Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
作者: Wenkai Yang, Shuming Ma, Yankai Lin, Furu Wei
分类: cs.CL, cs.AI
发布日期: 2025-02-25 (更新: 2025-10-12)
备注: Accepted at NeurIPS 2025, camera-ready version
💡 一句话要点
提出思维最优缩放策略,解决LLM推理中过度CoT长度带来的性能下降问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 思维链 推理优化 知识蒸馏 自学习
📋 核心要点
- 现有研究过度追求增加CoT长度以提升LLM推理能力,忽略了过长CoT可能导致性能下降的问题。
- 论文提出“思维最优缩放”策略,通过学习不同推理努力下的最优响应长度分布来提升模型性能。
- 实验表明,该方法在数学推理任务上优于其他蒸馏模型,并达到与教师模型相当的水平。
📝 摘要(中文)
最近的研究表明,通过更长的思维链(CoT)让模型花费更多时间思考,可以显著提高其在复杂推理任务中的性能。虽然目前的研究继续探索通过增加大型语言模型(LLM)的CoT长度来增加测试时计算的益处,但我们关注到测试时缩放背后隐藏的一个潜在问题:过度缩放CoT长度是否会对模型的推理性能产生不利影响?我们对数学推理任务的探索揭示了一个意想不到的发现,即使用更长的CoT进行缩放实际上会损害LLM在某些领域的推理性能。此外,我们发现存在一个最优的缩放长度分布,该分布因不同领域而异。基于这些见解,我们提出了一种思维最优缩放策略。我们的方法首先使用一小组具有不同响应长度分布的种子数据,来教导模型采用不同的推理努力进行深度思考。然后,模型选择其在不同推理努力下对其他问题的最短正确响应以进行自我改进。我们基于Qwen2.5-32B-Instruct构建的自我改进模型在各种数学基准测试中优于其他基于蒸馏的32B o1-like模型,并且实现了与生成种子数据的教师模型QwQ-32B-Preview相当的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理过程中,过度依赖长思维链(CoT)可能导致性能下降的问题。现有方法通常简单地增加CoT的长度以提升推理能力,但忽略了不同领域存在最优CoT长度分布,盲目增加CoT长度反而会损害性能。
核心思路:论文的核心思路是找到每个领域或任务的“思维最优”CoT长度分布。模型应该学会根据问题的难度和领域特性,采用适当的推理努力,而不是一味地增加CoT长度。通过学习不同长度CoT的有效性,模型能够选择最短且正确的答案,从而提高效率和准确性。
技术框架:整体框架包含两个主要阶段:1) 种子数据生成与训练:使用教师模型生成具有不同响应长度分布的种子数据,并用这些数据训练学生模型,使其具备采用不同推理努力的能力。2) 自改进:学生模型在额外的问题上,尝试不同的推理努力(即不同长度的CoT),并选择最短的正确答案进行自我学习和改进。
关键创新:关键创新在于提出了“思维最优缩放”的概念,即并非CoT越长越好,而是存在一个最优的CoT长度分布。通过学习这种分布,模型可以更有效地利用计算资源,提高推理性能。此外,自改进机制允许模型在没有人工干预的情况下,不断优化其推理策略。
关键设计:关键设计包括:1) 种子数据生成:使用教师模型生成具有不同CoT长度的答案,确保学生模型能够接触到各种推理路径。2) 自改进策略:学生模型选择最短正确答案作为学习目标,鼓励模型寻找最有效的推理路径。3) 损失函数:论文可能使用了某种形式的对比学习或排序损失,以鼓励模型选择更短且正确的答案,并惩罚更长或错误的答案(具体损失函数细节未知)。
🖼️ 关键图片
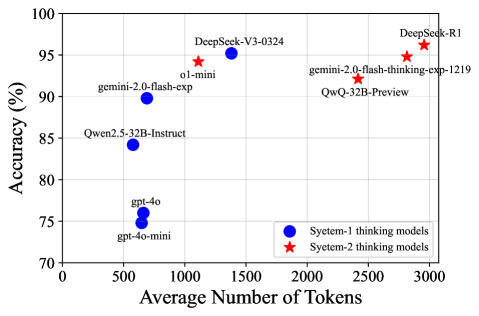
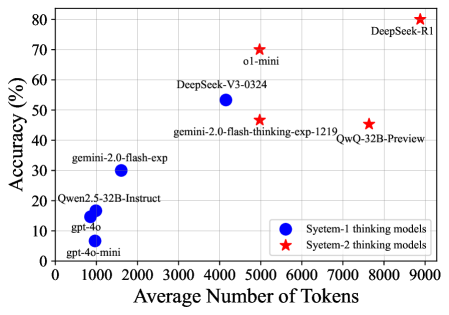
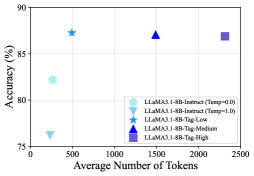
📊 实验亮点
实验结果表明,基于Qwen2.5-32B-Instruct构建的自我改进模型,在多个数学基准测试中超越了其他基于蒸馏的32B模型。更重要的是,该模型达到了与生成种子数据的教师模型QwQ-32B-Preview相当的性能水平,表明该方法能够有效地将教师模型的知识迁移到学生模型,并显著提升学生模型的推理能力。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如数学问题求解、代码生成、知识问答等。通过优化LLM的推理策略,可以提高其在资源受限环境下的性能,并降低计算成本。此外,该方法还可以推广到其他类型的推理任务,提升LLM的通用性和实用性。
📄 摘要(原文)
Recent studies have shown that making a model spend more time thinking through longer Chain of Thoughts (CoTs) enables it to gain significant improvements in complex reasoning tasks. While current researches continue to explore the benefits of increasing test-time compute by extending the CoT lengths of Large Language Models (LLMs), we are concerned about a potential issue hidden behind the current pursuit of test-time scaling: Would excessively scaling the CoT length actually bring adverse effects to a model's reasoning performance? Our explorations on mathematical reasoning tasks reveal an unexpected finding that scaling with longer CoTs can indeed impair the reasoning performance of LLMs in certain domains. Moreover, we discover that there exists an optimal scaled length distribution that differs across different domains. Based on these insights, we propose a Thinking-Optimal Scaling strategy. Our method first uses a small set of seed data with varying response length distributions to teach the model to adopt different reasoning efforts for deep thinking. Then, the model selects its shortest correct response under different reasoning efforts on additional problems for self-improvement. Our self-improved models built upon Qwen2.5-32B-Instruct outperform other distillation-based 32B o1-like models across various math benchmarks, and achieve performance on par with the teacher model QwQ-32B-Preview that produces the seed data.