AlphaMaze: Enhancing Large Language Models' Spatial Intelligence via GRPO
作者: Alan Dao, Dinh Bach Vu
分类: cs.CL
发布日期: 2025-02-20 (更新: 2025-02-25)
💡 一句话要点
AlphaMaze:利用GRPO提升大语言模型在迷宫导航中的空间智能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 视觉空间推理 迷宫导航 强化学习 监督微调 GRPO 序列决策 思维链
📋 核心要点
- 现有大语言模型在视觉空间推理方面存在不足,难以完成迷宫导航等任务。
- 提出AlphaMaze框架,通过监督微调和GRPO优化,提升模型在迷宫中的导航能力。
- 实验表明,该方法显著提升了模型在迷宫导航中的准确率,从基线的0%提升至93%。
📝 摘要(中文)
大语言模型(LLMs)在语言处理方面表现出令人印象深刻的能力,但它们在需要真正视觉空间推理的任务中常常表现不佳。本文介绍了一种新颖的两阶段训练框架,旨在使标准LLM具备迷宫导航的视觉推理能力。首先,我们在一个精心策划的token化迷宫表示数据集上利用监督微调(SFT),以教导模型预测逐步移动命令。接下来,我们应用Group Relative Policy Optimization (GRPO)——一种在DeepSeekR1中使用的技术——以及精心设计的奖励函数,以改进模型的序列决策并鼓励涌现的思维链行为。在合成生成的迷宫上的实验结果表明,虽然基线模型无法导航迷宫,但经过SFT训练的模型达到了86%的准确率,进一步的GRPO微调将准确率提高到93%。定性分析表明,GRPO培养了更强大和自我纠正的推理能力,突出了我们的方法在弥合语言模型和视觉空间任务之间差距的潜力。这些发现为机器人、自主导航以及其他需要集成视觉和序列推理的领域提供了有希望的启示。
🔬 方法详解
问题定义:论文旨在解决大语言模型在视觉空间推理方面的不足,具体表现为无法有效进行迷宫导航。现有方法难以让LLM理解和利用空间信息,从而无法做出正确的决策。
核心思路:论文的核心思路是分阶段训练LLM,首先通过监督学习让模型学习基本的导航规则,然后利用强化学习优化模型的决策能力,使其能够进行更复杂的推理和自我纠正。这种分阶段训练的方式能够有效地利用数据,并逐步提升模型的性能。
技术框架:AlphaMaze框架包含两个主要阶段:1) 监督微调(SFT):使用token化的迷宫表示数据集,训练模型预测下一步的移动命令。2) Group Relative Policy Optimization (GRPO):使用强化学习方法,通过奖励函数引导模型学习更优的导航策略。GRPO基于DeepSeekR1的思想,通过比较不同策略的性能来优化模型。
关键创新:该方法最重要的创新点在于将监督学习和强化学习相结合,并针对迷宫导航任务设计了特定的奖励函数。GRPO的使用使得模型能够进行更有效的探索和学习,从而获得更好的性能。与传统的端到端训练方法相比,该方法能够更好地利用数据,并避免模型陷入局部最优解。
关键设计:在SFT阶段,使用了token化的迷宫表示,将迷宫转化为模型可以理解的输入。在GRPO阶段,奖励函数的设计至关重要,论文中使用了精心设计的奖励函数,以鼓励模型进行正确的导航,并惩罚错误的移动。具体的参数设置和网络结构等细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
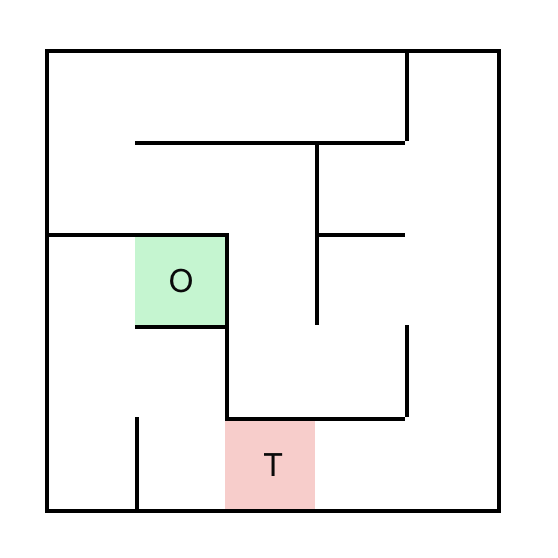
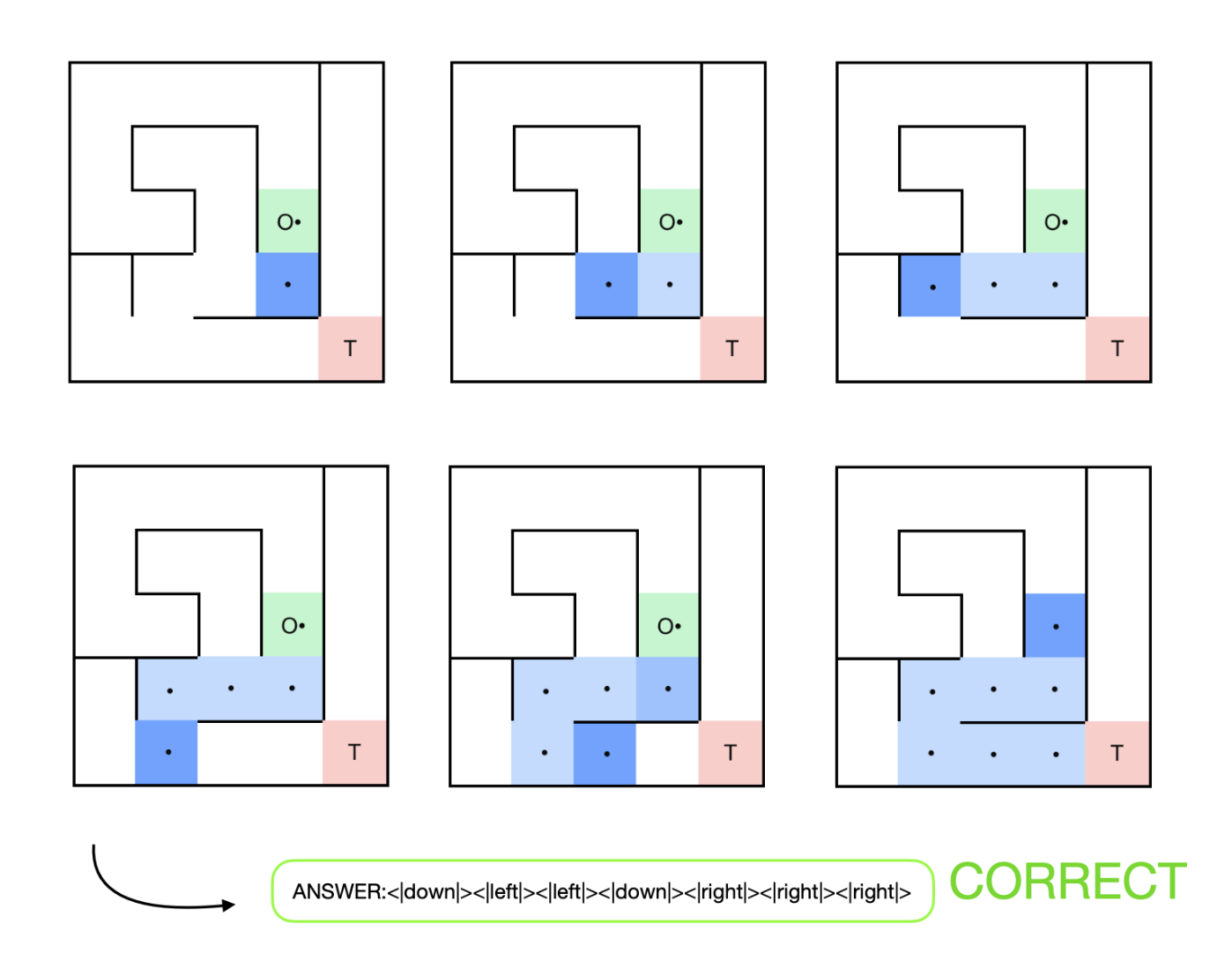
📊 实验亮点
实验结果表明,AlphaMaze框架能够显著提升LLM在迷宫导航任务中的性能。经过SFT训练的模型达到了86%的准确率,而进一步的GRPO微调将准确率提高到93%。相比之下,基线模型无法完成导航任务,准确率为0%。这些结果表明,该方法能够有效地提升LLM的视觉空间推理能力。
🎯 应用场景
该研究成果具有广泛的应用前景,包括机器人导航、自主车辆、游戏AI等领域。通过提升LLM的视觉空间推理能力,可以使其更好地理解和利用环境信息,从而实现更智能的决策和控制。未来,该方法还可以应用于更复杂的视觉空间任务,例如三维场景理解和物体操作。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive capabilities in language processing, yet they often struggle with tasks requiring genuine visual spatial reasoning. In this paper, we introduce a novel two-stage training framework designed to equip standard LLMs with visual reasoning abilities for maze navigation. First, we leverage Supervised Fine Tuning (SFT) on a curated dataset of tokenized maze representations to teach the model to predict step-by-step movement commands. Next, we apply Group Relative Policy Optimization (GRPO)-a technique used in DeepSeekR1-with a carefully crafted reward function to refine the model's sequential decision-making and encourage emergent chain-of-thought behaviors. Experimental results on synthetically generated mazes show that while a baseline model fails to navigate the maze, the SFT-trained model achieves 86% accuracy, and further GRPO fine-tuning boosts accuracy to 93%. Qualitative analyses reveal that GRPO fosters more robust and self-corrective reasoning, highlighting the potential of our approach to bridge the gap between language models and visual spatial tasks. These findings offer promising implications for applications in robotics, autonomous navigation, and other domains that require integrated visual and sequential reasoning.