MMTEB: Massive Multilingual Text Embedding Benchmark
作者: Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemiński, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Gabriel Sequeira, Diganta Misra, Shreeya Dhakal, Jonathan Rystrøm, Roman Solomatin, Ömer Çağatan, Akash Kundu, Martin Bernstorff, Shitao Xiao, Akshita Sukhlecha, Bhavish Pahwa, Rafał Poświata, Kranthi Kiran GV, Shawon Ashraf, Daniel Auras, Björn Plüster, Jan Philipp Harries, Loïc Magne, Isabelle Mohr, Mariya Hendriksen, Dawei Zhu, Hippolyte Gisserot-Boukhlef, Tom Aarsen, Jan Kostkan, Konrad Wojtasik, Taemin Lee, Marek Šuppa, Crystina Zhang, Roberta Rocca, Mohammed Hamdy, Andrianos Michail, John Yang, Manuel Faysse, Aleksei Vatolin, Nandan Thakur, Manan Dey, Dipam Vasani, Pranjal Chitale, Simone Tedeschi, Nguyen Tai, Artem Snegirev, Michael Günther, Mengzhou Xia, Weijia Shi, Xing Han Lù, Jordan Clive, Gayatri Krishnakumar, Anna Maksimova, Silvan Wehrli, Maria Tikhonova, Henil Panchal, Aleksandr Abramov, Malte Ostendorff, Zheng Liu, Simon Clematide, Lester James Miranda, Alena Fenogenova, Guangyu Song, Ruqiya Bin Safi, Wen-Ding Li, Alessia Borghini, Federico Cassano, Hongjin Su, Jimmy Lin, Howard Yen, Lasse Hansen, Sara Hooker, Chenghao Xiao, Vaibhav Adlakha, Orion Weller, Siva Reddy, Niklas Muennighoff
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-02-19 (更新: 2025-11-13)
备注: Accepted for ICLR: https://openreview.net/forum?id=zl3pfz4VCV
💡 一句话要点
提出大规模多语言文本嵌入基准MMTEB,用于全面评估文本嵌入模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 多语言 基准测试 自然语言处理 信息检索
📋 核心要点
- 现有文本嵌入评估任务在语言、领域和任务多样性方面存在局限性,无法全面评估模型性能。
- MMTEB通过大规模收集多语言、多领域的评估任务,并采用降采样和负样本挖掘等技术优化评估流程。
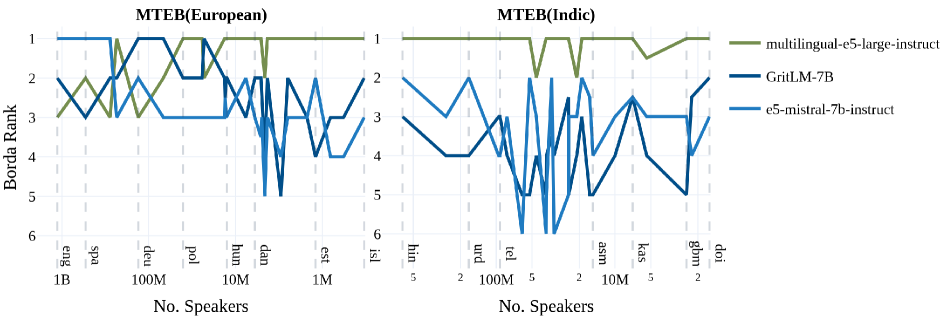
- 实验表明,尽管大型语言模型表现出色,但一个相对较小的模型multilingual-e5-large-instruct在公开模型中表现最佳。
📝 摘要(中文)
本文介绍大规模多语言文本嵌入基准(MMTEB),它是MTEB的一个大规模、社区驱动的扩展,涵盖超过250种语言的500多个质量控制的评估任务。MMTEB包含各种具有挑战性的新任务,例如指令跟随、长文档检索和代码检索,代表了迄今为止最大的嵌入模型多语言评估任务集合。利用这个集合,我们开发了几个高度多语言的基准,并用它们来评估一组具有代表性的模型。我们发现,虽然具有数十亿参数的大型语言模型(LLM)可以在某些语言子集和任务类别上实现最先进的性能,但性能最佳的公开可用模型是只有5.6亿参数的multilingual-e5-large-instruct。为了方便访问并降低计算成本,我们引入了一种基于任务间相关性的新型降采样方法,确保多样化的选择,同时保持相对模型排名。此外,我们通过采样困难负样本来优化检索等任务,创建更小但有效的分割。这些优化使我们能够引入大大降低计算需求的基准。例如,我们新引入的零样本英语基准保持了与完整版本相似的排名顺序,但计算成本却大大降低。
🔬 方法详解
问题定义:现有文本嵌入模型的评估通常局限于少量任务,这些任务在语言、领域和任务类型上都存在很大的局限性。这使得我们难以全面了解模型在不同场景下的泛化能力和实际性能。因此,需要一个更全面、更具挑战性的评估基准来推动文本嵌入技术的发展。
核心思路:MMTEB的核心思路是通过构建一个大规模、多语言、多任务的评估基准,来更全面地评估文本嵌入模型的性能。该基准涵盖了各种具有挑战性的任务,包括指令跟随、长文档检索和代码检索等,旨在考察模型在不同场景下的泛化能力和鲁棒性。同时,为了降低计算成本,MMTEB还引入了降采样和负样本挖掘等技术,以提高评估效率。
技术框架:MMTEB的整体框架包括以下几个主要模块:1) 数据收集与整理:收集来自不同来源的文本数据,并进行清洗和预处理。2) 任务定义与构建:定义各种具有挑战性的评估任务,并构建相应的评估数据集。3) 模型评估:使用MMTEB基准评估各种文本嵌入模型的性能。4) 结果分析与报告:分析评估结果,并生成详细的报告,以便研究人员了解模型的优缺点。
关键创新:MMTEB最重要的技术创新点在于其大规模、多语言、多任务的特性。与现有的文本嵌入评估基准相比,MMTEB涵盖了更多的语言、领域和任务类型,能够更全面地评估模型的性能。此外,MMTEB还引入了降采样和负样本挖掘等技术,以提高评估效率。
关键设计:MMTEB的关键设计包括:1) 任务选择:选择具有代表性和挑战性的任务,以考察模型在不同场景下的泛化能力。2) 数据集构建:构建高质量的评估数据集,确保数据的多样性和准确性。3) 评估指标:选择合适的评估指标,以客观地衡量模型的性能。4) 降采样方法:采用基于任务间相关性的降采样方法,确保在降低计算成本的同时,保持相对模型排名。5) 负样本挖掘:通过采样困难负样本来优化检索等任务,提高评估的准确性。
🖼️ 关键图片


📊 实验亮点
MMTEB评估了多种文本嵌入模型,发现大型语言模型在特定语言和任务上表现出色,但multilingual-e5-large-instruct模型(仅5.6亿参数)在公开模型中表现最佳。此外,MMTEB提出的降采样方法在大幅降低计算成本的同时,保持了与完整基准相似的模型排名。
🎯 应用场景
MMTEB可用于评估和比较不同的文本嵌入模型,帮助研究人员选择适合特定任务的模型。此外,该基准还可以促进文本嵌入技术的发展,推动自然语言处理在信息检索、文本分类、机器翻译等领域的应用。
📄 摘要(原文)
Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.