Detecting Future-related Contexts of Entity Mentions
作者: Puneet Prashar, Krishna Mohan Shukla, Adam Jatowt
分类: cs.CL, cs.IR
发布日期: 2025-02-21
💡 一句话要点
提出实体未来语境检测方法,解决信息处理中自动时序分析的需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 未来语境检测 实体指代 语言模型 时序分析 自然语言处理
📋 核心要点
- 现有方法难以有效识别文本中实体与未来相关的隐式语境,阻碍了自动时序分析的进展。
- 论文提出一种基于语言模型的方法,通过学习实体在不同语境下的表示来区分未来相关和非未来相关的内容。
- 实验结果表明,大型语言模型在该任务上表现出良好的性能,验证了该方法在未来语境检测方面的有效性。
📝 摘要(中文)
本文致力于识别实体在文本中是否被隐式地提及于未来语境中,以满足信息处理领域对自动时序分析日益增长的需求,此能力在决策制定、规划和趋势预测等多个应用中具有重要价值。为此,我们首先构建了一个包含19540个句子的新型数据集,这些句子围绕从维基百科获取的热门实体展开,包含了这些实体出现的未来相关和非未来相关语境。其次,我们评估了几种语言模型(包括大型语言模型LLM)在该任务上的性能,即在缺乏显式时间参考的情况下区分面向未来的内容。
🔬 方法详解
问题定义:论文旨在解决实体指代在文本中是否指向未来的问题。现有方法通常依赖于显式的时间表达,无法处理隐式未来语境,导致在实际应用中效果不佳。例如,句子中没有明确的“明天”、“下周”等词语,但通过上下文可以推断出实体相关的事件将在未来发生。
核心思路:论文的核心思路是利用语言模型学习实体在不同语境下的语义表示,并基于这些表示来判断该语境是否与未来相关。通过训练模型区分未来相关和非未来相关的句子,从而实现对隐式未来语境的检测。这种方法避免了对显式时间表达的依赖,能够更准确地捕捉文本中的未来指向性。
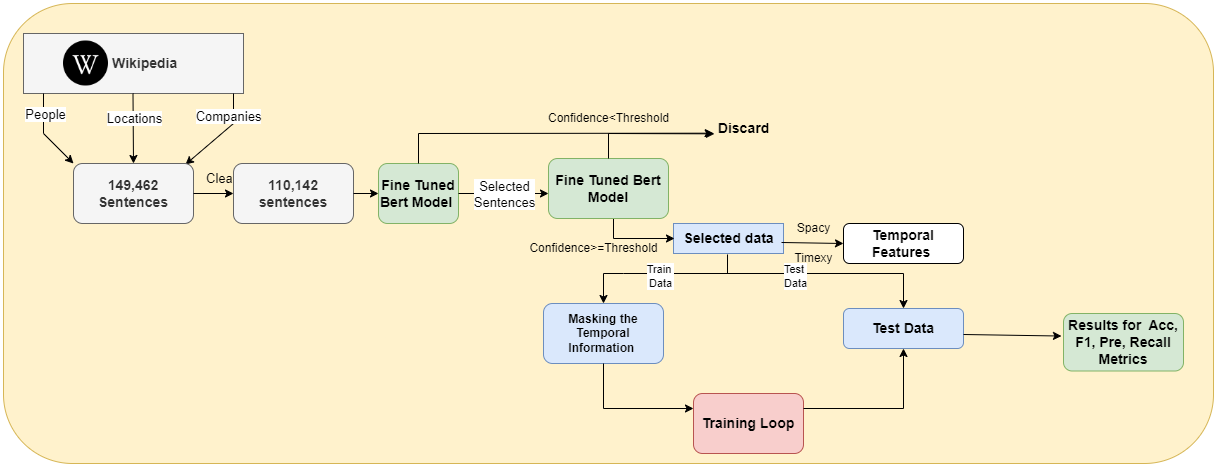
技术框架:整体框架包含以下几个主要步骤:1) 数据集构建:收集包含实体的句子,并标注每个句子是否与未来相关。2) 模型选择:选择合适的语言模型,例如BERT、RoBERTa或大型语言模型。3) 模型训练:使用标注的数据集对语言模型进行微调,使其能够区分未来相关和非未来相关的句子。4) 模型评估:使用测试集评估模型的性能,并与其他基线方法进行比较。
关键创新:论文的关键创新在于提出了一个针对实体未来语境检测的新型数据集,并验证了大型语言模型在该任务上的有效性。此外,该方法关注的是隐式未来语境,避免了对显式时间表达的依赖,从而提高了检测的准确性和鲁棒性。
关键设计:论文的关键设计包括:1) 数据集的构建,确保数据集的多样性和代表性。2) 语言模型的选择,根据任务的特点选择合适的模型。3) 损失函数的选择,例如交叉熵损失函数,用于训练模型区分未来相关和非未来相关的句子。4) 评估指标的选择,例如准确率、精确率、召回率和F1值,用于评估模型的性能。
🖼️ 关键图片


📊 实验亮点
论文构建了一个包含19540个句子的新数据集,并评估了多种语言模型在该数据集上的性能。实验结果表明,大型语言模型(LLM)在该任务上表现出良好的性能,能够有效地区分未来相关和非未来相关的语境。具体的性能数据和与其他基线方法的比较结果在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于多个领域,例如:在金融领域,可以预测公司未来的发展趋势;在新闻领域,可以识别与未来事件相关的报道;在舆情分析领域,可以预测公众对未来政策的反应。此外,该技术还可以用于智能助手和聊天机器人,使其能够更好地理解用户的意图并提供更准确的回答。这项研究有助于提升信息处理的智能化水平,为决策制定提供更可靠的依据。
📄 摘要(原文)
The ability to automatically identify whether an entity is referenced in a future context can have multiple applications including decision making, planning and trend forecasting. This paper focuses on detecting implicit future references in entity-centric texts, addressing the growing need for automated temporal analysis in information processing. We first present a novel dataset of 19,540 sentences built around popular entities sourced from Wikipedia, which consists of future-related and non-future-related contexts in which those entities appear. As a second contribution, we evaluate the performance of several Language Models including also Large Language Models (LLMs) on the task of distinguishing future-oriented content in the absence of explicit temporal references.