PredictaBoard: Benchmarking LLM Score Predictability
作者: Lorenzo Pacchiardi, Konstantinos Voudouris, Ben Slater, Fernando Martínez-Plumed, José Hernández-Orallo, Lexin Zhou, Wout Schellaert
分类: cs.CL, cs.AI, stat.ML
发布日期: 2025-02-20 (更新: 2025-06-17)
备注: Accepted at ACL Findings 2025
🔗 代码/项目: GITHUB
💡 一句话要点
PredictaBoard:评估LLM预测能力,提升AI系统安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可预测性 基准测试 安全AI 错误预测
📋 核心要点
- LLM的不可预测性阻碍了其安全部署,需要有效识别和利用LLM的“安全区”以降低风险。
- PredictaBoard通过评估“评估器”预测LLM在特定任务实例上出错的能力,来衡量LLM的可预测性。
- 实验表明,PredictaBoard强调了评估可预测性与性能同等重要的地位,为更安全的AI系统奠定基础。
📝 摘要(中文)
大型语言模型(LLM)虽然具备强大的能力,但常常表现出不可预测的失败,即使在基本的常识推理任务中也表现出不一致的成功率。这种不可预测性对确保其安全部署构成了重大挑战,因为识别并安全地在其可靠的“安全区”内运行对于降低风险至关重要。为了解决这个问题,我们提出了PredictaBoard,这是一个新颖的协作基准测试框架,旨在评估分数预测器(称为评估器)预测LLM在现有数据集中的特定任务实例(即,提示)上出错的能力。PredictaBoard通过考虑不同容错误差下的拒绝率来评估LLM和评估器的配对。因此,PredictaBoard旨在促进对开发更好的评估器和使LLM更具可预测性的研究,而不仅仅是提高平均性能。我们使用基线评估器和最先进的LLM进行了说明性实验。PredictaBoard强调了评估可预测性以及性能的关键需求,为更安全的AI系统铺平了道路,在这些系统中,不仅可以最大限度地减少错误,还可以预测和有效缓解错误。我们的基准测试代码可在https://github.com/Kinds-of-Intelligence-CFI/PredictaBoard 找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的不可预测性问题。即使在简单的常识推理任务中,LLM也可能出现意料之外的错误,这使得安全部署LLM变得困难。现有的评估方法主要关注LLM的平均性能,而忽略了其可预测性,即能否提前预知LLM在哪些情况下会出错。
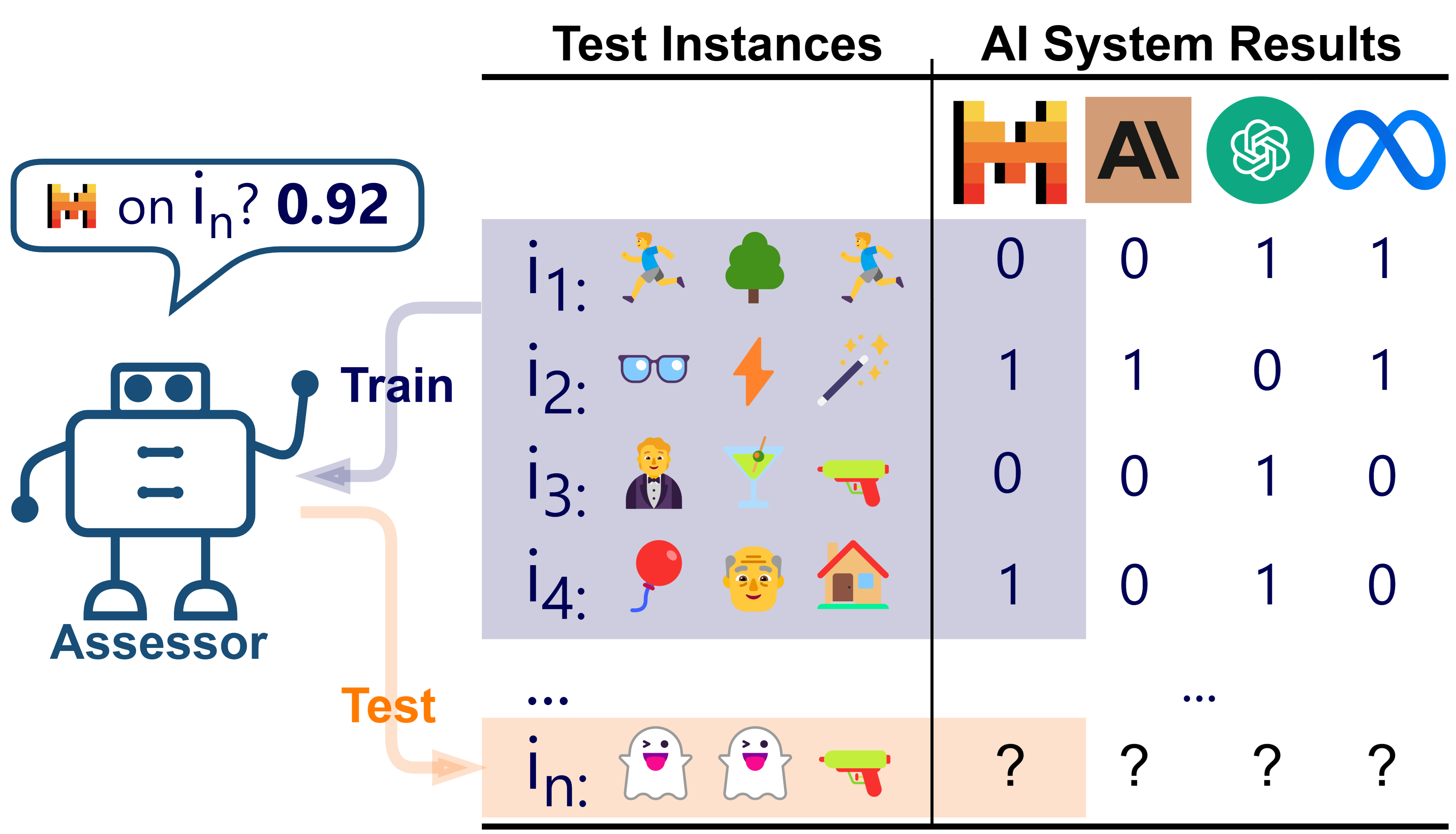
核心思路:论文的核心思路是构建一个基准测试框架,用于评估“评估器”预测LLM错误的能力。通过评估评估器预测LLM在特定任务实例(即prompt)上出错的能力,来衡量LLM的可预测性。如果一个LLM的错误能够被准确预测,那么就可以通过拒绝执行这些可能出错的任务来提高系统的安全性。
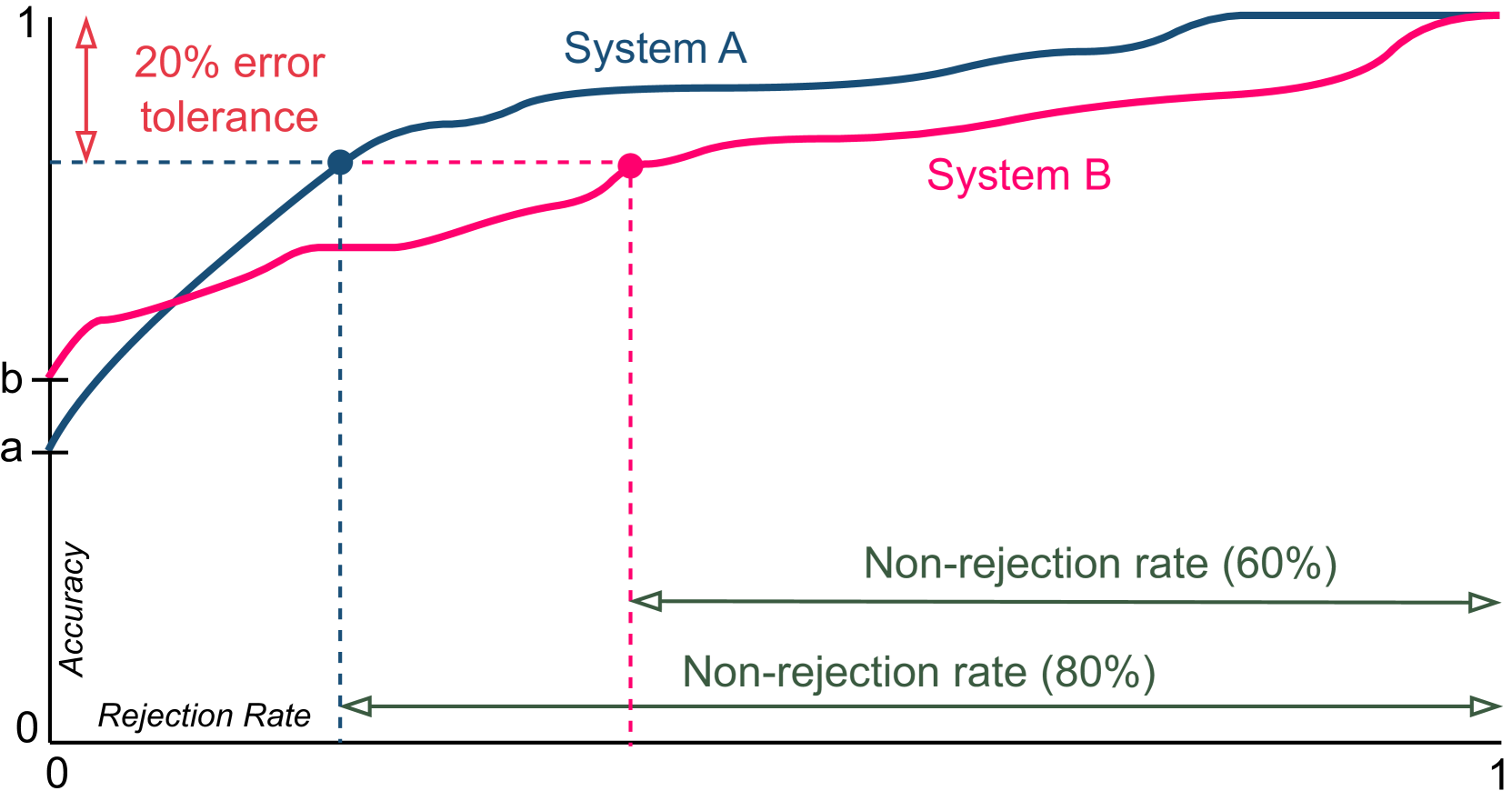
技术框架:PredictaBoard框架包含以下主要组成部分:1) LLM:待评估的大型语言模型。2) 评估器(Assessor):用于预测LLM在特定任务实例上是否会出错的模型。评估器接收任务实例作为输入,并输出一个分数,该分数表示LLM在该实例上出错的可能性。3) 数据集:包含一系列任务实例(prompt)和对应的正确答案。4) 评估指标:基于不同容错误差下的拒绝率来评估LLM和评估器的配对。通过调整拒绝阈值,可以控制系统的安全性和性能之间的权衡。
关键创新:PredictaBoard的关键创新在于它将可预测性作为评估LLM的重要指标,并提供了一个统一的框架来衡量和比较不同LLM的可预测性。与传统的评估方法不同,PredictaBoard不仅关注LLM的平均性能,还关注其在特定任务实例上的表现是否可预测。这使得开发者能够更好地了解LLM的局限性,并采取相应的措施来提高系统的安全性。
关键设计:PredictaBoard的关键设计包括:1) 评估器的选择:可以使用各种不同的模型作为评估器,例如基于规则的模型、机器学习模型或另一个LLM。2) 拒绝阈值的设置:拒绝阈值决定了系统拒绝执行哪些任务实例。较高的拒绝阈值可以提高系统的安全性,但也会降低系统的性能。3) 评估指标的选择:论文使用基于不同容错误差下的拒绝率来评估LLM和评估器的配对。其他可能的评估指标包括准确率、召回率和F1值。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了PredictaBoard框架的有效性,并展示了如何使用该框架来评估不同LLM的可预测性。实验结果表明,即使是性能优异的LLM也可能存在不可预测的错误。PredictaBoard能够帮助开发者识别这些错误,并采取相应的措施来提高系统的安全性。
🎯 应用场景
PredictaBoard可应用于各种需要安全可靠的AI系统,例如自动驾驶、医疗诊断和金融风险管理。通过评估和提高LLM的可预测性,可以降低系统出错的风险,并提高用户对AI系统的信任度。该研究成果有助于推动AI技术的安全可靠应用。
📄 摘要(原文)
Despite possessing impressive skills, Large Language Models (LLMs) often fail unpredictably, demonstrating inconsistent success in even basic common sense reasoning tasks. This unpredictability poses a significant challenge to ensuring their safe deployment, as identifying and operating within a reliable "safe zone" is essential for mitigating risks. To address this, we present PredictaBoard, a novel collaborative benchmarking framework designed to evaluate the ability of score predictors (referred to as assessors) to anticipate LLM errors on specific task instances (i.e., prompts) from existing datasets. PredictaBoard evaluates pairs of LLMs and assessors by considering the rejection rate at different tolerance errors. As such, PredictaBoard stimulates research into developing better assessors and making LLMs more predictable, not only with a higher average performance. We conduct illustrative experiments using baseline assessors and state-of-the-art LLMs. PredictaBoard highlights the critical need to evaluate predictability alongside performance, paving the way for safer AI systems where errors are not only minimised but also anticipated and effectively mitigated. Code for our benchmark can be found at https://github.com/Kinds-of-Intelligence-CFI/PredictaBoard