DeepRTL: Bridging Verilog Understanding and Generation with a Unified Representation Model
作者: Yi Liu, Changran Xu, Yunhao Zhou, Zeju Li, Qiang Xu
分类: cs.AR, cs.CL, cs.LG
发布日期: 2025-02-20
备注: ICLR 2025 Spotlight
💡 一句话要点
DeepRTL:统一表示模型桥接Verilog理解与生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Verilog理解 Verilog生成 统一表示模型 CodeT5+ 课程学习
📋 核心要点
- 现有方法侧重于Verilog生成,忽略了Verilog理解的重要性,且自然语言描述与Verilog代码对齐较弱,导致生成质量受限。
- DeepRTL通过统一表示模型,同时提升Verilog理解和生成能力,核心在于构建对齐Verilog代码与多层次自然语言描述的综合数据集。
- 实验表明,DeepRTL在Verilog理解任务中显著优于GPT-4,并在Verilog生成任务中达到与OpenAI的o1-preview模型相当的性能。
📝 摘要(中文)
近年来,大型语言模型(LLMs)在自动化硬件描述语言(HDL)代码生成方面展现出巨大潜力。虽然微调提升了LLMs在硬件设计任务中的性能,但以往的研究主要集中在Verilog生成上,忽略了同样重要的Verilog理解任务。此外,现有模型在自然语言描述和Verilog代码之间的对齐较弱,阻碍了高质量、可综合设计的生成。为了解决这些问题,我们提出了DeepRTL,一个在Verilog理解和生成方面表现出色的统一表示模型。DeepRTL基于CodeT5+,并在一个综合数据集上进行微调,该数据集将Verilog代码与丰富的多层次自然语言描述对齐。我们还推出了首个Verilog理解基准,并率先应用嵌入相似度和GPT Score来评估模型的理解能力。这些指标比传统的BLEU和ROUGE等方法更准确地捕捉语义相似性,因为BLEU和ROUGE仅限于表面级别的n-gram重叠。通过采用课程学习来训练DeepRTL,我们使其在Verilog理解任务中显著优于GPT-4,并在Verilog生成任务中达到与OpenAI的o1-preview模型相当的性能。
🔬 方法详解
问题定义:论文旨在解决现有大型语言模型在Verilog理解和生成任务中存在的不足。具体来说,现有方法主要关注Verilog生成,忽略了Verilog理解的重要性,并且自然语言描述和Verilog代码之间的对齐程度较低,导致生成的Verilog代码质量不高,难以综合。现有评估指标如BLEU和ROUGE仅关注表面n-gram重叠,无法准确评估模型的理解能力。
核心思路:论文的核心思路是构建一个统一的表示模型DeepRTL,使其能够同时胜任Verilog理解和生成任务。通过在一个综合数据集上进行微调,该数据集将Verilog代码与丰富的多层次自然语言描述对齐,从而增强模型对Verilog代码的语义理解能力。同时,引入嵌入相似度和GPT Score等新的评估指标,更准确地评估模型的理解能力。
技术框架:DeepRTL基于CodeT5+模型,整体框架包括数据收集与处理、模型微调和评估三个主要阶段。首先,构建一个包含Verilog代码和多层次自然语言描述的综合数据集。然后,使用该数据集对CodeT5+模型进行微调,使其能够学习Verilog代码和自然语言描述之间的映射关系。最后,使用新的评估指标(嵌入相似度和GPT Score)以及传统的BLEU和ROUGE指标,对模型的理解和生成能力进行评估。
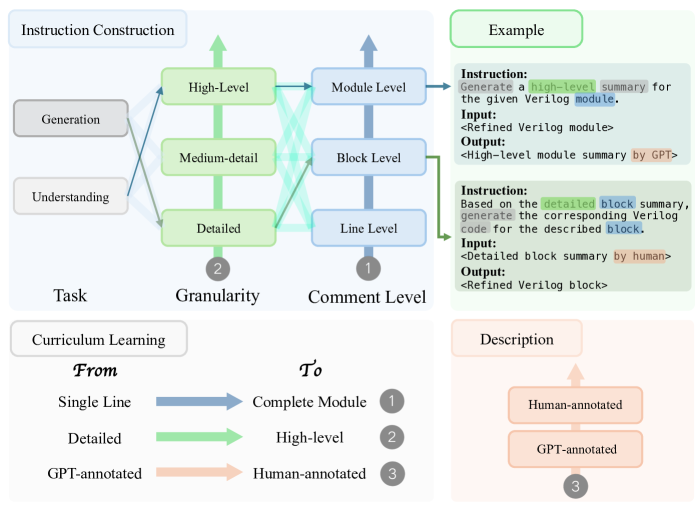
关键创新:论文的关键创新点在于以下几个方面:1) 提出了一个统一的表示模型DeepRTL,能够同时胜任Verilog理解和生成任务。2) 构建了一个包含Verilog代码和多层次自然语言描述的综合数据集,用于模型微调。3) 引入了嵌入相似度和GPT Score等新的评估指标,更准确地评估模型的理解能力。4) 采用课程学习策略训练DeepRTL。
关键设计:DeepRTL基于CodeT5+模型,使用Transformer架构。数据集包含Verilog代码和对应的自然语言描述,自然语言描述包括模块级、功能级和行级描述。损失函数采用标准的交叉熵损失函数。课程学习策略从简单的Verilog代码开始,逐步增加代码的复杂性。嵌入相似度通过计算Verilog代码和自然语言描述的嵌入向量之间的余弦相似度来衡量。GPT Score使用GPT模型评估生成Verilog代码的质量。
🖼️ 关键图片


📊 实验亮点
DeepRTL在Verilog理解任务中显著优于GPT-4,具体表现为在新的Verilog理解基准测试中,使用嵌入相似度和GPT Score评估,DeepRTL的性能明显高于GPT-4。在Verilog生成任务中,DeepRTL达到了与OpenAI的o1-preview模型相当的性能,表明其在生成高质量、可综合的Verilog代码方面具有竞争力。
🎯 应用场景
DeepRTL的应用场景广泛,包括自动化硬件设计、Verilog代码辅助生成、代码理解与验证等。该研究成果有助于提高硬件设计的效率和质量,降低设计成本,并为未来的硬件设计自动化研究奠定基础。此外,该模型还可以应用于教育领域,帮助学生更好地理解和学习Verilog语言。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have shown significant potential for automating hardware description language (HDL) code generation from high-level natural language instructions. While fine-tuning has improved LLMs' performance in hardware design tasks, prior efforts have largely focused on Verilog generation, overlooking the equally critical task of Verilog understanding. Furthermore, existing models suffer from weak alignment between natural language descriptions and Verilog code, hindering the generation of high-quality, synthesizable designs. To address these issues, we present DeepRTL, a unified representation model that excels in both Verilog understanding and generation. Based on CodeT5+, DeepRTL is fine-tuned on a comprehensive dataset that aligns Verilog code with rich, multi-level natural language descriptions. We also introduce the first benchmark for Verilog understanding and take the initiative to apply embedding similarity and GPT Score to evaluate the models' understanding capabilities. These metrics capture semantic similarity more accurately than traditional methods like BLEU and ROUGE, which are limited to surface-level n-gram overlaps. By adapting curriculum learning to train DeepRTL, we enable it to significantly outperform GPT-4 in Verilog understanding tasks, while achieving performance on par with OpenAI's o1-preview model in Verilog generation tasks.