Unshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
作者: Haoyu Wang, Tong Teng, Tianyu Guo, An Xiao, Duyu Tang, Hanting Chen, Yunhe Wang
分类: cs.CL
发布日期: 2025-02-20
备注: 14 pages,2 figures
💡 一句话要点
提出ESA:通过查询-键压缩实现高效选择性注意力,突破长文本上下文长度限制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 选择性注意力 查询-键压缩 高效计算 语言模型
📋 核心要点
- 现有长文本处理方法,如永久剔除或分块选择,易丢失关键信息,限制了模型性能。
- ESA通过压缩查询和键向量,在token级别高效选择关键token计算注意力,降低计算复杂度。
- 实验表明,ESA在长序列任务中优于其他选择性注意力方法,性能接近全注意力方法。
📝 摘要(中文)
大型语言模型(LLMs)高效处理长上下文序列仍然是一个重大挑战。现有的序列外推token选择方法要么采用永久剔除策略,要么按块选择token,这可能导致关键信息的丢失。我们提出了高效选择性注意力(ESA),这是一种新颖的方法,通过在token级别高效选择最关键的token来计算注意力,从而扩展上下文长度。ESA通过将查询和键向量压缩为低维表示来降低token选择的计算复杂度。我们使用上下文长度为8k和32k的开源LLM,在最大长度高达256k的长序列基准上评估ESA。ESA优于其他选择性注意力方法,尤其是在需要检索多条信息的任务中,在各种任务中实现了与全注意力外推方法相当的性能,并在某些任务中取得了更好的结果。
🔬 方法详解
问题定义:现有长文本处理方法,如Transformer,计算复杂度随序列长度呈平方增长,难以处理超长文本。已有的选择性注意力方法,如永久剔除不重要token或分块选择token,可能导致关键信息丢失,影响模型性能。因此,如何在保证关键信息不丢失的前提下,降低长文本处理的计算复杂度是一个关键问题。
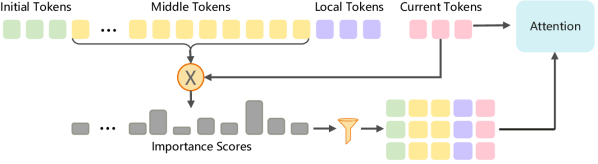
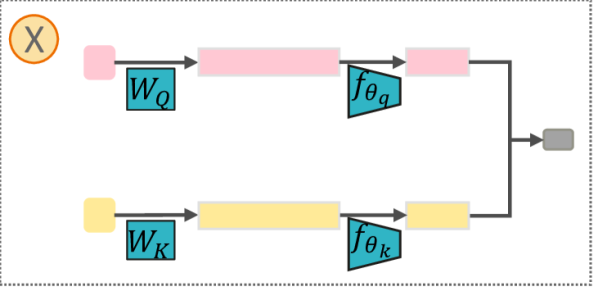
核心思路:ESA的核心思路是通过压缩查询(Query)和键(Key)向量,降低token选择的计算复杂度。具体来说,将高维的Query和Key向量投影到低维空间,然后在低维空间进行token重要性评估和选择。这样可以在计算资源有限的情况下,高效地选择出对当前任务最重要的token,从而扩展模型的有效上下文长度。
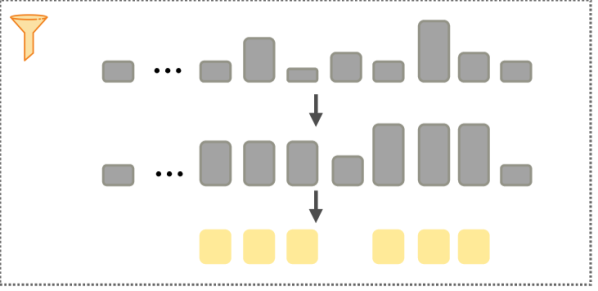
技术框架:ESA主要包含以下几个阶段:1) Query-Key压缩:使用线性投影或其他降维方法,将高维的Query和Key向量压缩到低维空间。2) Token重要性评估:在低维空间计算每个token的重要性得分,例如通过计算Query和Key向量的相似度。3) Token选择:根据重要性得分选择top-k个token,用于后续的注意力计算。4) 注意力计算:使用选择出的token计算注意力权重,并进行加权求和。
关键创新:ESA的关键创新在于将Query和Key向量压缩到低维空间进行token选择,从而显著降低了计算复杂度。与现有方法相比,ESA能够在token级别进行更精细的选择,避免了永久剔除或分块选择带来的信息损失。此外,ESA的压缩过程可以学习,从而更好地保留对当前任务重要的信息。
关键设计:ESA的关键设计包括:1) 压缩维度:选择合适的压缩维度,需要在计算复杂度和信息损失之间进行权衡。2) 重要性评估函数:选择合适的相似度度量函数,例如余弦相似度或点积。3) Token选择策略:选择合适的top-k值,需要在计算复杂度和模型性能之间进行权衡。4) 压缩矩阵初始化:压缩矩阵的初始化方式对模型性能有一定影响,可以使用随机初始化或预训练的embedding。
🖼️ 关键图片
📊 实验亮点
ESA在长序列基准测试中表现出色,尤其是在需要检索多条信息的任务中。实验结果表明,ESA在各种任务中实现了与全注意力外推方法相当的性能,并在某些任务中取得了更好的结果。例如,在长度为256k的序列上,ESA能够有效地检索到关键信息,并生成高质量的摘要。
🎯 应用场景
ESA具有广泛的应用前景,例如长文档摘要、长篇小说生成、代码补全、医疗记录分析等需要处理长文本的领域。通过扩展模型的有效上下文长度,ESA可以帮助模型更好地理解长文本中的依赖关系,从而提高模型在这些任务上的性能。此外,ESA还可以应用于资源受限的设备上,例如移动设备或嵌入式系统,从而实现更高效的AI应用。
📄 摘要(原文)
Handling long-context sequences efficiently remains a significant challenge in large language models (LLMs). Existing methods for token selection in sequence extrapolation either employ a permanent eviction strategy or select tokens by chunk, which may lead to the loss of critical information. We propose Efficient Selective Attention (ESA), a novel approach that extends context length by efficiently selecting the most critical tokens at the token level to compute attention. ESA reduces the computational complexity of token selection by compressing query and key vectors into lower-dimensional representations. We evaluate ESA on long sequence benchmarks with maximum lengths up to 256k using open-source LLMs with context lengths of 8k and 32k. ESA outperforms other selective attention methods, especially in tasks requiring the retrieval of multiple pieces of information, achieving comparable performance to full-attention extrapolation methods across various tasks, with superior results in certain tasks.