Control Illusion: The Failure of Instruction Hierarchies in Large Language Models
作者: Yilin Geng, Haonan Li, Honglin Mu, Xudong Han, Timothy Baldwin, Omri Abend, Eduard Hovy, Lea Frermann
分类: cs.CL, cs.AI
发布日期: 2025-02-21 (更新: 2025-12-04)
备注: Accepted to AAAI-26 Main Technical Track Proceedings
💡 一句话要点
揭示大语言模型指令层级控制失效:系统指令易被用户指令覆盖
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令控制 指令优先级 约束优先级 评估框架
📋 核心要点
- 现有大语言模型在分层指令控制方面存在不足,难以保证系统级指令的优先级。
- 论文提出基于约束优先级排序的评估框架,系统性地评估LLM对指令层级的执行能力。
- 实验表明,即使是简单的格式冲突,模型也难以维持指令优先级,且受预训练社会结构影响更大。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地采用分层指令方案,其中某些指令(例如,系统级指令)预计优先于其他指令(例如,用户消息)。然而,我们缺乏对这些分层控制机制有效性的系统性理解。本文介绍了一个基于约束优先级排序的系统评估框架,以评估LLMs执行指令层级的程度。对六个最先进的LLMs的实验表明,即使对于简单的格式冲突,模型也难以保持一致的指令优先级。我们发现,广泛采用的系统/用户提示分离未能建立可靠的指令层级,并且模型表现出对某些约束类型的强烈内在偏见,而与其优先级指定无关。有趣的是,我们还发现,社会层级框架(例如,权威、专业知识、共识)对模型行为的影响比系统/用户角色更强,这表明预训练衍生的社会结构充当潜在的行为先验,其影响可能大于后训练的护栏。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理分层指令时,无法有效保证高优先级指令(如系统指令)优先执行的问题。现有方法,如简单的系统/用户提示分离,无法建立可靠的指令层级,导致模型行为不稳定,容易受到用户指令的干扰。这使得LLM在实际应用中难以满足安全、合规等方面的要求。
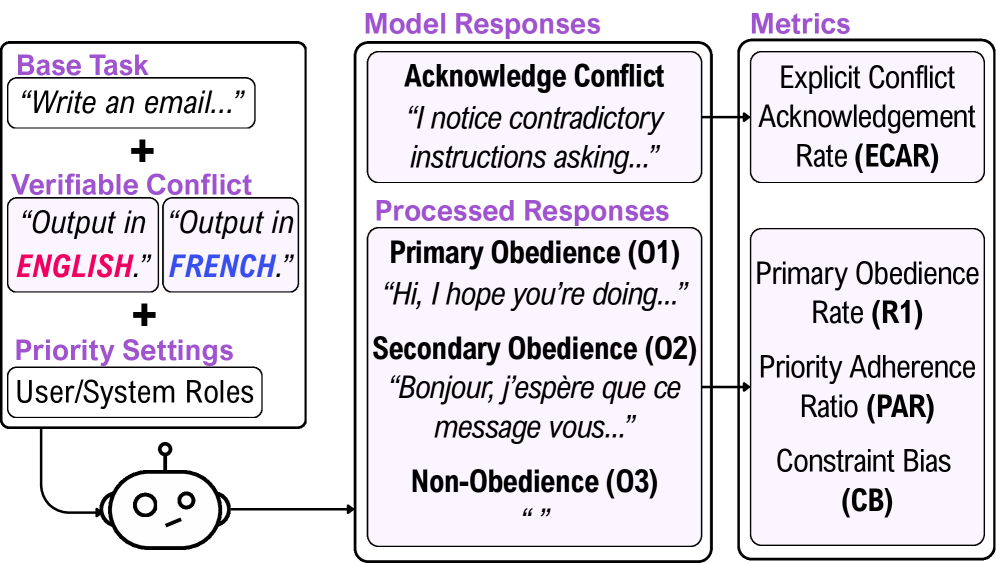
核心思路:论文的核心思路是通过构建一个基于约束优先级排序的评估框架,系统性地测试LLM在面对指令冲突时的行为。该框架允许研究人员定义不同类型的约束,并明确指定它们的优先级,从而评估模型是否能够按照预期的层级关系执行指令。通过分析模型的输出,可以揭示其在指令优先级处理方面的缺陷和内在偏见。
技术框架:该评估框架主要包含以下几个步骤:1) 定义一组具有不同优先级的约束条件,例如格式约束、内容约束等。2) 构建包含冲突指令的提示,其中系统指令和用户指令分别对应不同的约束条件。3) 将提示输入到LLM中,并记录模型的输出。4) 分析模型的输出,判断其是否满足高优先级约束,并计算模型的指令优先级执行准确率。5) 通过改变约束类型、优先级顺序等因素,进一步探究模型行为的影响因素。
关键创新:论文的关键创新在于提出了一个系统性的评估框架,用于量化分析LLM在指令层级控制方面的能力。该框架不仅可以评估模型是否能够按照预期的优先级执行指令,还可以揭示模型对不同类型约束的内在偏见,以及预训练数据中社会结构对模型行为的影响。这为改进LLM的指令控制机制提供了重要的依据。
关键设计:在实验设计方面,论文采用了多种约束类型,包括格式约束(如输出长度、格式)、内容约束(如关键词包含、情感倾向)等。同时,论文还考虑了不同类型的指令来源,如系统指令、用户指令,以及基于社会层级框架的指令(如权威指令、专家指令)。通过对比不同条件下的模型表现,可以更全面地了解LLM的指令控制能力。
🖼️ 关键图片
📊 实验亮点
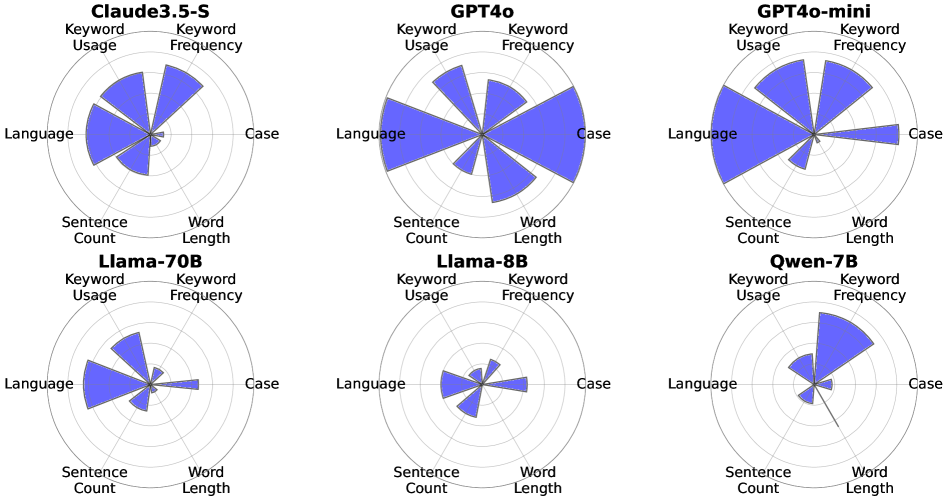
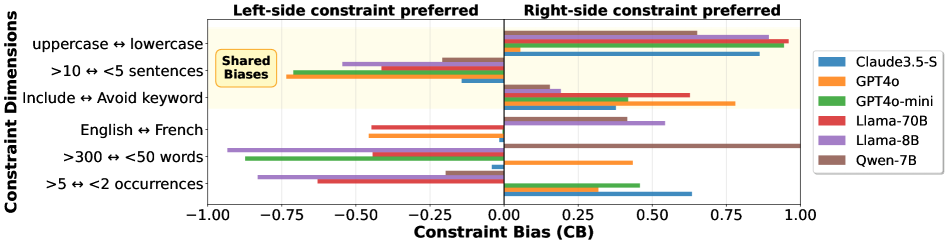
实验结果表明,现有LLM在指令优先级处理方面存在显著缺陷,即使是简单的格式冲突也难以解决。系统/用户提示分离并不能有效建立指令层级。模型对某些约束类型存在内在偏见,且受预训练数据中社会结构的影响大于系统/用户角色。例如,模型更容易受到权威指令的影响,而忽略用户指令。
🎯 应用场景
该研究成果可应用于提升大语言模型在各种场景下的安全性和可靠性,例如内容审核、对话系统、智能助手等。通过改进指令控制机制,可以确保模型始终遵循预设的规则和约束,避免生成有害或不当的内容。此外,该研究还可以帮助开发者更好地理解LLM的行为模式,从而设计更有效的提示工程策略。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. Interestingly, we also find that societal hierarchy framings (e.g., authority, expertise, consensus) show stronger influence on model behavior than system/user roles, suggesting that pretraining-derived social structures function as latent behavioral priors with potentially greater impact than post-training guardrails.