Instruction Tuning on Public Government and Cultural Data for Low-Resource Language: a Case Study in Kazakh
作者: Nurkhan Laiyk, Daniil Orel, Rituraj Joshi, Maiya Goloburda, Yuxia Wang, Preslav Nakov, Fajri Koto
分类: cs.CL
发布日期: 2025-02-19 (更新: 2025-08-31)
💡 一句话要点
针对低资源语言哈萨克语,提出基于政府和文化数据的指令调优方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 低资源语言 哈萨克语 LLM辅助数据生成 人工验证 政府数据 文化数据
📋 核心要点
- 低资源语言指令调优面临数据匮乏,尤其在政府和文化领域,限制了LLM在该领域的应用。
- 论文提出利用LLM辅助生成高质量指令跟随数据集,并进行人工验证,提升模型对特定领域知识的理解。
- 实验表明,在构建的数据集上微调Qwen、Falcon和Gemma等模型,在多项选择和生成任务中均有显著提升。
📝 摘要(中文)
由于文本数据有限,特别是政府和文化领域,低资源语言的指令调优仍未得到充分探索。为了解决这个问题,我们引入并开源了一个大规模(10,600个样本)的指令跟随(IFT)数据集,涵盖了与哈萨克斯坦相关的关键机构和文化知识。我们的数据集增强了LLM对程序、法律和结构治理主题的理解。我们采用LLM辅助的数据生成,比较了开放权重和封闭权重模型用于数据集构建,并选择GPT-4o作为骨干模型。我们数据集的每个实体都经过完整的手动验证,以确保高质量。我们还表明,在我们的数据集上微调Qwen、Falcon和Gemma可以在多项选择和生成任务中带来一致的性能改进,证明了LLM辅助指令调优在低资源语言中的潜力。
🔬 方法详解
问题定义:论文旨在解决低资源语言(如哈萨克语)在政府和文化领域缺乏高质量指令调优数据的问题。现有方法受限于数据规模和质量,导致LLM难以理解和应用相关领域的知识。这阻碍了LLM在这些低资源语言环境中的实际应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)辅助生成指令跟随数据,并结合人工验证来保证数据质量。通过这种方式,可以克服低资源语言数据稀缺的挑战,构建高质量的指令调优数据集,从而提升LLM在特定领域的性能。
技术框架:整体框架包含以下几个主要阶段: 1. LLM辅助数据生成:使用LLM(如GPT-4o)生成初始的指令跟随数据。 2. 数据过滤与选择:对生成的数据进行初步筛选,去除低质量或不相关的数据。 3. 人工验证与修正:由人工专家对数据进行逐条验证和修正,确保数据的准确性和一致性。 4. 数据集构建:将验证后的数据整理成最终的指令调优数据集。 5. 模型微调:使用构建的数据集对LLM(如Qwen、Falcon、Gemma)进行微调。
关键创新:论文的关键创新在于结合LLM辅助生成和人工验证,构建高质量的低资源语言指令调优数据集。这种方法既能利用LLM的生成能力,又能通过人工干预保证数据的质量,从而克服了低资源语言数据稀缺和质量差的挑战。与完全依赖人工标注或完全依赖LLM生成的方法相比,该方法在效率和质量之间取得了更好的平衡。
关键设计:论文的关键设计包括: 1. LLM选择:选择GPT-4o作为数据生成的骨干模型,因为它在生成质量和效率方面表现出色。 2. 指令设计:设计了涵盖程序、法律和结构治理等主题的指令,以覆盖哈萨克斯坦的关键机构和文化知识。 3. 人工验证流程:建立了严格的人工验证流程,包括数据准确性、一致性和相关性的检查。 4. 模型微调策略:采用标准的微调策略,并针对不同的LLM(Qwen、Falcon、Gemma)进行参数调整,以获得最佳性能。
🖼️ 关键图片


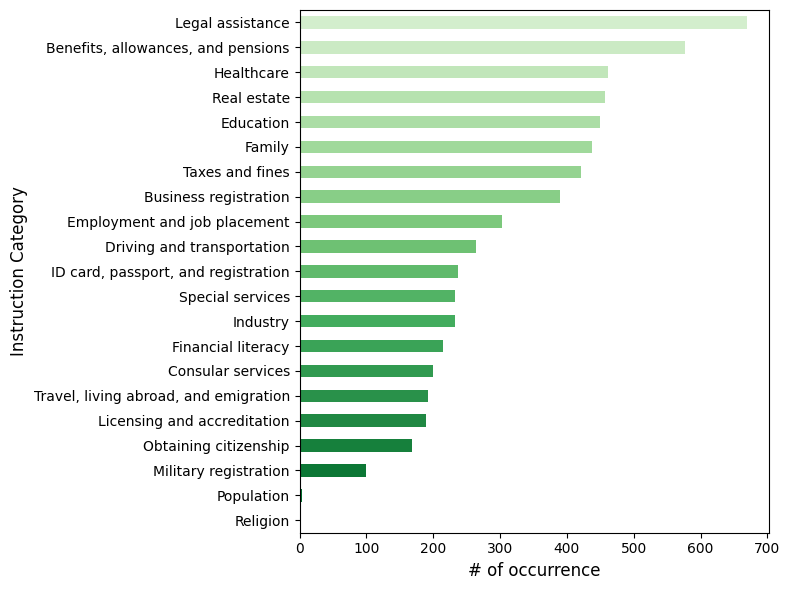
📊 实验亮点
实验结果表明,在构建的数据集上微调Qwen、Falcon和Gemma等模型,在多项选择和生成任务中均取得了显著的性能提升。具体性能数据未知,但论文强调了在多种任务和模型上的一致性提升,证明了该数据集的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于低资源语言的智能政务、文化传承、法律咨询等领域。通过提升LLM对特定领域知识的理解,可以开发出更智能、更贴合当地需求的AI应用,例如智能客服、法律法规查询、文化知识问答等,从而促进低资源语言地区的信息化发展。
📄 摘要(原文)
Instruction tuning in low-resource languages remains underexplored due to limited text data, particularly in government and cultural domains. To address this, we introduce and open-source a large-scale (10,600 samples) instruction-following (IFT) dataset, covering key institutional and cultural knowledge relevant to Kazakhstan. Our dataset enhances LLMs' understanding of procedural, legal, and structural governance topics. We employ LLM-assisted data generation, comparing open-weight and closed-weight models for dataset construction, and select GPT-4o as the backbone. Each entity of our dataset undergoes full manual verification to ensure high quality. We also show that fine-tuning Qwen, Falcon, and Gemma on our dataset leads to consistent performance improvements in both multiple-choice and generative tasks, demonstrating the potential of LLM-assisted instruction tuning for low-resource languages.