Self-Taught Agentic Long Context Understanding
作者: Yufan Zhuang, Xiaodong Yu, Jialian Wu, Ximeng Sun, Ze Wang, Jiang Liu, Yusheng Su, Jingbo Shang, Zicheng Liu, Emad Barsoum
分类: cs.CL, cs.AI
发布日期: 2025-02-21 (更新: 2025-05-28)
备注: Published at ACL 2025 Main Conference
💡 一句话要点
提出AgenticLU框架,通过自学习Agent提升LLM在长文本理解中的问答能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 Agentic框架 自澄清 上下文检索 多跳推理 语言模型 问题回答
📋 核心要点
- 现有LLM在长文本问答中面临挑战,难以有效进行问题澄清和上下文检索。
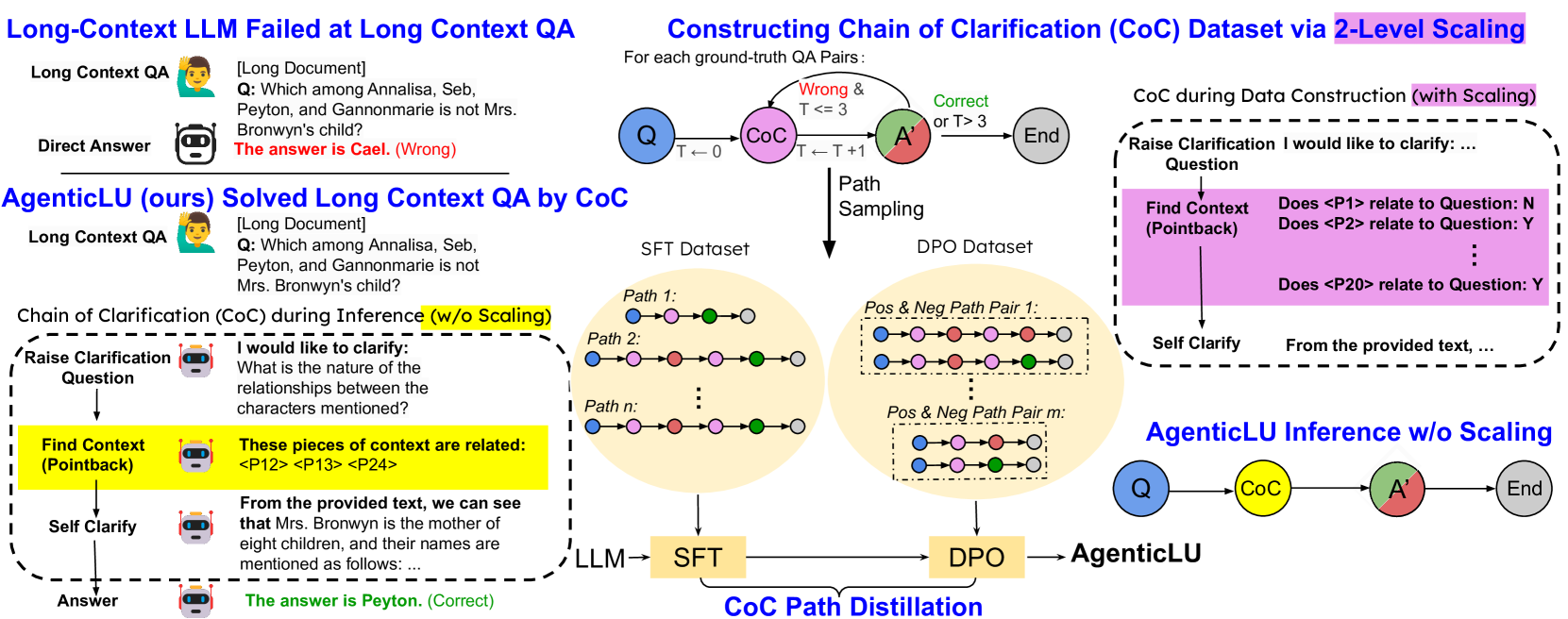
- AgenticLU框架通过集成自澄清和上下文 grounding,提升LLM对长文本的理解能力。
- 实验表明,AgenticLU在多个长文本任务中显著优于现有方法,实现更强的多跳推理。
📝 摘要(中文)
本文提出Agentic Long-Context Understanding (AgenticLU) 框架,旨在通过在Agent工作流中集成有针对性的自澄清和上下文 grounding,来增强大型语言模型(LLM)对复杂、长文本问题的理解。AgenticLU 的核心是 Chain-of-Clarifications (CoC),模型通过自生成的澄清问题和相应的上下文 grounding 来完善其理解。通过将推理扩展为树搜索,其中每个节点代表一个 CoC 步骤,在 NarrativeQA 上实现了 97.8% 的答案召回率,搜索深度高达 3,分支因子为 8。为了分摊这种搜索过程的高成本到训练中,我们利用 CoC 工作流获得的每个步骤的偏好对,并执行两阶段模型微调:(1)监督微调以学习有效的分解策略,以及(2)直接偏好优化以提高推理质量。这使得 AgenticLU 模型能够在单个推理过程中有效且高效地生成澄清并检索相关上下文。在七个长文本任务中的大量实验表明,AgenticLU 显著优于最先进的提示方法和专门的长文本 LLM,实现了强大的多跳推理,同时保持了随着上下文长度增长的一致性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理复杂、长文本上下文问题时,难以有效进行问题澄清和上下文检索的难题。现有方法通常依赖于简单的提示工程或专门的长文本模型,但这些方法在多跳推理和处理不断增长的上下文长度时表现不佳。
核心思路:论文的核心思路是构建一个Agentic框架,通过模拟人类的提问和澄清过程,让LLM能够主动地理解问题并检索相关上下文。该框架通过Chain-of-Clarifications (CoC)机制,使模型能够自生成澄清问题,并基于上下文进行 grounding,从而逐步完善对问题的理解。
技术框架:AgenticLU框架包含以下主要模块:1) Chain-of-Clarifications (CoC):模型通过自生成澄清问题和上下文 grounding 来完善理解。2) 树搜索推理:将推理过程扩展为树搜索,每个节点代表一个CoC步骤,通过搜索最优路径来获得最终答案。3) 两阶段模型微调:首先进行监督微调,学习有效的分解策略;然后进行直接偏好优化,提高推理质量。
关键创新:AgenticLU的关键创新在于其Agentic设计,它允许模型主动地进行问题澄清和上下文检索,而不是被动地接受输入。此外,CoC机制和树搜索推理的结合,使得模型能够进行更深入的多跳推理,并有效地处理长文本上下文。
关键设计:CoC过程中的澄清问题生成和上下文检索模块,使用了特定的提示工程和微调策略,以确保生成的问题具有针对性,并且检索到的上下文与问题相关。两阶段微调过程中的损失函数设计,旨在平衡分解策略的学习和推理质量的提升。树搜索的深度和分支因子是影响性能的关键参数,需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
AgenticLU在NarrativeQA上实现了97.8%的答案召回率,显著优于现有方法。在七个长文本任务上的实验表明,AgenticLU不仅优于最先进的提示方法,也超越了专门的长文本LLM,并且在上下文长度增长时保持了稳定的性能。
🎯 应用场景
AgenticLU框架可应用于各种需要处理长文本上下文的问答场景,例如法律文档分析、医学报告解读、金融研报分析等。该框架能够提升LLM在这些领域的应用效果,帮助用户更准确、高效地获取所需信息,并辅助决策。
📄 摘要(原文)
Answering complex, long-context questions remains a major challenge for large language models (LLMs) as it requires effective question clarifications and context retrieval. We propose Agentic Long-Context Understanding (AgenticLU), a framework designed to enhance an LLM's understanding of such queries by integrating targeted self-clarification with contextual grounding within an agentic workflow. At the core of AgenticLU is Chain-of-Clarifications (CoC), where models refine their understanding through self-generated clarification questions and corresponding contextual groundings. By scaling inference as a tree search where each node represents a CoC step, we achieve 97.8% answer recall on NarrativeQA with a search depth of up to three and a branching factor of eight. To amortize the high cost of this search process to training, we leverage the preference pairs for each step obtained by the CoC workflow and perform two-stage model finetuning: (1) supervised finetuning to learn effective decomposition strategies, and (2) direct preference optimization to enhance reasoning quality. This enables AgenticLU models to generate clarifications and retrieve relevant context effectively and efficiently in a single inference pass. Extensive experiments across seven long-context tasks demonstrate that AgenticLU significantly outperforms state-of-the-art prompting methods and specialized long-context LLMs, achieving robust multi-hop reasoning while sustaining consistent performance as context length grows.