ExpertLens: Activation steering features are highly interpretable
作者: Masha Fedzechkina, Eleonora Gualdoni, Sinead Williamson, Katherine Metcalf, Skyler Seto, Barry-John Theobald
分类: cs.CL, cs.AI
发布日期: 2025-02-20 (更新: 2025-11-03)
💡 一句话要点
ExpertLens:通过激活调控发现LLM中高度可解释的概念表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 激活调控 概念表征 神经元分析
📋 核心要点
- 现有激活调控方法缺乏对LLM内部表征的深入理解,难以解释其有效性。
- 提出ExpertLens方法,通过识别和分析负责特定概念的神经元,揭示LLM的概念表征。
- 实验表明ExpertLens表征稳定且与人类表征高度一致,优于传统嵌入方法。
📝 摘要(中文)
大型语言模型(LLM)中的激活调控方法已经成为一种有效的手段,它能够在不需要大量适配数据的情况下,对生成的语言进行有针对性的更新,从而增强其性能。本文探讨了激活调控方法所发现的特征是否具有可解释性。我们使用激活调控研究中的“寻找专家”方法来识别负责特定概念(例如,“猫”)的神经元,并表明对这些神经元的检查(即ExpertLens)能够提供关于模型表征的深刻见解。我们发现ExpertLens表征在不同的模型和数据集上是稳定的,并且与从行为数据推断出的人类表征紧密对齐,达到了人与人之间的对齐水平。ExpertLens显著优于词/句子嵌入所捕获的对齐。通过ExpertLens重建人类概念组织,我们展示了它能够提供对LLM概念表征的细粒度视图。我们的研究结果表明,ExpertLens是一种灵活且轻量级的方法,用于捕获和分析模型表征。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)激活调控方法虽然能够有效提升生成语言的质量,但缺乏对模型内部概念表征的深入理解。如何理解和解释这些激活调控方法所发现的特征,以及这些特征与人类认知之间的关系,是本文要解决的核心问题。现有方法主要依赖于词/句子嵌入,无法提供细粒度的概念表征,且与人类认知的对齐程度较低。
核心思路:本文的核心思路是通过识别LLM中负责特定概念的神经元(即“专家”),并分析这些神经元的激活模式,从而揭示LLM内部的概念表征。这种方法类似于人类认知中的“概念神经元”,通过分析这些神经元的行为,可以理解模型如何组织和处理不同的概念。
技术框架:ExpertLens方法主要包含以下几个阶段:1) 使用“寻找专家”方法识别负责特定概念的神经元。这通常涉及到对LLM输入包含特定概念的文本,并分析哪些神经元的激活程度最高。2) 对这些神经元的激活模式进行分析,例如,通过可视化激活图或计算神经元之间的相关性。3) 将LLM的概念表征与人类的概念表征进行比较,例如,通过计算LLM表征与人类行为数据之间的对齐程度。
关键创新:ExpertLens的关键创新在于它提供了一种细粒度的、可解释的LLM概念表征方法。与传统的词/句子嵌入方法相比,ExpertLens能够揭示LLM内部更丰富的概念关系,并且与人类认知的对齐程度更高。此外,ExpertLens方法具有轻量级的特点,不需要大量的训练数据或计算资源。
关键设计:ExpertLens方法依赖于“寻找专家”算法来识别负责特定概念的神经元。该算法通常涉及到对LLM输入包含特定概念的文本,并计算每个神经元的激活程度。激活程度最高的神经元被认为是该概念的“专家”。此外,ExpertLens方法还涉及到对神经元激活模式的分析,例如,通过计算神经元之间的相关性或使用降维技术将高维激活向量可视化。具体的参数设置和损失函数取决于所使用的“寻找专家”算法和激活模式分析方法。
🖼️ 关键图片
📊 实验亮点
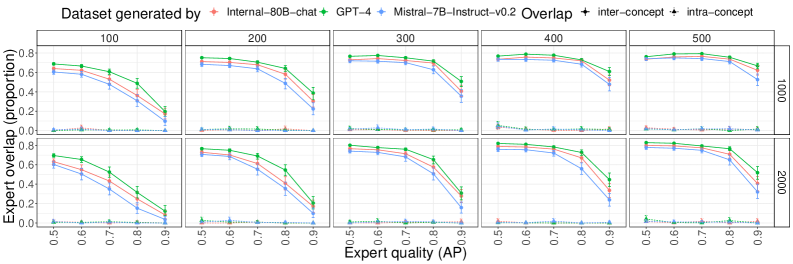
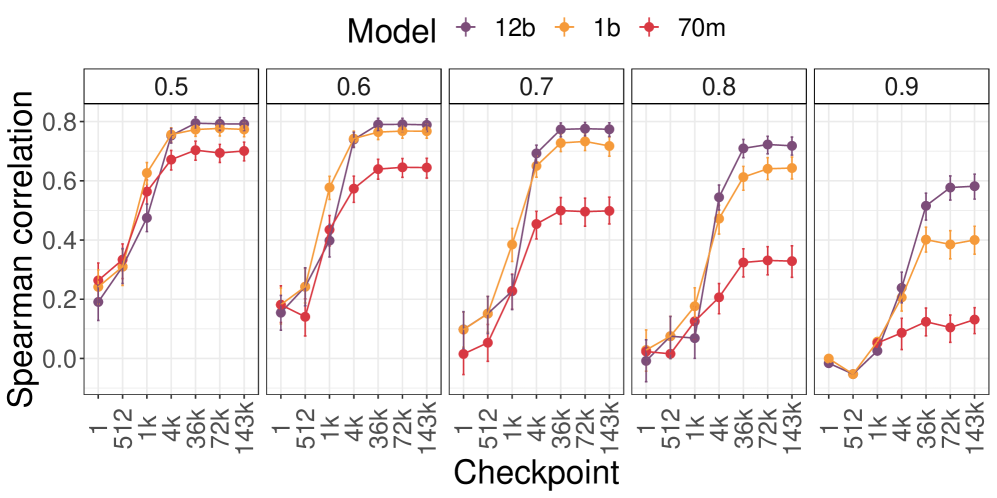
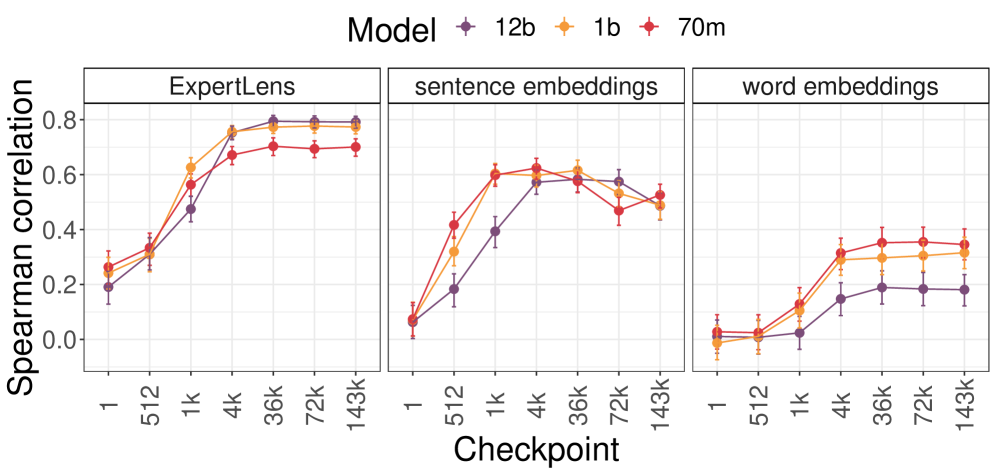
实验结果表明,ExpertLens表征在不同模型和数据集上具有稳定性,并且与人类概念表征高度一致,达到人与人之间的对齐水平。ExpertLens在概念对齐方面显著优于传统的词/句子嵌入方法。通过ExpertLens重建的人类概念组织,验证了其对LLM概念表征的细粒度分析能力。
🎯 应用场景
ExpertLens可应用于理解和改进LLM的知识表示、提升模型的可解释性、以及评估模型与人类认知的对齐程度。该方法还可用于诊断模型的偏差和漏洞,并指导模型的安全和可靠部署。未来,ExpertLens有望成为LLM开发和评估的重要工具。
📄 摘要(原文)
Activation steering methods in large language models (LLMs) have emerged as an effective way to perform targeted updates to enhance generated language without requiring large amounts of adaptation data. We ask whether the features discovered by activation steering methods are interpretable. We identify neurons responsible for specific concepts (e.g.,
cat'') using thefinding experts'' method from research on activation steering and show that the ExpertLens, i.e., inspection of these neurons provides insights about model representation. We find that ExpertLens representations are stable across models and datasets and closely align with human representations inferred from behavioral data, matching inter-human alignment levels. ExpertLens significantly outperforms the alignment captured by word/sentence embeddings. By reconstructing human concept organization through ExpertLens, we show that it enables a granular view of LLM concept representation. Our findings suggest that ExpertLens is a flexible and lightweight approach for capturing and analyzing model representations.