创新:LAG框架的关键创新在于其系统化的流程和对LLM的有效利用。它不仅解决了多文档摘要和信息提取的挑战,还考虑了实验结果的公平比较问题,从而生成高质量的排行榜。此外,该框架还提供了一种可靠的评估方法,用于评估生成的排行榜的质量。
关键设计:LAG框架的关键设计包括:1) 使用特定的提示工程(prompt engineering)技术,指导LLM准确地从论文中提取实验结果。2) 设计了一种统一的格式,用于存储和比较不同论文的实验结果。3) 采用多种指标来评估排行榜的质量,包括准确性、完整性和一致性等。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了LAG框架的有效性,表明其能够生成高质量的排行榜。具体的性能数据和对比基线在摘要中未提及,属于未知信息。但论文强调了实验结果展示了排行榜的高质量,暗示了LAG在准确性、完整性和一致性等方面表现良好。
🎯 应用场景
LAG框架可应用于快速发展的人工智能及其他科学研究领域,帮助研究人员快速了解特定研究方向的最新进展和最佳实践。该框架能够显著提高研究效率,促进学术交流和合作,并加速技术创新。未来,LAG可以扩展到其他类型的数据,例如代码库和数据集,从而提供更全面的研究资源。
📄 摘要(原文)
This paper introduces Leaderboard Auto Generation (LAG), a novel and well-organized framework for automatic generation of leaderboards on a given research topic in rapidly evolving fields like Artificial Intelligence (AI). Faced with a large number of AI papers updated daily, it becomes difficult for researchers to track every paper's proposed methods, experimental results, and settings, prompting the need for efficient automatic leaderboard construction. While large language models (LLMs) offer promise in automating this process, challenges such as multi-document summarization, leaderboard generation, and experiment fair comparison still remain under exploration. LAG solves these challenges through a systematic approach that involves the paper collection, experiment results extraction and integration, leaderboard generation, and quality evaluation. Our contributions include a comprehensive solution to the leaderboard construction problem, a reliable evaluation method, and experimental results showing the high quality of leaderboards.