GneissWeb: Preparing High Quality Data for LLMs at Scale
作者: Hajar Emami Gohari, Swanand Ravindra Kadhe, Syed Yousaf Shah, Constantin Adam, Abdulhamid Adebayo, Praneet Adusumilli, Farhan Ahmed, Nathalie Baracaldo Angel, Santosh Subhashrao Borse, Yuan-Chi Chang, Xuan-Hong Dang, Nirmit Desai, Revital Eres, Ran Iwamoto, Alexei Karve, Yan Koyfman, Wei-Han Lee, Changchang Liu, Boris Lublinsky, Takuyo Ohko, Pablo Pesce, Maroun Touma, Shiqiang Wang, Shalisha Witherspoon, Herbert Woisetschläger, David Wood, Kun-Lung Wu, Issei Yoshida, Syed Zawad, Petros Zerfos, Yi Zhou, Bishwaranjan Bhattacharjee
分类: cs.CL, cs.AI
发布日期: 2025-02-19 (更新: 2025-07-29)
💡 一句话要点
GneissWeb:构建高质量大规模LLM训练数据集,提升模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据集 数据清洗 数据去重 质量过滤
📋 核心要点
- 现有公开LLM预训练数据集规模较小,限制了大型模型的训练效果,高质量数据获取困难。
- GneissWeb通过分片去重和质量过滤,构建了一个包含10万亿tokens的高质量大规模数据集。
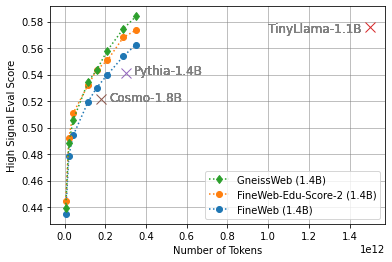
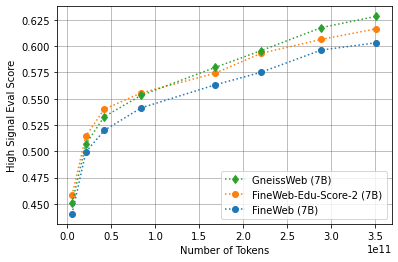
- 实验表明,使用GneissWeb训练的模型在多个基准测试中优于使用FineWeb-V1.1.0训练的模型。
📝 摘要(中文)
数据量和数据质量在决定大型语言模型(LLM)的性能方面起着至关重要的作用。特别是高质量的数据,可以显著提高LLM在各种下游任务上的泛化能力。领先LLM的大规模预训练数据集仍然不对公众开放,而许多开放数据集的规模较小(少于5万亿tokens),限制了它们训练大型模型的适用性。本文介绍了GneissWeb,一个产生约10万亿tokens的大型数据集,满足了训练LLM的数据质量和数量要求。我们的GneissWeb方案生成的数据集包含分片精确子字符串去重和精心构建的质量过滤器集合。GneissWeb在数据质量和数量之间实现了良好的平衡,产生的模型优于在最先进的开放大型数据集(5万亿+ tokens)上训练的模型。我们表明,使用GneissWeb数据集训练的模型在11个常用基准(零样本和少样本)上计算的平均得分方面,比使用FineWeb-V1.1.0训练的模型高出2.73个百分点。当评估集扩展到20个基准(零样本和少样本)时,使用GneissWeb训练的模型仍然比使用FineWeb-V1.1.0训练的模型高出1.75个百分点。
🔬 方法详解
问题定义:论文旨在解决现有公开LLM预训练数据集规模小、质量参差不齐的问题。现有方法难以满足训练高性能LLM对高质量、大规模数据的需求,导致模型泛化能力受限。现有数据集可能包含大量重复或低质量文本,影响模型学习效率和最终性能。
核心思路:论文的核心思路是通过构建一个大规模、高质量的预训练数据集GneissWeb来提升LLM的性能。关键在于数据清洗和过滤,去除重复和低质量数据,保留高质量文本,从而提高模型的学习效率和泛化能力。通过数据质量和数量的平衡,实现更好的模型性能。
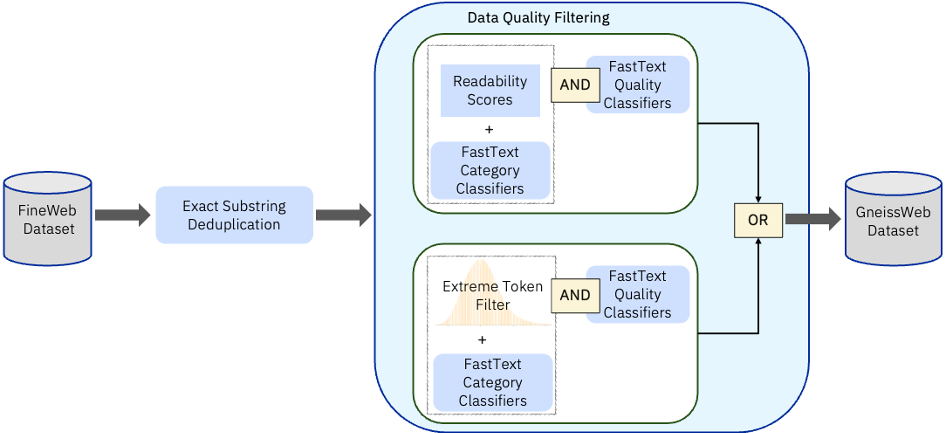
技术框架:GneissWeb的构建流程主要包含以下几个阶段:1) 数据收集:从互联网上抓取大量文本数据。2) 分片精确子字符串去重:使用分片技术进行精确的子字符串去重,消除数据集中的冗余信息。3) 质量过滤:应用一系列精心设计的质量过滤器,去除低质量、噪声数据。这些过滤器可能包括基于语言模型困惑度的过滤器、基于规则的过滤器等。4) 数据集构建:将清洗后的数据整合为GneissWeb数据集。
关键创新:论文的关键创新在于数据集构建流程中采用的分片精确子字符串去重方法和质量过滤器集合。分片去重能够高效地处理大规模数据集的去重问题,质量过滤器集合能够有效地去除低质量数据,从而保证数据集的整体质量。这种数据清洗和过滤策略是提升LLM性能的关键。
关键设计:论文中关于参数设置、损失函数和网络结构的具体技术细节未详细描述。质量过滤器的具体实现方式(例如,使用的语言模型、规则的具体内容)也未给出。分片去重的具体分片策略和实现细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用GneissWeb数据集训练的模型在11个常用基准测试中,平均得分比使用FineWeb-V1.1.0训练的模型高出2.73个百分点。当评估集扩展到20个基准测试时,GneissWeb训练的模型仍然比FineWeb-V1.1.0训练的模型高出1.75个百分点。这些结果证明了GneissWeb数据集的有效性,以及高质量数据对LLM性能的重要性。
🎯 应用场景
GneissWeb数据集可用于训练各种大型语言模型,提升模型在自然语言处理任务中的性能,例如文本生成、机器翻译、问答系统等。该数据集的构建方法也可应用于其他领域,为训练高质量的AI模型提供数据基础。未来,GneissWeb可以促进开源LLM的发展,降低训练高性能LLM的门槛。
📄 摘要(原文)
Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.