Sentence Smith: Controllable Edits for Evaluating Text Embeddings
作者: Hongji Li, Andrianos Michail, Reto Gubelmann, Simon Clematide, Juri Opitz
分类: cs.CL
发布日期: 2025-02-20 (更新: 2025-11-24)
备注: EMNLP 2025 (main), this version fixes a subscript typo in Eq 1
💡 一句话要点
提出Sentence Smith框架,通过可控编辑评估文本嵌入模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 文本嵌入 语义编辑 可控生成 负样本生成 模型评估
📋 核心要点
- 现有文本嵌入模型评估缺乏细粒度,难以区分不同语义变化的影响。
- Sentence Smith框架通过解析、编辑和生成语义图,实现对文本语义的可控操作。
- 实验表明,该框架能生成高质量负样本,并可用于细粒度评估文本嵌入模型。
📝 摘要(中文)
可控且透明的文本生成一直是自然语言处理领域的目标。一种常见的解决思路是将文本解析为符号表示,然后从中生成文本。然而,早期方法受到解析和生成能力不足的限制。本文利用现代解析器和安全监督机制,展示了当前方法与该目标的接近程度。具体而言,我们提出了用于英语的Sentence Smith框架,它包含三个步骤:1. 将句子解析为语义图;2. 应用人工设计的语义操作规则;3. 从操作后的图生成文本。最后,进行蕴含检查(4.)以验证所应用转换的有效性。为了展示我们框架的实用性,我们使用它来生成困难的负样本文本对,以挑战文本嵌入模型。由于可控生成使得清晰地隔离不同类型的语义变化成为可能,我们可以细粒度地评估文本嵌入模型,从而解决当前基准测试中语言现象不透明的问题。人工验证证实,我们的透明生成过程产生高质量的文本。值得注意的是,我们的生成方式非常节省资源,因为它仅依赖于较小的神经网络。
🔬 方法详解
问题定义:论文旨在解决文本嵌入模型评估中缺乏细粒度控制的问题。现有基准测试难以区分不同类型的语义变化,导致对模型能力的评估不够精确。此外,生成高质量的负样本对来挑战文本嵌入模型也是一个难题。
核心思路:论文的核心思路是通过可控的语义编辑来生成文本,从而能够精确控制文本的语义变化。通过将句子解析为语义图,然后对图进行人工设计的语义操作,最后从修改后的图生成文本,可以实现对文本语义的细粒度控制。这种方法允许研究人员隔离和研究特定类型的语义变化对文本嵌入模型的影响。
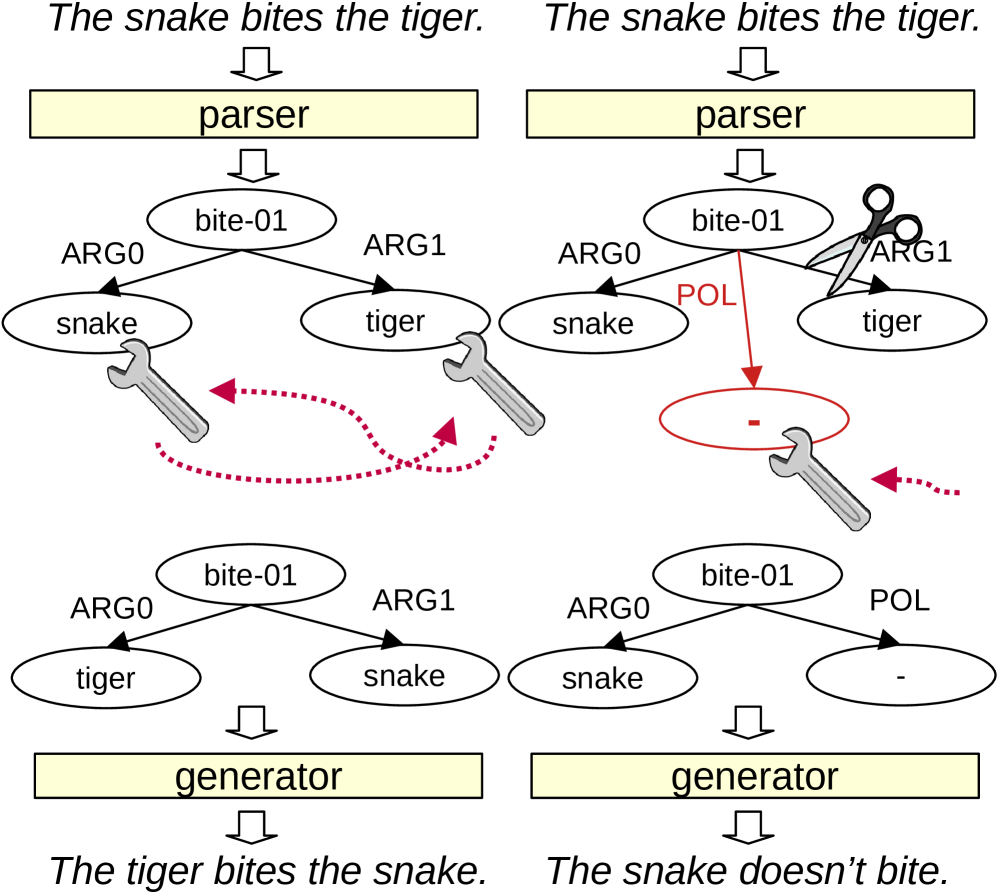
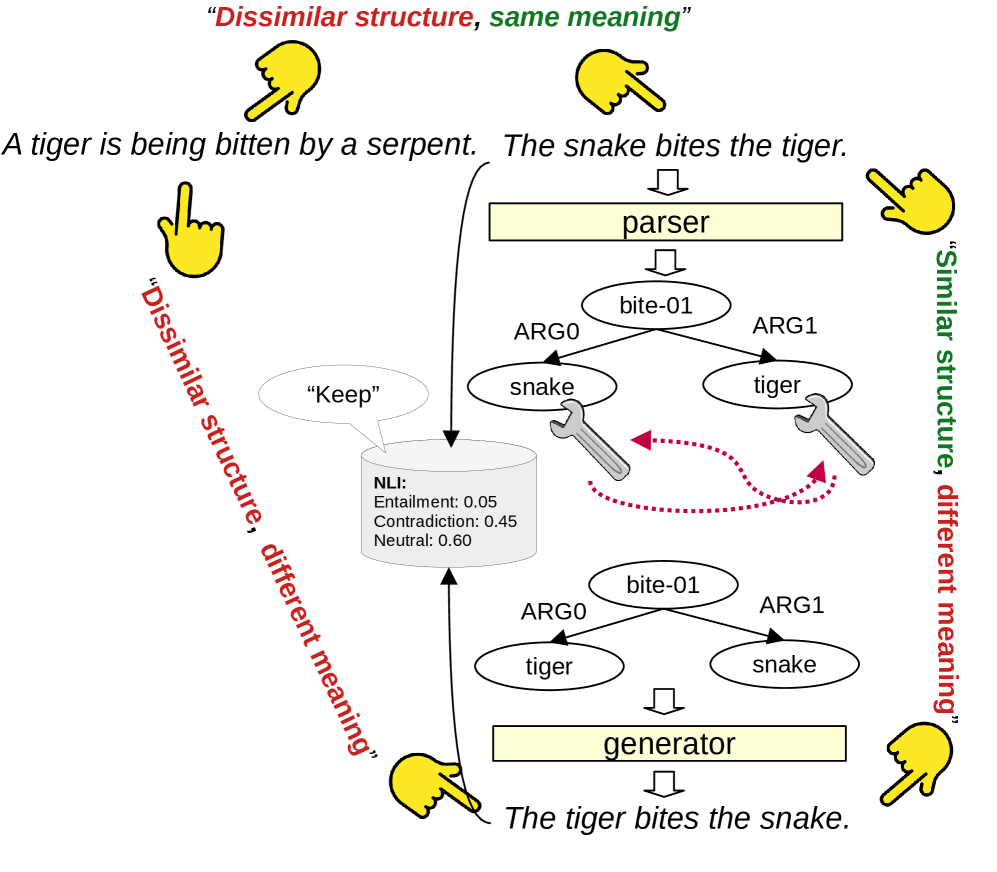
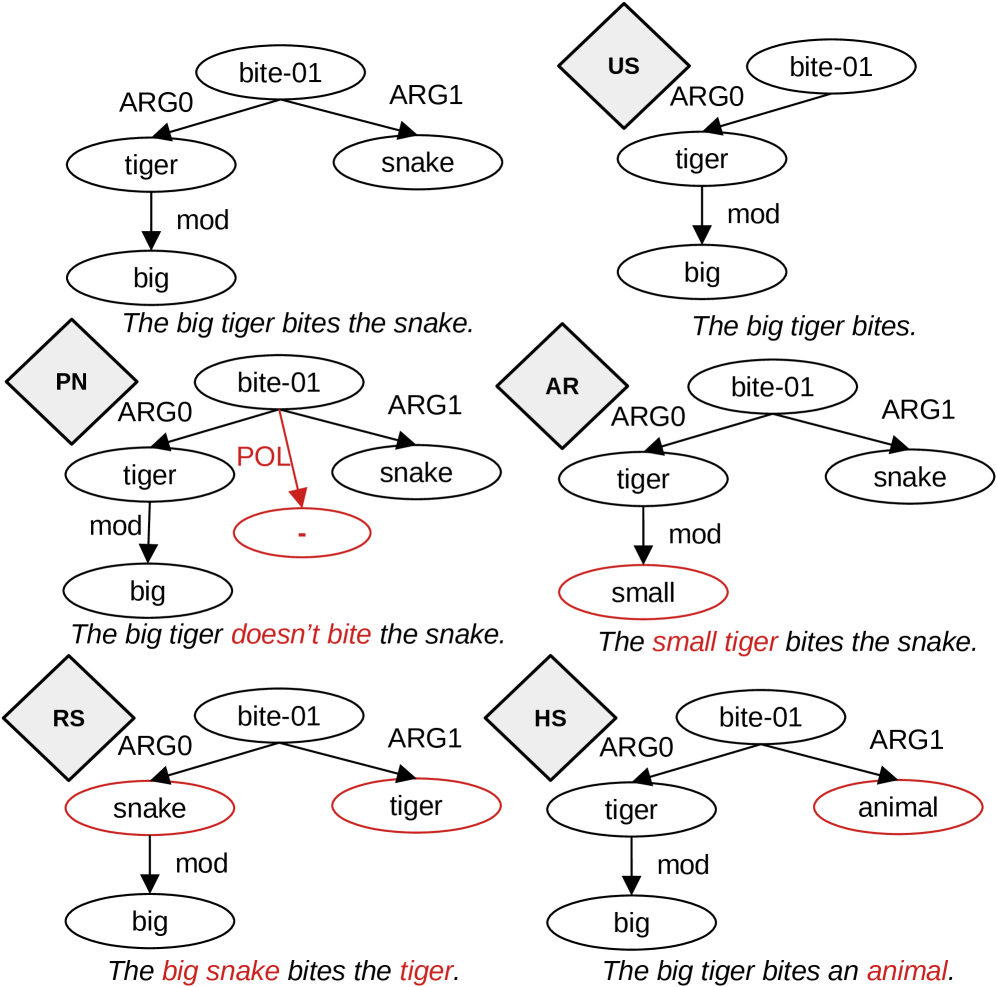
技术框架:Sentence Smith框架包含以下四个主要步骤:1. 解析:使用现代解析器将输入句子解析为语义图。2. 编辑:应用人工设计的语义操作规则来修改语义图。这些规则旨在引入特定的语义变化,例如否定、添加或删除信息。3. 生成:从修改后的语义图生成文本。这个过程使用神经文本生成模型。4. 验证:进行蕴含检查,以确保生成的文本与原始文本之间的关系符合预期。
关键创新:该框架的关键创新在于其可控的文本生成过程。通过将文本生成分解为解析、编辑和生成三个步骤,并使用人工设计的语义操作规则,该框架能够精确控制生成的文本的语义变化。这与传统的文本生成方法不同,后者通常难以控制生成的文本的语义。
关键设计:框架的关键设计包括:1. 使用高质量的语义解析器,以确保准确地将句子转换为语义图。2. 设计一组人工设计的语义操作规则,这些规则能够引入各种类型的语义变化。3. 使用神经文本生成模型,以从修改后的语义图生成流畅自然的文本。4. 采用蕴含检查机制,验证生成文本的有效性。
🖼️ 关键图片
📊 实验亮点
Sentence Smith框架通过可控的语义编辑生成高质量的负样本,用于评估文本嵌入模型。人工验证表明,该框架生成的文本质量良好。该方法能够细粒度地评估文本嵌入模型,并揭示其在处理特定语义变化时的弱点。此外,该框架资源效率高,仅依赖于较小的神经网络。
🎯 应用场景
Sentence Smith框架可应用于文本嵌入模型的细粒度评估、数据增强、对抗样本生成等领域。通过控制语义变化,可以更好地理解和改进文本嵌入模型,并提高其在各种自然语言处理任务中的性能。该框架还可用于生成更具挑战性的训练数据,从而提高模型的鲁棒性。
📄 摘要(原文)
Controllable and transparent text generation has been a long-standing goal in NLP. Almost as long-standing is a general idea for addressing this challenge: Parsing text to a symbolic representation, and generating from it. However, earlier approaches were hindered by parsing and generation insufficiencies. Using modern parsers and a safety supervision mechanism, we show how close current methods come to this goal. Concretely, we propose the Sentence Smith framework for English, which has three steps: 1. Parsing a sentence into a semantic graph. 2. Applying human-designed semantic manipulation rules. 3. Generating text from the manipulated graph. A final entailment check (4.) verifies the validity of the applied transformation. To demonstrate our framework's utility, we use it to induce hard negative text pairs that challenge text embedding models. Since the controllable generation makes it possible to clearly isolate different types of semantic shifts, we can evaluate text embedding models in a fine-grained way, also addressing an issue in current benchmarking where linguistic phenomena remain opaque. Human validation confirms that our transparent generation process produces texts of good quality. Notably, our way of generation is very resource-efficient, since it relies only on smaller neural networks.