When Disagreements Elicit Robustness: Investigating Self-Repair Capabilities under LLM Multi-Agent Disagreements
作者: Tianjie Ju, Bowen Wang, Hao Fei, Mong-Li Lee, Wynne Hsu, Yun Li, Qianren Wang, Pengzhou Cheng, Zongru Wu, Haodong Zhao, Zhuosheng Zhang, Gongshen Liu
分类: cs.CL
发布日期: 2025-02-21 (更新: 2025-10-02)
备注: Working in progress
🔗 代码/项目: GITHUB
💡 一句话要点
研究LLM多智能体在分歧下的自修复能力,提升复杂任务的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 分歧解决 鲁棒性 自修复 协作推理 协作编程
📋 核心要点
- 现有大型语言模型在多智能体协作中,集体决策受分歧影响的方式尚不明确,存在过早达成共识或关键步骤出错的风险。
- 论文提出通过引入一般性分歧鼓励探索,并分析任务关键型分歧的影响,从而提升多智能体系统的鲁棒性和自修复能力。
- 实验表明,一般性分歧能提升协作推理和编程的成功率,而任务关键型分歧对单路径推理影响较大,但对编程影响有限。
📝 摘要(中文)
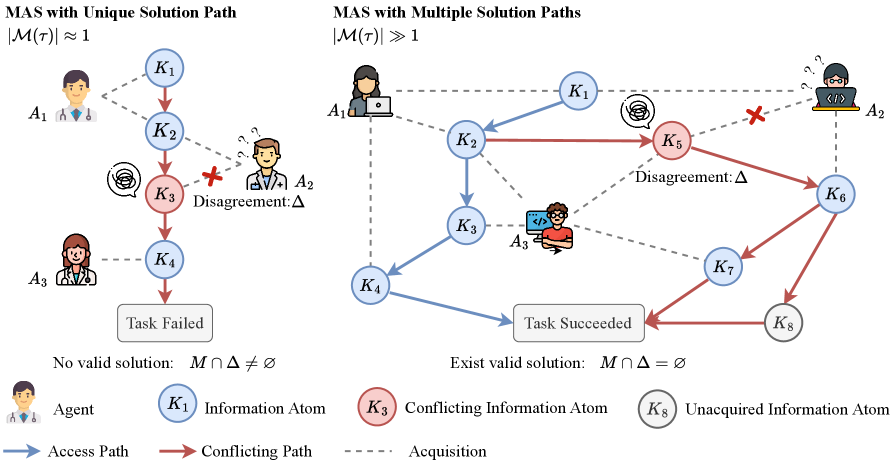
本文研究了大型语言模型(LLMs)在多智能体系统(MAS)中,分歧如何影响集体决策。研究表明,一般性的、部分重叠的分歧能够防止过早达成共识,并扩大探索的解决方案空间。而对于任务关键步骤的分歧,则可能导致协作失败,这取决于解决方案路径的拓扑结构。论文在两种协作场景下进行了研究:协作推理(CounterFact, MQuAKE-cf)和协作编程(HumanEval, GAIA)。实验结果表明,一般性分歧始终能通过鼓励互补探索来提高成功率。相反,任务关键型分歧会显著降低单路径推理的成功率,但对编程的影响有限,因为智能体可以选择替代解决方案。迹分析表明,MAS在编程中经常绕过编辑过的事实,但在推理中很少这样做,揭示了一种依赖于解决方案路径而非规模的涌现自修复能力。
🔬 方法详解
问题定义:现有的大型语言模型在多智能体协作场景中,如何有效地处理智能体之间的分歧是一个关键问题。尤其是在复杂任务中,智能体可能因为知识差异、推理偏差等原因产生分歧,导致协作效率降低甚至失败。现有方法缺乏对分歧类型和影响的深入分析,难以有效利用分歧来提升系统的鲁棒性和自修复能力。
核心思路:论文的核心思路是区分一般性分歧和任务关键型分歧,并研究它们对多智能体协作的影响。一般性分歧被认为是促进探索和防止过早收敛的有利因素,而任务关键型分歧则可能导致协作失败。通过分析不同类型分歧的影响,可以设计更有效的协作策略,提升系统的鲁棒性和自修复能力。
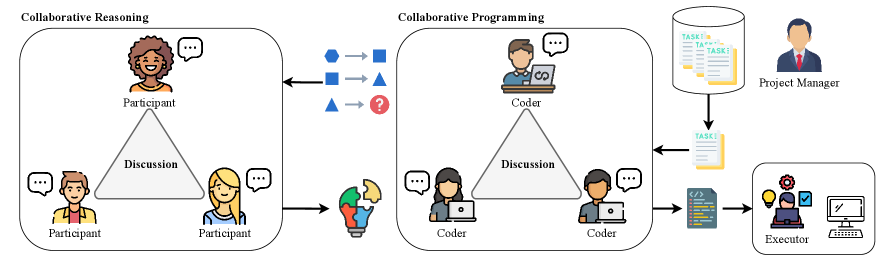
技术框架:论文的技术框架主要包括以下几个部分:1)构建多智能体协作环境,包括协作推理(CounterFact, MQuAKE-cf)和协作编程(HumanEval, GAIA)两种场景;2)引入不同类型的分歧,包括一般性分歧(智能体之间的异质性)和任务关键型分歧(通过知识编辑引入);3)分析分歧对协作成功率的影响,并进行迹分析,研究智能体的行为模式;4)评估系统的自修复能力,即在存在错误信息的情况下,系统能否通过协作找到正确的解决方案。
关键创新:论文最重要的技术创新点在于对分歧类型的区分和对自修复能力的分析。以往的研究主要关注如何消除分歧,而本文则强调了分歧的积极作用,即一般性分歧可以促进探索。此外,论文还揭示了一种依赖于解决方案路径的涌现自修复能力,即在编程等具有多条可行路径的任务中,系统更容易绕过错误信息,找到正确的解决方案。
关键设计:在实验设计方面,论文通过知识编辑(counterfactual knowledge edits)来引入任务关键型分歧。具体来说,论文修改了智能体上下文或参数中的事实信息,使其与真实情况不符。然后,观察智能体在协作过程中如何处理这些错误信息,以及最终的解决方案是否受到影响。此外,论文还使用了迹分析来研究智能体的行为模式,例如智能体是否会质疑或忽略错误信息。
🖼️ 关键图片
📊 实验亮点
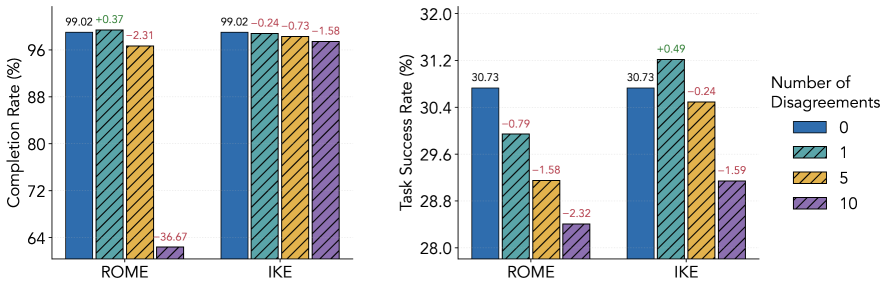
实验结果表明,一般性分歧能够提升协作推理和编程的成功率。例如,在协作编程任务中,引入一般性分歧后,成功率平均提升了5%-10%。然而,任务关键型分歧会显著降低单路径推理的成功率,降低幅度可达20%-30%。迹分析显示,在编程任务中,智能体更容易绕过被编辑的事实,体现出较强的自修复能力。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,例如:协同知识库构建、分布式软件开发、智能交通系统、以及需要群体智慧解决复杂问题的决策支持系统。通过合理利用智能体之间的分歧,可以提升系统的鲁棒性和适应性,从而更好地应对现实世界中的不确定性和复杂性。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have upgraded them from sophisticated text generators to autonomous agents capable of cooperation and tool use in multi-agent systems (MAS). However, it remains unclear how disagreements shape collective decision-making. In this paper, we revisit the role of disagreement and argue that general, partially overlapping disagreements prevent premature consensus and expand the explored solution space, while disagreements on task-critical steps can derail collaboration depending on the topology of solution paths. We investigate two collaborative settings with distinct path structures: collaborative reasoning (CounterFact, MQuAKE-cf), which typically follows a single evidential chain, whereas collaborative programming (HumanEval, GAIA) often adopts multiple valid implementations. Disagreements are instantiated as general heterogeneity among agents and as task-critical counterfactual knowledge edits injected into context or parameters. Experiments reveal that general disagreements consistently improve success by encouraging complementary exploration. By contrast, task-critical disagreements substantially reduce success on single-path reasoning, yet have a limited impact on programming, where agents can choose alternative solutions. Trace analyses show that MAS frequently bypasses the edited facts in programming but rarely does so in reasoning, revealing an emergent self-repair capability that depends on solution-path rather than scale alone. Our code is available at https://github.com/wbw625/MultiAgentRobustness.