Sparsity May Be All You Need: Sparse Random Parameter Adaptation
作者: Jesus Rios, Pierre Dognin, Ronny Luss, Karthikeyan N. Ramamurthy
分类: cs.CL, cs.AI
发布日期: 2025-02-21 (更新: 2025-09-19)
💡 一句话要点
提出稀疏随机参数微调方法,在参数效率微调中与LoRA具有竞争力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 稀疏训练 大型语言模型 随机参数选择 LoRA
📋 核心要点
- 大型语言模型全参数微调成本高昂,参数高效微调(PEFT)旨在降低计算和内存需求。
- 论文提出稀疏随机参数微调,即随机选择少量参数进行训练,无需低秩等额外假设。
- 实验表明,在相似可训练参数量下,该方法与LoRA具有竞争力,表明参数量是关键。
📝 摘要(中文)
随着模型规模的增长,对大型语言模型进行完全微调以进行对齐和任务适配变得非常昂贵。参数高效微调(PEFT)方法旨在通过仅训练少量参数而非所有模型参数,来显著减少微调这些模型所需的计算和内存资源。目前,最流行的PEFT方法是低秩适应(LoRA),它冻结模型的参数,并以低秩矩阵的形式引入一小组可训练参数。我们提出简单地减少可训练参数的数量,随机选择一小部分模型参数进行训练,同时固定所有其他参数,而没有任何额外的先验假设,例如低秩结构。在本文中,我们将我们提出的方法的效率和性能与其他PEFT方法以及全参数微调进行比较。我们发现,当使用相似数量的可训练参数时,我们的方法与LoRA具有竞争力。我们的研究结果表明,对于PEFT技术而言,真正重要的是可训练参数的数量,而不是特定的适配器结构。
🔬 方法详解
问题定义:论文旨在解决大型语言模型微调过程中计算资源和内存需求过高的问题。现有方法,如全参数微调,成本巨大。而参数高效微调(PEFT)方法虽然减少了计算量,但现有方法(如LoRA)依赖于特定的结构假设(如低秩),这可能限制了模型的表达能力。
核心思路:论文的核心思路是,在PEFT中,真正重要的是可训练参数的数量,而不是特定的适配器结构。因此,论文提出了一种简单直接的方法:随机选择一小部分模型参数进行训练,而固定其余参数。这种方法避免了对参数结构的任何先验假设,从而可能更灵活地适应不同的任务。
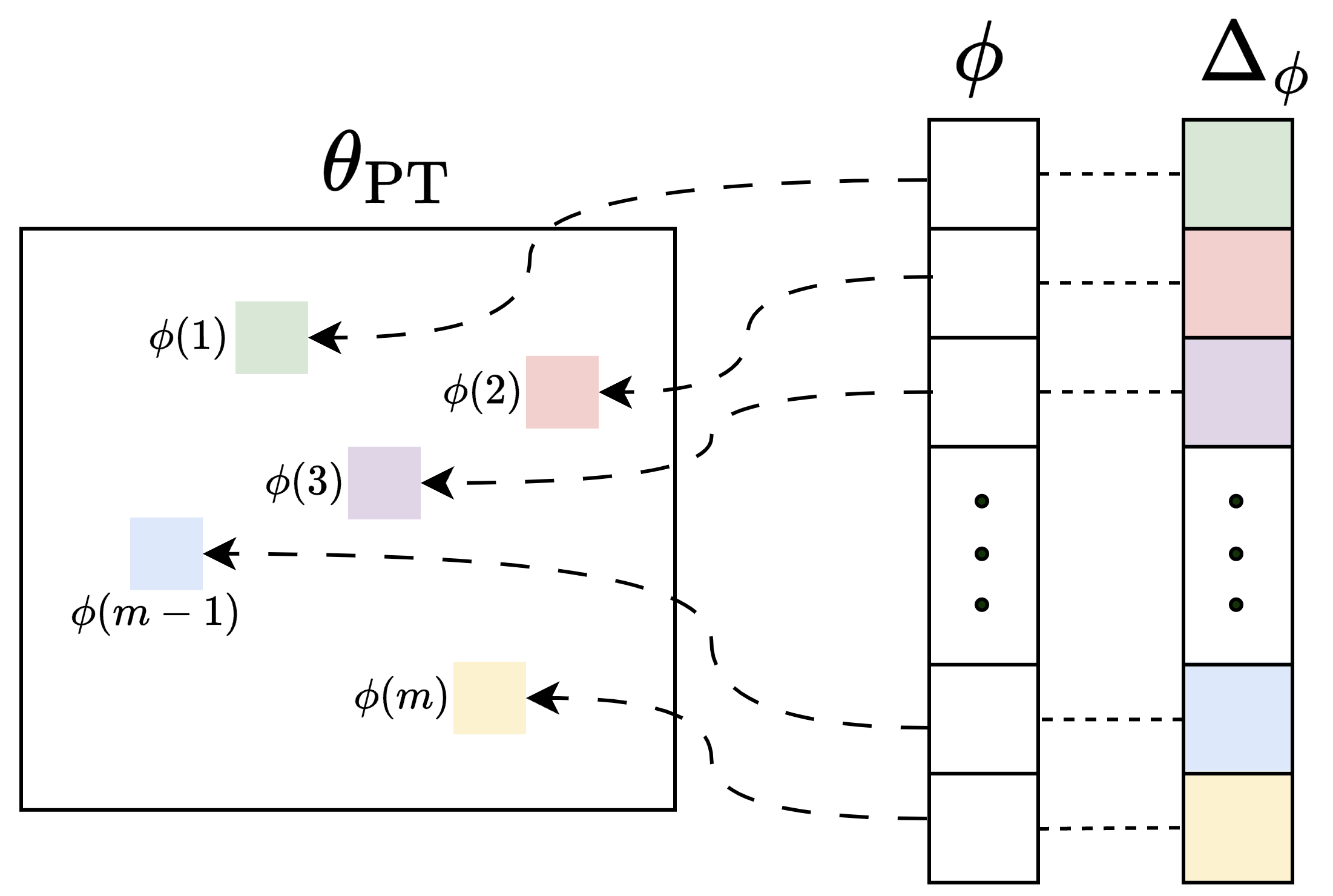
技术框架:该方法无需复杂的架构设计。首先,确定需要微调的模型。然后,随机选择模型中的一小部分参数作为可训练参数,其余参数保持固定。在训练过程中,只更新选定的可训练参数。推理阶段,直接使用微调后的模型进行预测。
关键创新:该方法最重要的创新点在于其简洁性和有效性。它挑战了现有PEFT方法对特定参数结构的依赖,表明随机选择少量参数进行训练也能达到与复杂方法相当的性能。这种方法的本质区别在于,它没有引入任何额外的结构或假设,而是直接在原始模型参数上进行稀疏更新。
关键设计:关键设计在于可训练参数的比例。论文通过实验探索了不同比例的可训练参数对模型性能的影响。此外,论文还研究了不同的随机选择策略,以确保选取的参数具有代表性。损失函数和优化器与标准微调过程相同,没有特别的设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在相似的可训练参数数量下,该方法与LoRA等主流PEFT方法具有竞争力。这表明,对于PEFT而言,可训练参数的数量可能比特定的适配器结构更重要。该发现为未来的PEFT研究提供了新的方向。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行微调的场景,例如自然语言处理、机器翻译、文本生成等。该方法降低了微调成本,使得在资源受限的环境下也能高效地进行模型定制,加速了AI技术的普及。
📄 摘要(原文)
Full fine-tuning of large language models for alignment and task adaptation has become prohibitively expensive as models have grown in size. Parameter-Efficient Fine-Tuning (PEFT) methods aim at significantly reducing the computational and memory resources needed for fine-tuning these models by only training on a small number of parameters instead of all model parameters. Currently, the most popular PEFT method is the Low-Rank Adaptation (LoRA), which freezes the parameters of the model and introduces a small set of trainable parameters in the form of low-rank matrices. We propose simply reducing the number of trainable parameters by randomly selecting a small proportion of the model parameters to train on, while fixing all other parameters, without any additional prior assumptions such as low-rank structures. In this paper, we compare the efficiency and performance of our proposed approach to other PEFT methods as well as full parameter fine-tuning. We find our method to be competitive with LoRA when using a similar number of trainable parameters. Our findings suggest that what truly matters for a PEFT technique to perform well is not necessarily the specific adapter structure, but rather the number of trainable parameters being used.