Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
作者: Zhixian Zhao, Xinfa Zhu, Xinsheng Wang, Shuiyuan Wang, Xuelong Geng, Wenjie Tian, Lei Xie
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-02-25 (更新: 2025-12-29)
备注: This work has been published in IEEE Transactions on Audio, Speech and Language Processing
DOI: 10.1109/TASLPRO.2025.3648793
💡 一句话要点
提出C$^2$SER模型,通过上下文感知和思维链提升语音情感识别的稳定性和准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音情感识别 音频语言模型 思维链 上下文感知 自蒸馏 半监督学习 情感计算
📋 核心要点
- 现有音频语言模型在语音情感识别中易产生幻觉,导致识别错误或输出无关信息。
- C$^2$SER模型通过整合上下文感知模块和思维链方法,提升情感识别的稳定性和准确性。
- 实验结果表明,C$^2$SER在情感识别任务上优于现有模型,并开源了代码和数据。
📝 摘要(中文)
大规模音频语言模型(ALMs),如Qwen2-Audio,能够理解各种音频信号,执行音频分析并生成文本响应。然而,在语音情感识别(SER)中,ALMs经常出现幻觉问题,导致错误分类或不相关的输出。为了解决这些挑战,我们提出了一种新颖的ALM模型C$^2$SER,旨在通过上下文感知和思维链(CoT)增强SER的稳定性和准确性。C$^2$SER集成了Whisper编码器用于语义感知,以及Emotion2Vec-S用于声学感知,其中Emotion2Vec-S通过半监督学习扩展了Emotion2Vec,以增强情感区分能力。此外,C$^2$SER采用CoT方法,以逐步的方式处理SER,同时利用语音内容和说话风格来提高识别率。为了进一步提高稳定性,C$^2$SER引入了从显式CoT到隐式CoT的自蒸馏,减少了误差累积并提高了识别精度。大量实验表明,C$^2$SER优于现有的流行ALMs,如Qwen2-Audio和SECap,提供了更稳定和精确的情感识别。我们发布了训练代码、检查点和测试集,以促进进一步的研究。
🔬 方法详解
问题定义:论文旨在解决现有大规模音频语言模型(ALMs)在语音情感识别(SER)任务中存在的“幻觉”问题,即模型产生不准确或与输入无关的输出。现有方法在处理情感识别时,容易受到噪声、说话风格等因素的干扰,导致识别结果不稳定和不准确。
核心思路:论文的核心思路是通过引入上下文感知和思维链(CoT)机制,增强模型对语音情感的理解和推理能力。上下文感知模块旨在提取更丰富的语义和声学特征,而CoT机制则模拟人类逐步推理的过程,从而减少错误累积,提高识别的稳定性和准确性。
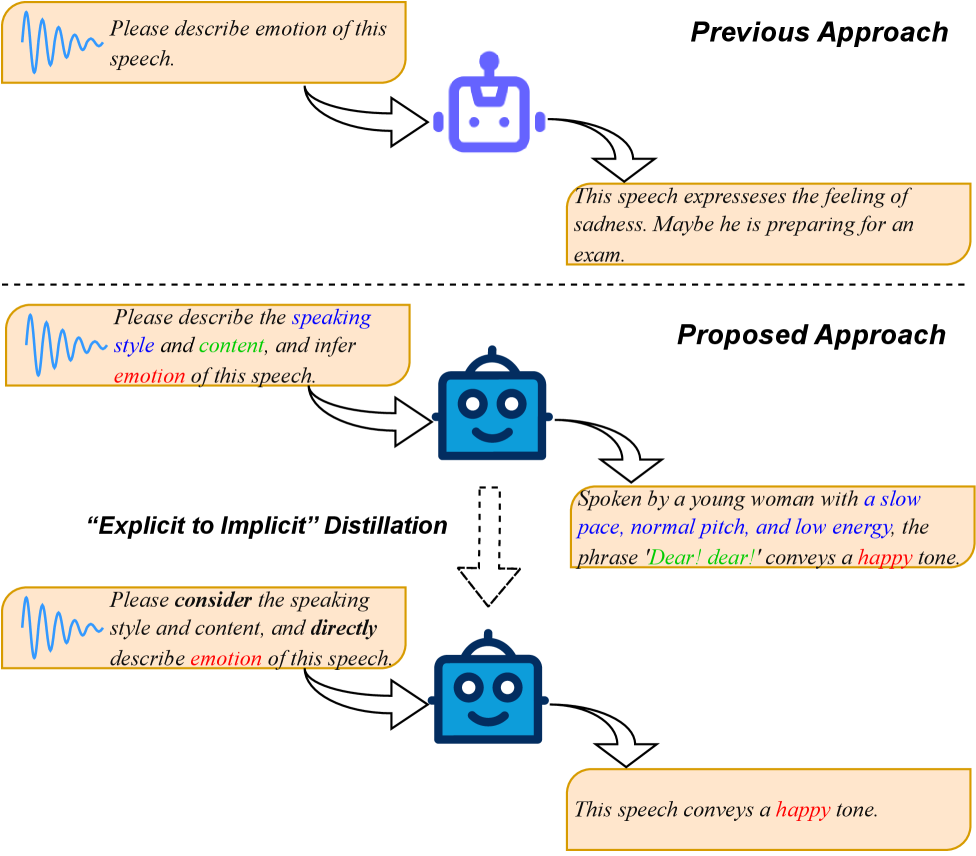
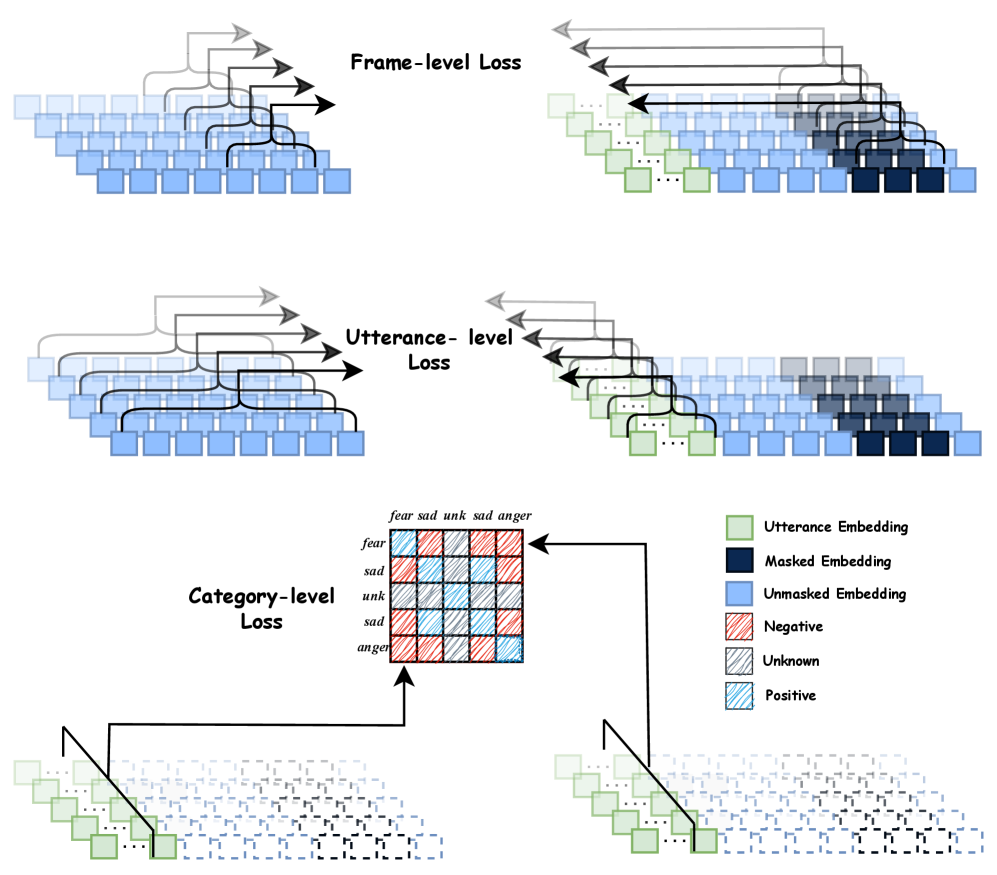
技术框架:C$^2$SER模型主要包含以下几个模块:1) Whisper编码器:用于提取语音的语义信息。2) Emotion2Vec-S:用于提取语音的声学情感特征,通过半监督学习增强情感区分能力。3) 思维链(CoT)模块:以逐步的方式处理SER,利用语音内容和说话风格进行推理。4) 自蒸馏模块:从显式CoT到隐式CoT的自蒸馏,进一步提高模型的稳定性和泛化能力。
关键创新:论文的关键创新在于将上下文感知和思维链方法相结合,并引入自蒸馏机制。通过上下文感知,模型能够更全面地理解语音信息;通过思维链,模型能够逐步推理,减少错误累积;通过自蒸馏,模型能够进一步提高稳定性和泛化能力。与现有方法相比,C$^2$SER能够更有效地抑制“幻觉”问题,提高情感识别的准确性和稳定性。
关键设计:Emotion2Vec-S通过半监督学习扩展了Emotion2Vec,具体实现细节未知。自蒸馏过程从显式CoT到隐式CoT,具体损失函数和训练策略未知。论文中未明确提及其他关键参数设置和网络结构细节。
🖼️ 关键图片

📊 实验亮点
实验结果表明,C$^2$SER模型在语音情感识别任务上优于现有的流行ALMs,如Qwen2-Audio和SECap,提供了更稳定和精确的情感识别。具体的性能提升数据未知,但论文强调了C$^2$SER在稳定性和准确性方面的优势。
🎯 应用场景
该研究成果可应用于智能客服、心理健康评估、情感计算等领域。通过准确识别语音中的情感,可以提升人机交互的自然性和智能化水平,为用户提供更个性化的服务。未来,该技术有望在医疗、教育、娱乐等领域发挥重要作用。
📄 摘要(原文)
Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.