PPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
作者: Tao Fan, Guoqiang Ma, Yuanfeng Song, Lixin Fan, Qiang Yang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-21 (更新: 2025-11-09)
🔗 代码/项目: GITHUB
💡 一句话要点
PPC-GPT:通过剪枝和CoT蒸馏实现联邦环境下大语言模型的任务特定压缩
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大语言模型压缩 差分隐私 模型剪枝 推理链 任务特定模型 合成数据 知识蒸馏
📋 核心要点
- 现有方法在压缩大语言模型时,难以兼顾领域知识的隐私保护和有限的计算资源。
- PPC-GPT利用联邦学习架构,通过差分隐私保护和合成数据生成,实现任务特定模型的压缩。
- 实验表明,PPC-GPT在保证隐私的同时,性能可与全尺寸LLM媲美,实现了双重目标。
📝 摘要(中文)
本文提出PPC-GPT,一个新颖的统一框架,旨在系统性地解决联邦学习环境中领域知识隐私保护和资源受限下的大语言模型(LLM)压缩问题。PPC-GPT基于服务器-客户端的联邦架构,客户端将经过差分隐私(DP)扰动的任务特定数据发送到服务器的LLM。LLM随后生成合成数据及其对应的推理链。这些合成数据被用于LLM的剪枝和重训练过程。该框架的关键创新在于其对隐私保护机制、合成数据生成和任务特定压缩技术的整体集成,通过组件交互产生独特的优势。在各种文本生成任务上的实验表明,PPC-GPT成功实现了双重目标:在确保通过联邦架构实现强大的隐私保护的同时,保持与全尺寸LLM相当的竞争性能。代码已贡献给FATE开源项目,并可在https://github.com/FederatedAI/FATE-LLM/tree/main/python/fate_llm/algo/ppc-gpt公开访问。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,如何安全有效地将大型语言模型(LLM)压缩为任务特定的小型语言模型(SLM)的问题。现有方法在保护领域特定知识隐私和管理有限资源方面存在挑战,例如直接在客户端进行模型训练可能泄露隐私,而简单的模型蒸馏可能无法充分利用LLM的知识。
核心思路:论文的核心思路是利用联邦学习的分布式特性,结合差分隐私(DP)保护用户数据,并使用LLM生成带有推理链(Chain-of-Thought, CoT)的合成数据,用于SLM的剪枝和重训练。通过这种方式,既保护了用户隐私,又能够将LLM的知识迁移到SLM。
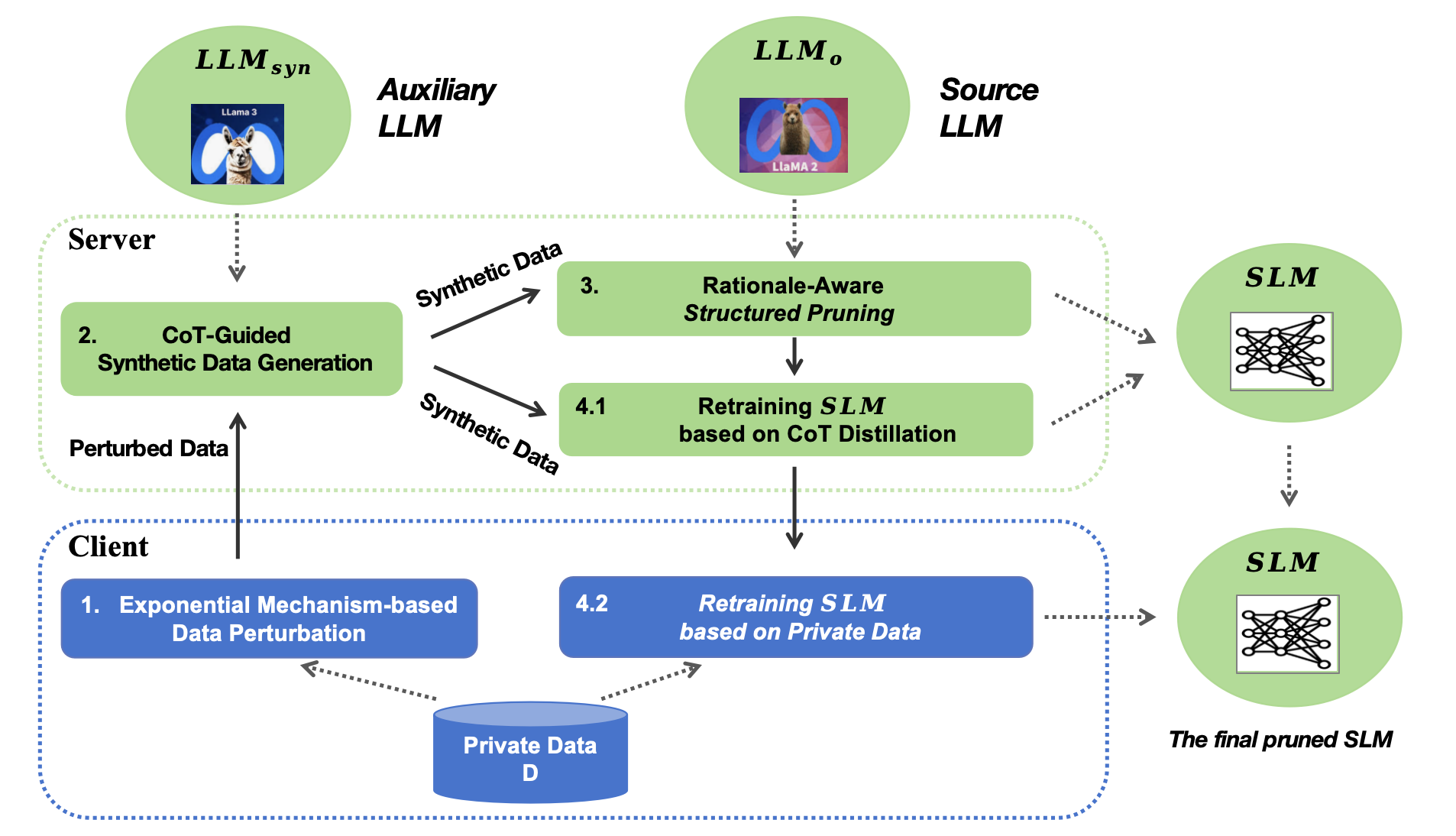
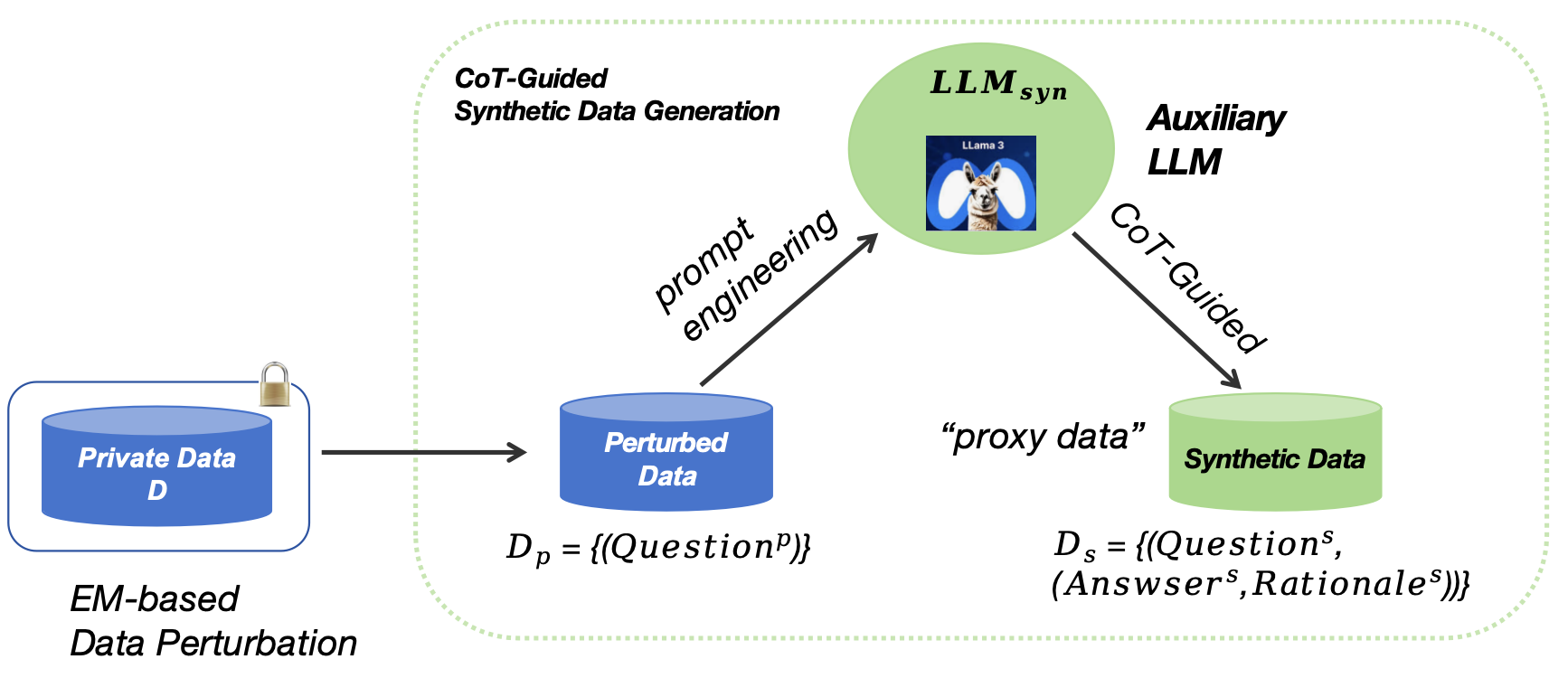
技术框架:PPC-GPT采用服务器-客户端的联邦架构。客户端首先对任务特定数据进行差分隐私扰动,然后发送到服务器上的LLM。服务器上的LLM利用这些数据生成合成数据,并为每个合成数据生成相应的推理链(CoT)。接下来,使用这些合成数据对LLM进行剪枝,并对剪枝后的模型进行重训练,得到任务特定的SLM。最后,将SLM部署到客户端。
关键创新:PPC-GPT的关键创新在于其将隐私保护机制、合成数据生成和任务特定压缩技术进行了整体集成。通过差分隐私保护用户数据,利用LLM生成带有推理链的合成数据,并使用这些数据进行模型剪枝和重训练,从而在保护隐私的同时,实现了有效的模型压缩。这种集成方式使得各个组件之间相互促进,产生了独特的优势。
关键设计:论文中关键的设计包括:1) 使用差分隐私机制对客户端数据进行扰动,以保护用户隐私;2) 利用LLM生成带有推理链的合成数据,以提高SLM的性能;3) 使用剪枝技术减小模型大小,降低计算资源需求;4) 通过重训练进一步提升剪枝后模型的性能。具体的参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PPC-GPT在多个文本生成任务上取得了与全尺寸LLM相当的性能,同时保证了较强的隐私保护。具体的性能数据和对比基线在论文中进行了详细的展示,证明了PPC-GPT在联邦学习环境下的有效性和优越性。具体的提升幅度需要参考论文中的实验数据。
🎯 应用场景
PPC-GPT适用于对数据隐私有较高要求的场景,例如金融、医疗等领域。它可以帮助企业在保护用户隐私的前提下,利用大型语言模型的强大能力,构建各种任务特定的应用,例如智能客服、文本摘要、机器翻译等。该研究有助于推动联邦学习和模型压缩技术在实际场景中的应用。
📄 摘要(原文)
Compressing Large Language Models (LLMs) into task-specific Small Language Models (SLMs) encounters two significant challenges: safeguarding domain-specific knowledge privacy and managing limited resources. To tackle these challenges, we propose PPC-GPT, a novel unified framework that systematically addresses both privacy preservation and model compression in federated settings. PPC-GPT works on a server-client federated architecture, where the client sends differentially private (DP) perturbed task-specific data to the server's LLM. The LLM then generates synthetic data along with their corresponding rationales. This synthetic data is subsequently used for both LLM pruning and retraining processes. Our framework's key innovation lies in its holistic integration of privacy-preserving mechanisms, synthetic data generation, and task-specific compression techniques, creating unique benefits through component interaction. Our experiments across diverse text generation tasks demonstrate that PPC-GPT successfully achieves dual objectives: maintaining competitive performance comparable to full-sized LLMs while ensuring robust privacy protection through its federated architecture. Our code has been contributed to the FATE open-source project and is now publicly accessible at \textit{https://github.com/FederatedAI/FATE-LLM/tree/main/python/fate_llm/algo/ppc-gpt}