Using tournaments to calculate AUROC for zero-shot classification with LLMs
作者: WonJin Yoon, Ian Bulovic, Timothy A. Miller
分类: cs.CL
发布日期: 2025-02-20 (更新: 2025-11-22)
备注: The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025, Findings). The code is available at: https://github.com/Machine-Learning-for-Medical-Language/cnlp_llm
期刊: In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23583-23591, Suzhou, China. Association for Computational Linguistics
DOI: 10.18653/v1/2025.findings-emnlp.1281
💡 一句话要点
利用锦标赛机制计算AUROC,提升LLM零样本分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本分类 大型语言模型 成对比较 Elo评分系统 锦标赛机制
📋 核心要点
- 现有零样本分类方法缺乏可修改的决策边界,难以与监督学习模型公平比较。
- 论文提出基于锦标赛机制的成对比较方法,利用LLM进行实例排序,并使用Elo评分系统进行置信度评估。
- 实验表明,该方法在减少比较次数的同时,提高了分类性能,并提供了更丰富的信息。
📝 摘要(中文)
大型语言模型(LLM)在许多零样本分类任务中表现出色,但由于缺乏可修改的决策边界,难以与监督分类器进行公平比较。本文提出并评估了一种方法,该方法将二元分类任务转换为数据集内实例之间的成对比较,使用LLM生成这些实例的相对排序。重复的成对比较可用于使用Elo评分系统(用于国际象棋和其他比赛)对实例进行评分,从而在数据集中的实例上产生置信度排序。我们评估了调度算法最小化比较的能力,并表明我们提出的算法可以提高分类性能,同时提供比传统零样本分类更多的信息。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在零样本分类任务中,由于缺乏可修改的决策边界而难以与监督学习模型进行公平比较的问题。现有方法无法有效利用LLM的排序能力,且缺乏置信度评估机制。
核心思路:论文的核心思路是将二元分类问题转化为实例间的成对比较,利用LLM对实例进行相对排序,并通过类似国际象棋比赛的Elo评分系统,对实例进行置信度排序。这种方法能够有效利用LLM的排序能力,并提供实例的置信度评估。
技术框架:整体流程包括以下几个阶段:1) 将二元分类任务转化为成对比较任务;2) 使用LLM对实例进行相对排序;3) 使用Elo评分系统对实例进行评分,生成置信度排序;4) 评估不同的调度算法,以最小化比较次数。
关键创新:最重要的技术创新点在于将锦标赛机制(Elo评分系统)引入到LLM的零样本分类中,通过成对比较和置信度排序,解决了传统零样本分类方法缺乏可修改决策边界的问题。与现有方法相比,该方法能够更有效地利用LLM的排序能力,并提供实例的置信度评估。
关键设计:关键设计包括:1) 选择合适的LLM进行实例排序;2) 设计有效的提示工程,以引导LLM进行准确的相对排序;3) 选择合适的Elo评分系统参数,以保证评分的准确性和稳定性;4) 设计高效的调度算法,以最小化比较次数,同时保证评分的准确性。
🖼️ 关键图片


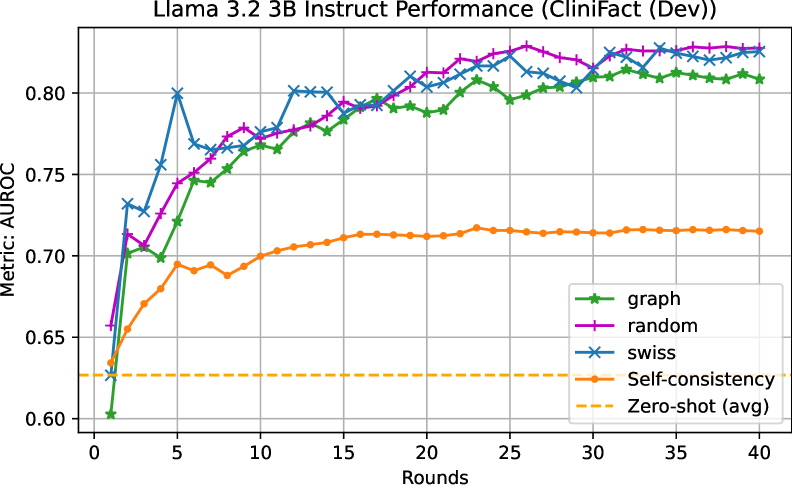
📊 实验亮点
论文提出的方法在零样本分类任务中取得了显著的性能提升。通过使用锦标赛机制和Elo评分系统,该方法能够更有效地利用LLM的排序能力,并提供实例的置信度评估。实验结果表明,该方法在减少比较次数的同时,提高了分类性能,并提供了比传统零样本分类更多的信息。
🎯 应用场景
该研究成果可应用于各种需要零样本分类的场景,例如:图像分类、文本分类、情感分析等。尤其适用于缺乏标注数据或标注成本较高的场景。该方法能够提高分类性能,并提供实例的置信度评估,有助于提升决策的可靠性。未来可进一步研究如何将该方法应用于更复杂的分类任务,例如多标签分类、层次分类等。
📄 摘要(原文)
Large language models perform surprisingly well on many zero-shot classification tasks, but are difficult to fairly compare to supervised classifiers due to the lack of a modifiable decision boundary. In this work, we propose and evaluate a method that transforms binary classification tasks into pairwise comparisons between instances within a dataset, using LLMs to produce relative rankings of those instances. Repeated pairwise comparisons can be used to score instances using the Elo rating system (used in chess and other competitions), inducing a confidence ordering over instances in a dataset. We evaluate scheduling algorithms for their ability to minimize comparisons, and show that our proposed algorithm leads to improved classification performance, while also providing more information than traditional zero-shot classification.