English Please: Evaluating Machine Translation with Large Language Models for Multilingual Bug Reports
作者: Avinash Patil, Siru Tao, Aryan Jadon
分类: cs.CL, cs.SE
发布日期: 2025-02-20 (更新: 2025-05-08)
备注: 8 Pages, 4 Figures, 3 Tables
🔗 代码/项目: GITHUB
💡 一句话要点
首个多语言Bug报告机器翻译评估:对比大型语言模型与传统翻译模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 Bug报告 大型语言模型 软件工程 多语言协作
📋 核心要点
- 全球软件开发中,准确翻译Bug报告至关重要,但现有机器翻译模型在技术领域的表现有待评估。
- 该研究对比了多种大型语言模型和传统翻译模型在Bug报告翻译任务上的性能,侧重于质量和语言识别。
- 实验结果表明,不同模型在翻译质量和语言识别上各有优劣,强调了针对特定任务进行模型选择的重要性。
📝 摘要(中文)
本研究首次对Bug报告的机器翻译(MT)性能进行了全面评估,分析了DeepL、AWS Translate以及包括ChatGPT、Claude、Gemini、LLaMA和Mistral等大型语言模型的能力。研究使用了Visual Studio Code GitHub仓库中标记为“english-please”的报告数据。为了评估翻译质量和源语言识别的准确性,采用了包括BLEU、BERTScore、COMET、METEOR和ROUGE在内的一系列MT评估指标,以及准确率、精确率、召回率和F1分数等分类指标。结果表明,ChatGPT (gpt-4o)在语义和词汇翻译质量方面表现出色,但在源语言识别方面并不领先。Claude和Mistral取得了最高的F1分数(分别为0.7182和0.7142),Gemini记录了最佳的精确率(0.7414)。AWS Translate在识别源语言方面表现出最高的准确率(0.4717)。这些结果表明,没有一个单一系统在所有任务中都占据主导地位,强调了特定任务评估的重要性。本研究强调了在翻译技术内容时进行领域自适应的必要性,并为将MT集成到Bug分类工作流程中提供了可操作的见解。该论文的代码和数据集可在GitHub上获取。
🔬 方法详解
问题定义:论文旨在解决多语言软件开发中,Bug报告翻译质量不高的问题。现有机器翻译模型在通用领域表现良好,但在技术文档,特别是Bug报告这种专业性较强的文本上,翻译质量难以保证,影响国际协作效率。此外,准确识别Bug报告的原始语言也是一个挑战。
核心思路:核心思路是通过对比多种机器翻译模型(包括传统模型和大型语言模型)在Bug报告翻译任务上的表现,找出最适合该任务的模型。同时,评估模型识别源语言的能力,为自动化的Bug分类和处理流程提供支持。
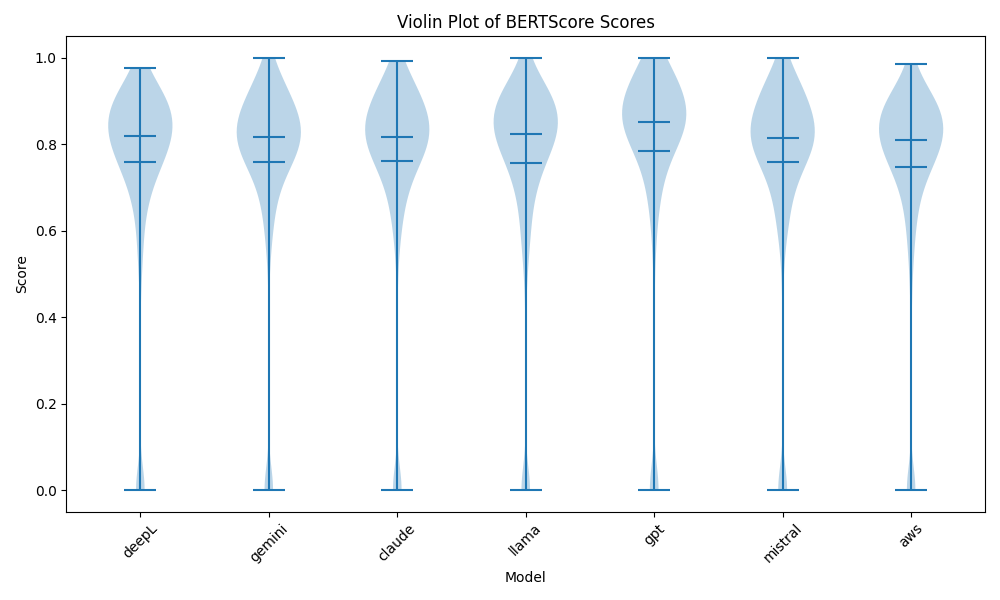
技术框架:整体流程包括:1) 从Visual Studio Code GitHub仓库收集带有“english-please”标签的Bug报告数据;2) 使用DeepL、AWS Translate、ChatGPT、Claude、Gemini、LLaMA和Mistral等模型进行翻译;3) 使用BLEU、BERTScore、COMET、METEOR和ROUGE等指标评估翻译质量;4) 使用准确率、精确率、召回率和F1分数等指标评估源语言识别的准确性;5) 对比不同模型的性能,分析其优缺点。
关键创新:该研究是首次针对Bug报告的机器翻译性能进行全面评估。它不仅对比了多种模型的翻译质量,还评估了模型识别源语言的能力。研究结果为选择合适的机器翻译模型,以及优化Bug分类和处理流程提供了有价值的参考。
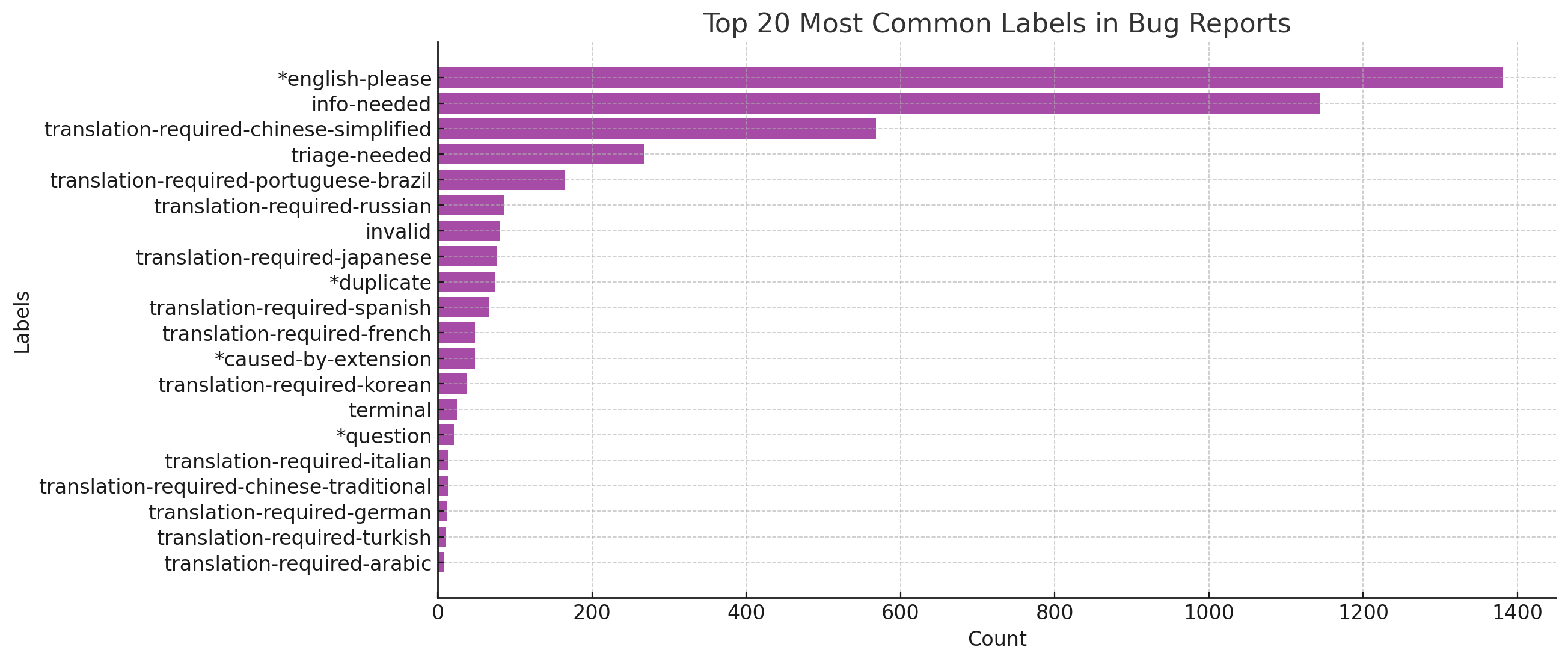
关键设计:研究使用了Visual Studio Code GitHub仓库中标记为“english-please”的Bug报告作为数据集。评估指标包括BLEU、BERTScore、COMET、METEOR和ROUGE等,用于衡量翻译质量。准确率、精确率、召回率和F1分数用于评估源语言识别的准确性。研究没有特别提到对模型进行微调或修改,而是直接使用了现有模型的API。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ChatGPT (gpt-4o)在语义和词汇翻译质量方面表现出色,但源语言识别能力一般。Claude和Mistral在源语言识别方面取得了最高的F1分数(分别为0.7182和0.7142),Gemini的精确率最高(0.7414)。AWS Translate在识别源语言方面表现出最高的准确率(0.4717)。没有一个模型在所有任务中都占据主导地位。
🎯 应用场景
该研究成果可应用于全球化软件开发团队,提升跨语言协作效率。通过自动翻译Bug报告,可以减少语言障碍,加速问题定位和修复。此外,源语言识别技术可用于自动化的Bug分类和处理,提高软件维护效率。未来,可将研究成果应用于其他技术文档的翻译,例如API文档、用户手册等。
📄 摘要(原文)
Accurate translation of bug reports is critical for efficient collaboration in global software development. In this study, we conduct the first comprehensive evaluation of machine translation (MT) performance on bug reports, analyzing the capabilities of DeepL, AWS Translate, and large language models such as ChatGPT, Claude, Gemini, LLaMA, and Mistral using data from the Visual Studio Code GitHub repository, specifically focusing on reports labeled with the english-please tag. To assess both translation quality and source language identification accuracy, we employ a range of MT evaluation metrics-including BLEU, BERTScore, COMET, METEOR, and ROUGE-alongside classification metrics such as accuracy, precision, recall, and F1-score. Our findings reveal that while ChatGPT (gpt-4o) excels in semantic and lexical translation quality, it does not lead in source language identification. Claude and Mistral achieve the highest F1-scores (0.7182 and 0.7142, respectively), and Gemini records the best precision (0.7414). AWS Translate shows the highest accuracy (0.4717) in identifying source languages. These results highlight that no single system dominates across all tasks, reinforcing the importance of task-specific evaluations. This study underscores the need for domain adaptation when translating technical content and provides actionable insights for integrating MT into bug-triaging workflows. The code and dataset for this paper are available at GitHub-https://github.com/av9ash/English-Please