MoM: Linear Sequence Modeling with Mixture-of-Memories
作者: Jusen Du, Weigao Sun, Disen Lan, Jiaxi Hu, Yu Cheng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-19 (更新: 2025-11-18)
备注: Technical report, 18 pages
💡 一句话要点
提出MoM:一种混合记忆的线性序列建模方法,提升长序列召回能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性序列建模 混合记忆 长序列建模 路由网络 高召回率任务
📋 核心要点
- 线性序列模型将长序列压缩到单一记忆状态,在召回密集型任务中性能受限。
- MoM通过多个独立记忆状态和路由网络,提升记忆容量并减少记忆干扰。
- MoM在训练时保持线性复杂度,推理时保持常数复杂度,并在实验中超越现有线性模型。
📝 摘要(中文)
线性序列建模方法,如线性注意力、状态空间模型和线性RNN,通过降低训练和推理的复杂度,显著提高了效率。然而,这些方法通常将整个输入序列压缩成单个固定大小的记忆状态,导致在需要高召回率的任务上表现欠佳。为了解决这个限制,我们引入了一种名为混合记忆(MoM)的新架构。MoM利用多个独立的记忆状态,并通过一个路由网络将输入token导向特定的记忆状态。这种方法极大地提高了整体记忆容量,同时最大限度地减少了记忆干扰。MoM作为一个通用框架,可以与线性模型中各种不同的记忆更新机制无缝结合。因此,MoM在需要高召回率的任务上表现出色,超越了现有的线性序列建模技术。尽管MoM结合了多个记忆状态,但每个记忆状态的计算复杂度仍然是线性的,这使得MoM在训练期间保持了线性复杂度的优势,而在推理期间保持了常数复杂度。实验结果表明,MoM在下游语言任务,特别是需要高召回率的任务上,优于当前的线性序列模型,甚至达到了与Transformer模型相当的性能。代码已在https://github.com/OpenSparseLLMs/MoM 和 https://github.com/OpenSparseLLMs/Linear-MoE 上发布。
🔬 方法详解
问题定义:现有线性序列模型,如线性注意力、状态空间模型等,虽然在计算效率上有所提升,但由于它们将整个输入序列压缩到一个固定大小的记忆状态中,导致在需要高召回率的任务上表现不佳。这些模型难以记住长序列中的所有重要信息,从而影响性能。
核心思路:MoM的核心思路是使用多个独立的记忆状态来存储输入序列的信息,并使用一个路由网络来决定每个输入token应该被写入哪个记忆状态。通过这种方式,MoM可以显著提高整体的记忆容量,同时减少不同token之间的记忆干扰,从而提升模型在召回密集型任务上的性能。
技术框架:MoM的整体架构包含以下几个主要模块:1) 输入嵌入层:将输入token转换为向量表示。2) 路由网络:根据输入token的特征,决定将其分配到哪个记忆状态。3) 多个独立的记忆状态:每个记忆状态使用线性序列模型进行更新。4) 输出层:将多个记忆状态的信息进行聚合,生成最终的输出。整个流程是,输入token经过嵌入后,由路由网络分配到不同的记忆状态,每个记忆状态独立更新,最后将所有记忆状态的信息合并用于预测。
关键创新:MoM最重要的技术创新点在于引入了混合记忆机制,即使用多个独立的记忆状态来存储序列信息,并使用路由网络来动态地分配输入token到不同的记忆状态。这与传统的线性序列模型只使用单个记忆状态有本质区别,使得模型能够更好地处理长序列和需要高召回率的任务。
关键设计:MoM的关键设计包括:1) 路由网络的选择:可以使用各种神经网络结构,如MLP或注意力机制。2) 记忆状态的更新机制:可以使用各种线性序列模型,如线性注意力或状态空间模型。3) 记忆状态数量的选择:需要根据任务的复杂度和序列长度进行调整。4) 损失函数的设计:可以使用交叉熵损失或其它适合特定任务的损失函数。
🖼️ 关键图片


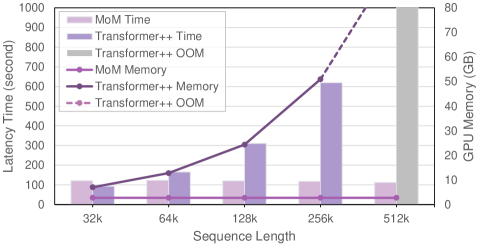
📊 实验亮点
实验结果表明,MoM在需要高召回率的语言任务上显著优于现有的线性序列模型,并且在某些任务上达到了与Transformer模型相当的性能。具体来说,MoM在LRA基准测试中取得了显著的提升,尤其是在Pathfinder任务上。此外,MoM在长文本分类和问答任务上也表现出色,证明了其在处理长序列数据方面的优势。
🎯 应用场景
MoM可应用于需要处理长序列并具有高召回率要求的各种领域,例如:长文本建模、对话系统、知识图谱推理、生物信息学中的基因序列分析等。该方法能够提升模型在这些任务上的记忆能力和性能,具有广泛的应用前景和实际价值。未来,MoM有望成为处理长序列数据的重要工具。
📄 摘要(原文)
Linear sequence modeling methods, such as linear attention, state space modeling, and linear RNNs, offer significant efficiency improvements by reducing the complexity of training and inference. However, these methods typically compress the entire input sequence into a single fixed-size memory state, which leads to suboptimal performance on recall-intensive tasks. To address this limitation, we introduce a novel architecture called Mixture-of-Memories (MoM). MoM utilizes multiple independent memory states, with a router network directing input tokens to specific memory states. This approach greatly enhances the overall memory capacity while minimizing memory interference. MoM serves as a general framework that can be seamlessly combined with diverse memory update mechanisms across linear models. As a result, MoM performs exceptionally well on recall-intensive tasks, surpassing existing linear sequence modeling techniques. Despite incorporating multiple memory states, the computation of each memory state remains linear in complexity, allowing MoM to retain the linear-complexity advantage during training, while constant-complexity during inference. Our experimental results show that MoM outperforms current linear sequence models on downstream language tasks, particularly recall-intensive tasks, and even achieves performance comparable to Transformer models. The code is released at https://github.com/OpenSparseLLMs/MoM and is also released as a part of https://github.com/OpenSparseLLMs/Linear-MoE.