Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
作者: Xinghao Chen, Zhijing Sun, Wenjin Guo, Miaoran Zhang, Yanjun Chen, Yirong Sun, Hui Su, Yijie Pan, Dietrich Klakow, Wenjie Li, Xiaoyu Shen
分类: cs.CL
发布日期: 2025-02-25 (更新: 2025-05-27)
备注: ACL 2025 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
揭示思维链蒸馏的关键因素,优化小语言模型推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 知识蒸馏 小语言模型 推理能力 模型优化
📋 核心要点
- 大型语言模型推理能力强,但计算成本高,因此需要将思维链能力蒸馏到小型模型。
- 该研究系统考察了粒度、格式、教师模型等因素对思维链蒸馏的影响,旨在优化小型语言模型的推理能力。
- 实验表明,思维链粒度与模型能力存在非单调关系,教师模型强度并非越高越好,需针对学生模型定制策略。
📝 摘要(中文)
大型语言模型(LLMs)通过思维链(CoT)提示在推理任务中表现出色。然而,CoT提示显著增加了计算需求,促使人们对将CoT能力提炼到小型语言模型(SLMs)中越来越感兴趣。本研究系统地考察了影响CoT蒸馏的因素,包括粒度、格式和教师模型的选择。通过涉及四个教师模型和七个学生模型,跨越七个数学和常识推理数据集的实验,我们发现了三个关键发现:(1)与LLM不同,SLM与粒度之间呈现非单调关系,较强的模型受益于更细粒度的推理,而较弱的模型在更简单的CoT监督下表现更好;(2)CoT格式对LLM有显著影响,但对SLM的影响极小,这可能是由于它们依赖于监督微调而不是预训练偏好;(3)更强的教师模型并不总是产生更好的学生模型,因为CoT监督的多样性和复杂性可能超过准确性本身。这些发现强调需要根据特定的学生模型定制CoT策略,为优化SLM中的CoT蒸馏提供可操作的见解。代码和数据集可在https://github.com/EIT-NLP/Distilling-CoT-Reasoning获得。
🔬 方法详解
问题定义:论文旨在解决如何有效地将大型语言模型(LLM)的思维链(CoT)推理能力迁移到小型语言模型(SLM)的问题。现有方法在直接应用LLM的CoT策略到SLM时效果不佳,因为SLM的容量和学习机制与LLM存在差异。现有方法未能充分考虑SLM的特性,导致蒸馏效果不理想。
核心思路:论文的核心思路是针对SLM的特点,系统性地研究影响CoT蒸馏的关键因素,包括CoT的粒度、格式以及教师模型的选择。通过实验分析这些因素与SLM性能之间的关系,从而为SLM定制更有效的CoT蒸馏策略。
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择多个具有不同规模和能力的教师模型和学生模型;2) 在多个数学和常识推理数据集上进行实验;3) 针对不同的CoT粒度(粗粒度和细粒度)和格式进行实验;4) 分析不同教师模型对学生模型性能的影响;5) 最终得出关于如何为SLM选择最佳CoT蒸馏策略的结论。
关键创新:论文的关键创新在于:1) 揭示了SLM与CoT粒度之间的非单调关系,即较强的SLM受益于更细粒度的推理,而较弱的SLM在更简单的CoT监督下表现更好;2) 发现CoT格式对LLM有显著影响,但对SLM的影响极小,这可能是由于SLM依赖于监督微调;3) 证明更强的教师模型并不总是产生更好的学生模型,CoT监督的多样性和复杂性可能更重要。
关键设计:论文的关键设计包括:1) 选择了多种不同规模和架构的教师模型和学生模型,以保证实验结果的泛化性;2) 采用了多个数学和常识推理数据集,以评估CoT蒸馏在不同任务上的效果;3) 通过控制变量法,分别研究了CoT粒度、格式和教师模型对SLM性能的影响;4) 使用标准的监督微调方法训练学生模型,并使用准确率作为评估指标。
🖼️ 关键图片

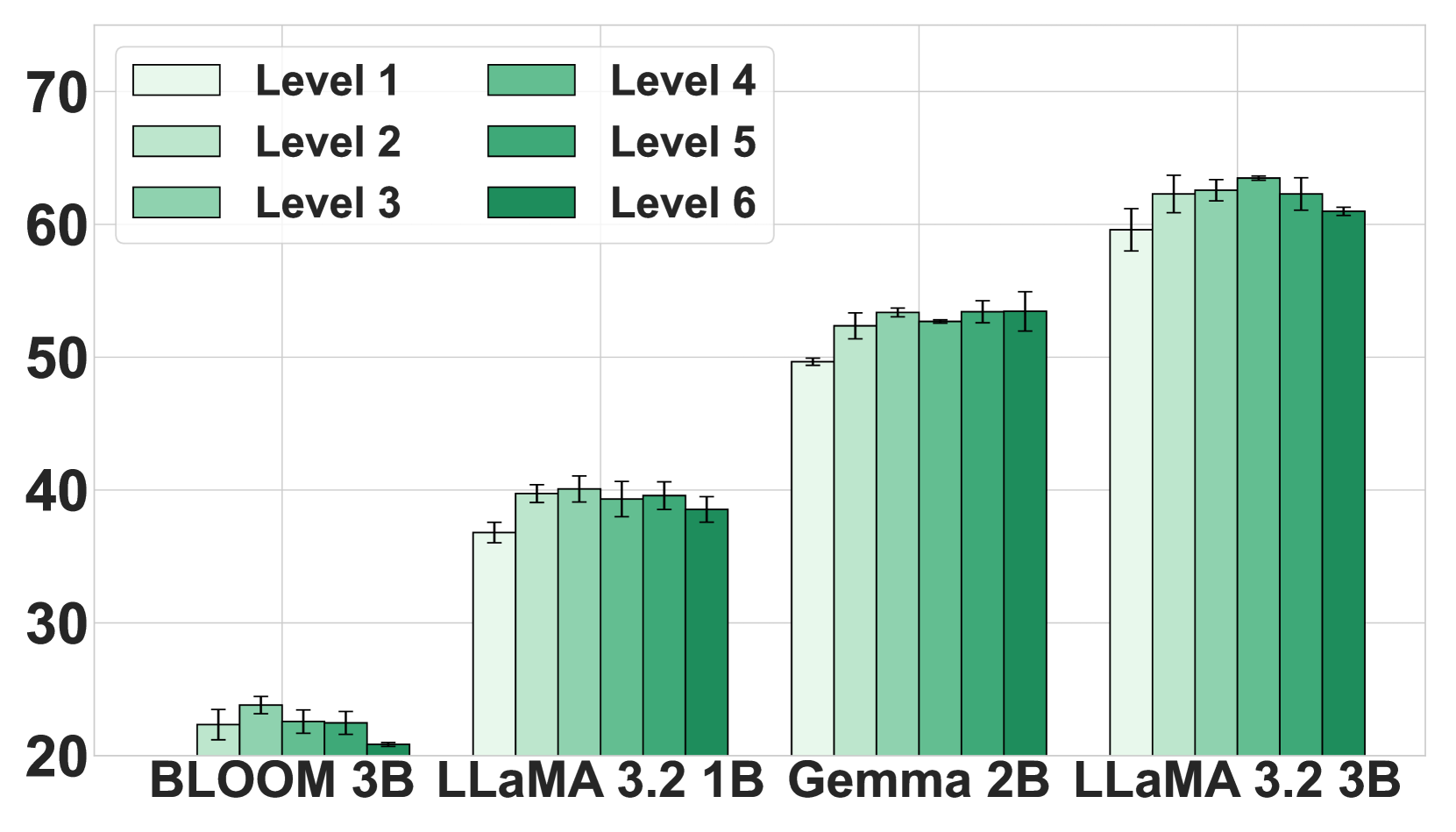
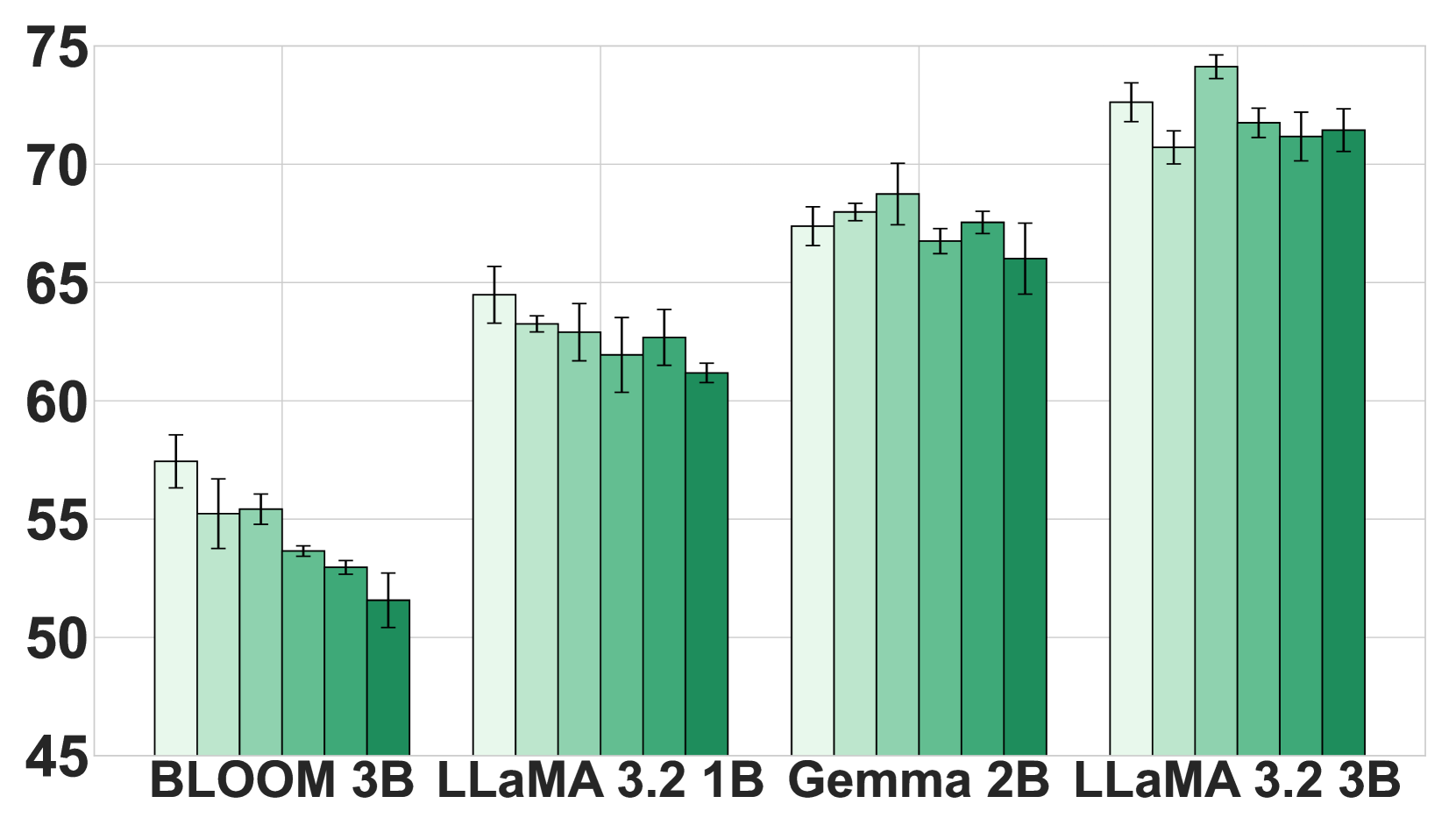
📊 实验亮点
实验结果表明,对于SLM,CoT粒度与模型性能之间存在非单调关系。具体来说,更强的SLM模型在细粒度CoT监督下表现更好,而较弱的SLM模型在粗粒度CoT监督下表现更好。此外,CoT格式对LLM的影响显著,但对SLM的影响很小。更重要的是,更强的教师模型并不总是能产生更好的学生模型,CoT监督的多样性和复杂性可能比准确性更重要。
🎯 应用场景
该研究成果可应用于各种需要小型化、低功耗的智能设备和应用场景,例如移动设备、嵌入式系统、边缘计算等。通过将大型语言模型的推理能力蒸馏到小型模型中,可以在资源受限的环境下实现复杂的推理任务,提升用户体验和应用性能。未来可进一步探索自适应的CoT蒸馏策略,根据设备和任务特点动态调整蒸馏参数。
📄 摘要(原文)
Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.