Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
作者: Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, Chong Luo
分类: cs.CL, cs.AI
发布日期: 2025-02-20
💡 一句话要点
Logic-RL:利用规则强化学习释放LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 大型语言模型 推理能力 规则学习 逻辑推理
📋 核心要点
- 现有大型语言模型在复杂推理任务中面临挑战,缺乏有效的训练方法来提升其推理能力。
- 提出Logic-RL,一种基于规则的强化学习方法,通过精心设计的奖励函数和系统提示,引导模型进行推理。
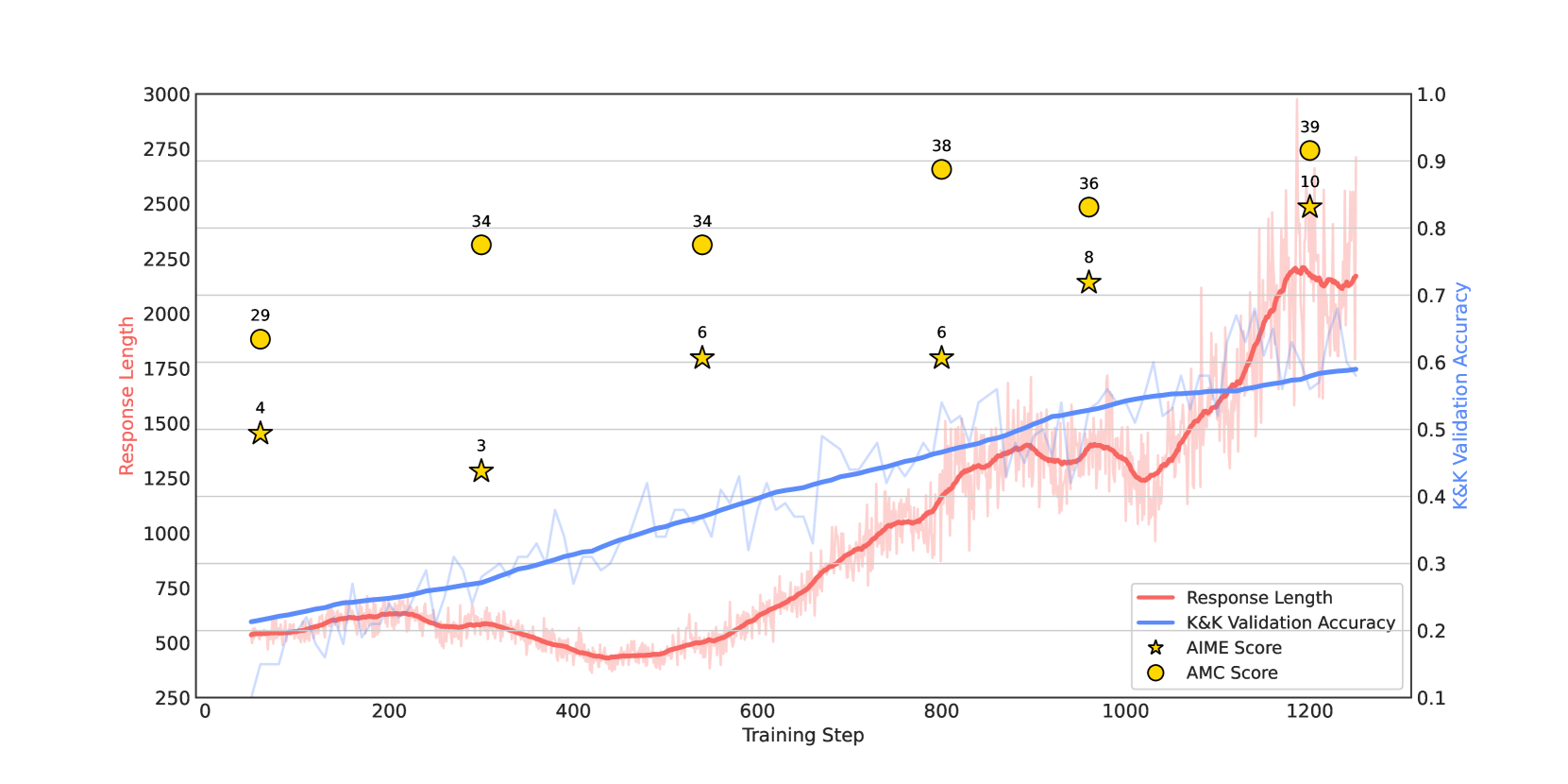
- 实验表明,仅使用5K逻辑问题训练的7B模型,在AIME和AMC等数学基准测试中表现出良好的泛化能力。
📝 摘要(中文)
受DeepSeek-R1成功的启发,本文探索了基于规则的强化学习(RL)在大型推理模型中的潜力。为了分析推理动态,我们使用合成逻辑谜题作为训练数据,因为它们具有可控的复杂性和直接的答案验证。我们做出了一些关键的技术贡献,从而实现了有效和稳定的RL训练:一个强调思考和回答过程的系统提示,一个严格的格式奖励函数,惩罚采取捷径的输出,以及一个实现稳定收敛的直接训练方案。我们的7B模型发展了高级推理技能——如反思、验证和总结——这些技能在逻辑语料库中是不存在的。值得注意的是,在仅训练了5K个逻辑问题后,它展示了对具有挑战性的数学基准AIME和AMC的泛化能力。
🔬 方法详解
问题定义:现有的大型语言模型在复杂推理任务中表现出一定的能力,但缺乏有效的训练方法来进一步提升其推理能力,尤其是在逻辑推理和数学问题解决方面。现有的方法往往难以引导模型进行有效的推理过程,并且容易出现“抄近路”的行为,即模型可能通过记忆或模式匹配来获得答案,而不是真正进行推理。
核心思路:本文的核心思路是利用规则强化学习(Rule-Based Reinforcement Learning)来训练大型语言模型,使其能够进行更有效的推理。通过设计合适的奖励函数和系统提示,引导模型逐步进行推理,并惩罚“抄近路”的行为,从而提高模型的推理能力和泛化能力。
技术框架:Logic-RL的整体框架包括以下几个主要模块:1) 环境:使用合成逻辑谜题作为训练数据,这些谜题具有可控的复杂性和直接的答案验证。2) 智能体:使用大型语言模型作为智能体,负责生成推理步骤和最终答案。3) 奖励函数:设计一个严格的格式奖励函数,该函数不仅奖励正确的答案,还奖励清晰、完整的推理过程,并惩罚不符合格式或采取捷径的输出。4) 系统提示:使用一个强调思考和回答过程的系统提示,引导模型进行逐步推理。5) 训练过程:使用强化学习算法(具体算法未知)来训练模型,使其能够最大化累积奖励。
关键创新:本文最重要的技术创新点在于将规则强化学习应用于大型语言模型的推理能力提升。与传统的监督学习方法不同,强化学习能够通过奖励和惩罚来引导模型进行更有效的推理。此外,精心设计的奖励函数和系统提示也是关键创新,它们能够有效地引导模型进行逐步推理,并避免“抄近路”的行为。
关键设计:关键的设计细节包括:1) 系统提示:强调思考和回答过程,例如要求模型首先总结问题,然后逐步进行推理,最后给出答案。2) 奖励函数:对清晰、完整的推理过程给予奖励,对不符合格式或采取捷径的输出进行惩罚。奖励函数的具体形式未知。3) 训练数据:使用合成逻辑谜题作为训练数据,这些谜题具有可控的复杂性和直接的答案验证。4) 模型规模:使用7B参数的模型进行实验。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Logic-RL训练的7B模型在仅训练了5K个逻辑问题后,就能够泛化到具有挑战性的数学基准测试AIME和AMC。这一结果表明,Logic-RL能够有效地提高大型语言模型的推理能力和泛化能力,使其能够解决更复杂的问题。
🎯 应用场景
Logic-RL方法具有广泛的应用前景,可以应用于各种需要复杂推理的任务中,例如数学问题解决、逻辑推理、代码生成和自然语言理解。该方法可以提高大型语言模型在这些任务中的性能和可靠性,使其能够更好地服务于实际应用,例如智能助手、自动化推理系统和教育工具。
📄 摘要(原文)
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in large reasoning models. To analyze reasoning dynamics, we use synthetic logic puzzles as training data due to their controllable complexity and straightforward answer verification. We make some key technical contributions that lead to effective and stable RL training: a system prompt that emphasizes the thinking and answering process, a stringent format reward function that penalizes outputs for taking shortcuts, and a straightforward training recipe that achieves stable convergence. Our 7B model develops advanced reasoning skills-such as reflection, verification, and summarization-that are absent from the logic corpus. Remarkably, after training on just 5K logic problems, it demonstrates generalization abilities to the challenging math benchmarks AIME and AMC.