SafeInt: Shielding Large Language Models from Jailbreak Attacks via Safety-Aware Representation Intervention
作者: Jiaqi Wu, Chen Chen, Chunyan Hou, Xiaojie Yuan
分类: cs.CL
发布日期: 2025-02-21 (更新: 2025-05-23)
💡 一句话要点
SafeInt:通过安全感知表示干预防御大语言模型的越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 越狱攻击防御 表示干预 安全感知 对抗攻击
📋 核心要点
- 现有防御方法在防御大语言模型越狱攻击时,难以兼顾有效性和效率。
- SafeInt的核心思想是将越狱相关的表示重新定位到拒绝区域,通过安全感知的表示干预实现防御。
- 实验表明,SafeInt在防御越狱攻击方面优于基线方法,同时保持了模型效用,并能有效应对自适应攻击。
📝 摘要(中文)
随着大型语言模型(LLM)在现实世界中的广泛部署,确保其行为符合安全标准至关重要。越狱攻击利用LLM中的漏洞来诱导不良行为,对LLM的安全性构成重大威胁。以往的防御方法往往无法同时兼顾有效性和效率。从表示学习角度的防御提供了新的见解,但现有的干预措施无法根据查询的有害程度动态调整表示。为了解决这个限制,我们提出了一种新的防御方法SafeIntervention (SafeInt),它通过安全感知表示干预来保护LLM免受越狱攻击。基于我们对越狱样本表示的分析,SafeInt的核心思想是将越狱相关的表示重新定位到拒绝区域。这通过干预越狱样本的表示分布,使其与不安全样本的表示分布对齐来实现。我们进行了全面的实验,涵盖六种越狱攻击、两个越狱数据集和两个效用基准。实验结果表明,SafeInt在防御LLM免受越狱攻击方面优于所有基线,同时在很大程度上保持了效用。此外,我们评估了SafeInt对自适应攻击的防御能力,并验证了其在缓解实时攻击方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)容易受到越狱攻击的问题。现有的防御方法通常在有效性和效率之间做出妥协,或者无法根据查询的有害程度动态调整表示,导致防御效果不佳。越狱攻击会诱导LLM产生不安全或有害的输出,对LLM的实际应用构成严重威胁。
核心思路:SafeInt的核心思路是,通过分析越狱样本的表示,发现其与安全样本的表示存在差异。因此,可以通过干预越狱样本的表示,使其向不安全样本的表示靠近,从而将越狱相关的表示“驱逐”到拒绝区域,达到防御越狱攻击的目的。这种方法的核心在于“安全感知”,即根据输入样本的安全性动态调整干预策略。
技术框架:SafeInt的整体框架包含以下几个主要步骤:1) 表示提取:从LLM中提取输入样本的表示向量。2) 安全评估:评估输入样本的安全程度,例如通过分类器判断是否为越狱攻击。3) 表示干预:根据安全评估结果,对表示向量进行干预,使其向不安全样本的表示靠近。4) 输出生成:将干预后的表示输入LLM,生成最终输出。
关键创新:SafeInt的关键创新在于其安全感知的表示干预机制。与以往的静态干预方法不同,SafeInt能够根据输入样本的安全性动态调整干预强度和方向,从而更有效地防御越狱攻击。此外,SafeInt通过将越狱相关的表示重新定位到拒绝区域,避免了直接修改LLM的参数,降低了对模型原有功能的损害。
关键设计:SafeInt的关键设计包括:1) 安全评估模块:可以使用分类器或启发式规则来判断输入样本是否为越狱攻击。2) 表示干预策略:可以使用线性变换、非线性变换或对抗训练等方法来干预表示向量。3) 拒绝区域定义:需要定义一个拒绝区域,用于存放越狱相关的表示。具体实现中,可能需要调整干预强度、损失函数权重等参数,以达到最佳的防御效果。
🖼️ 关键图片
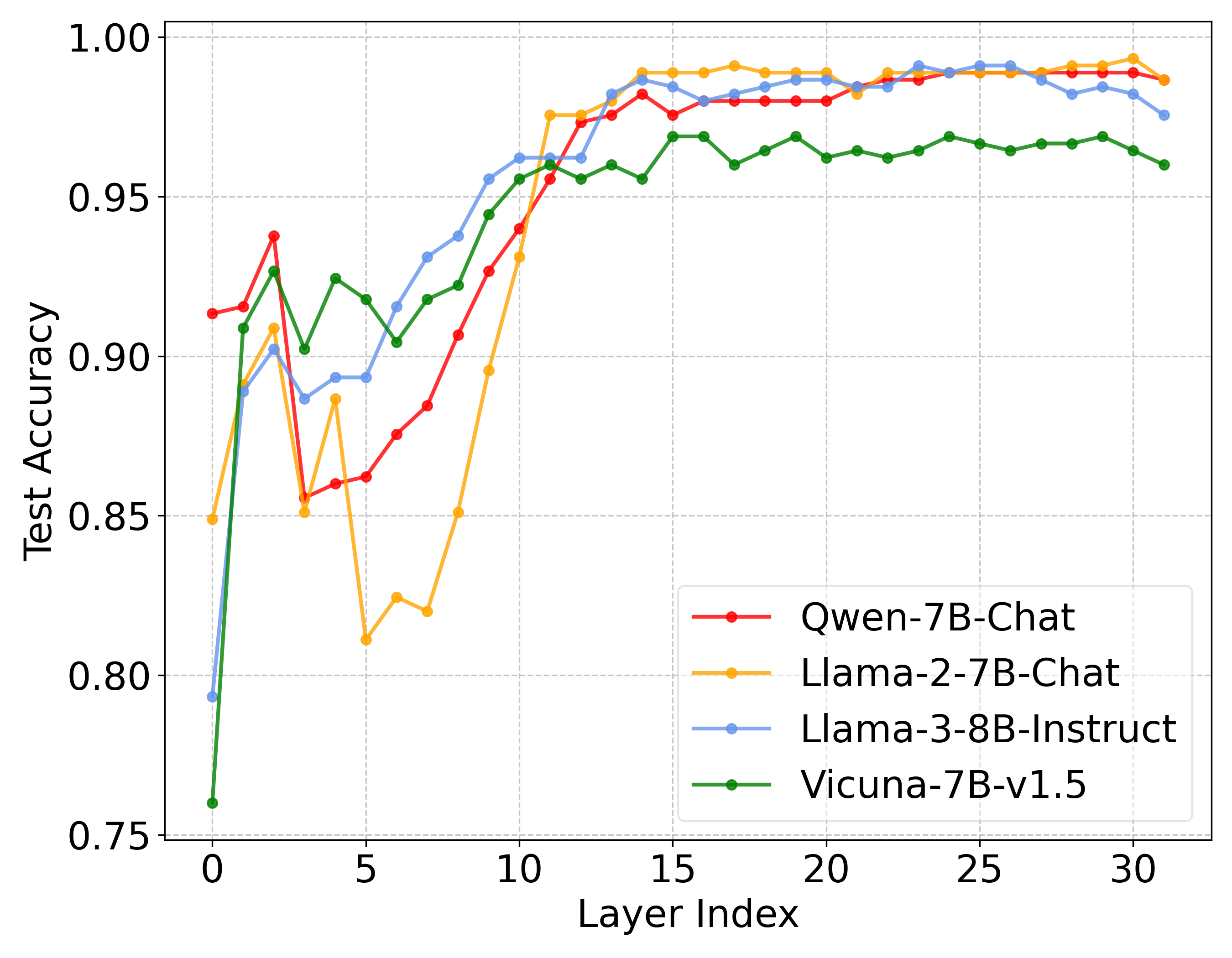
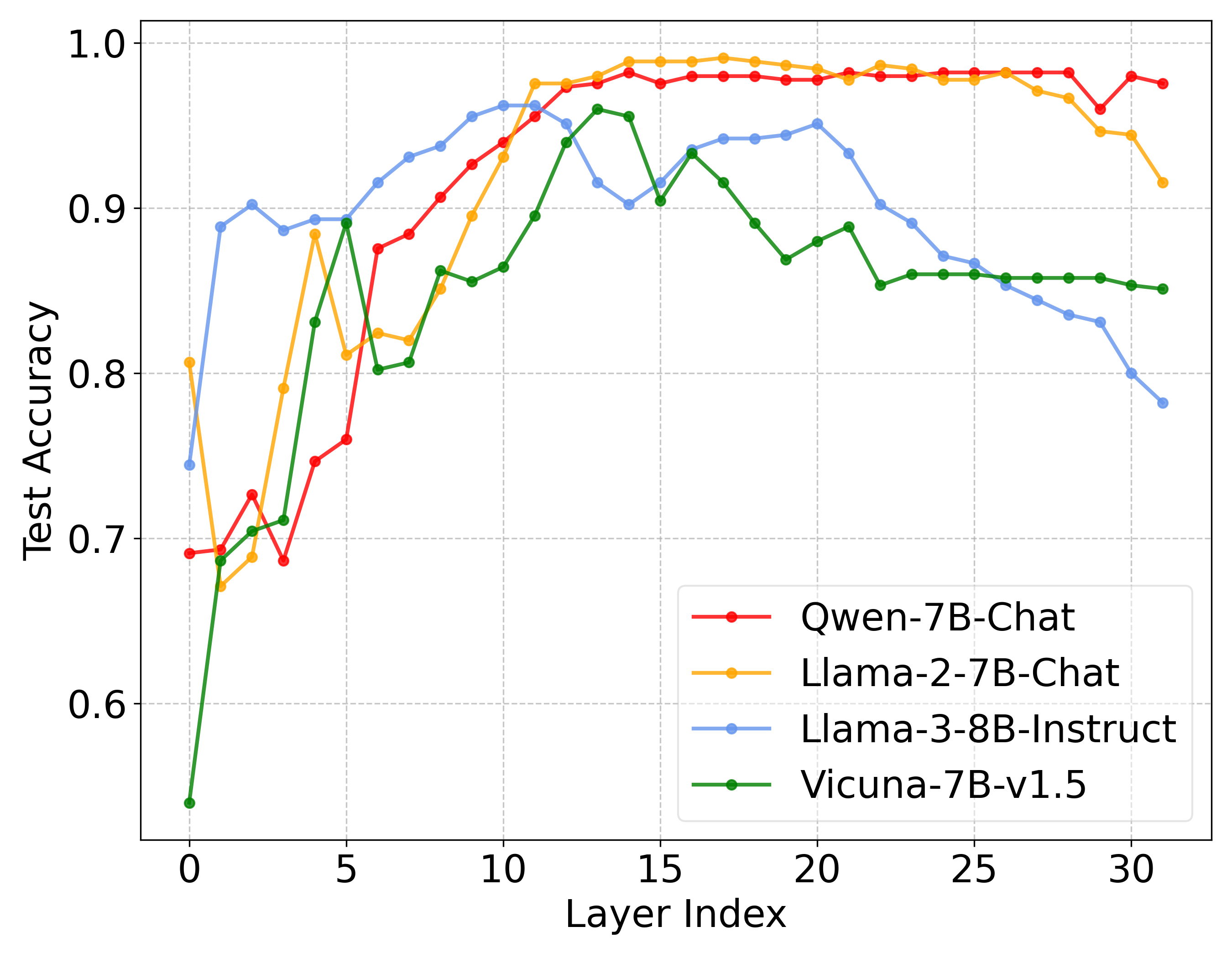

📊 实验亮点
实验结果表明,SafeInt在防御六种越狱攻击、两个越狱数据集上均优于所有基线方法。在防御越狱攻击的同时,SafeInt能够保持LLM的效用,避免过度干预导致模型性能下降。此外,SafeInt对自适应攻击具有一定的鲁棒性,能够有效缓解实时攻击。
🎯 应用场景
SafeInt可应用于各种需要确保LLM安全性的场景,例如智能客服、内容生成、代码助手等。通过防御越狱攻击,SafeInt可以防止LLM产生有害、不安全或不符合道德规范的输出,从而提高LLM的可靠性和安全性。该研究的成果有助于推动LLM在现实世界中的更广泛应用,并降低潜在的安全风险。
📄 摘要(原文)
With the widespread real-world deployment of large language models (LLMs), ensuring their behavior complies with safety standards has become crucial. Jailbreak attacks exploit vulnerabilities in LLMs to induce undesirable behavior, posing a significant threat to LLM safety. Previous defenses often fail to achieve both effectiveness and efficiency simultaneously. Defenses from a representation perspective offer new insights, but existing interventions cannot dynamically adjust representations based on the harmfulness of the queries. To address this limitation, we propose SafeIntervention (SafeInt), a novel defense method that shields LLMs from jailbreak attacks through safety-aware representation intervention. Built on our analysis of the representations of jailbreak samples, the core idea of SafeInt is to relocate jailbreak-related representations into the rejection region. This is achieved by intervening in the representation distributions of jailbreak samples to align them with those of unsafe samples. We conduct comprehensive experiments covering six jailbreak attacks, two jailbreak datasets, and two utility benchmarks. Experimental results demonstrate that SafeInt outperforms all baselines in defending LLMs against jailbreak attacks while largely maintaining utility. Additionally, we evaluate SafeInt against adaptive attacks and verify its effectiveness in mitigating real-time attacks.