The Self-Improvement Paradox: Can Language Models Bootstrap Reasoning Capabilities without External Scaffolding?
作者: Yutao Sun, Mingshuai Chen, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Jianwei Yin
分类: cs.CL, cs.AI
发布日期: 2025-02-19
💡 一句话要点
Crescent:一种无需外部监督信号的LLM自提升数学推理能力框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自提升 数学推理 零样本学习 知识蒸馏
📋 核心要点
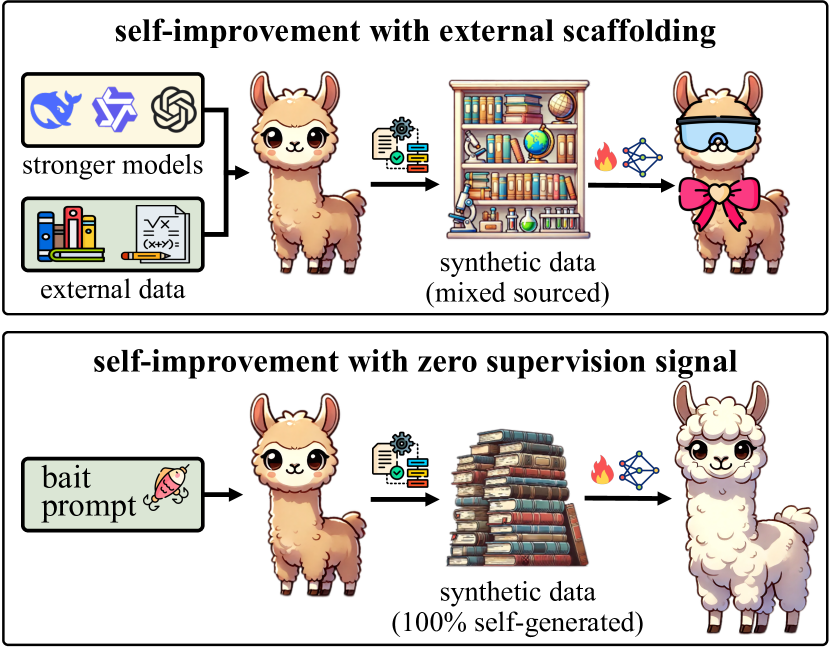
- 现有LLM自提升方法依赖外部监督信号(种子数据或第三方模型),限制了其自主性。
- Crescent框架通过诱导提示、自去重和多数投票,自主生成高质量的合成问答数据。
- 实验证明Crescent能有效提升LLM数学推理能力,并能更好地将知识蒸馏到小模型。
📝 摘要(中文)
本文提出了一种名为Crescent的框架,旨在实现大型语言模型(LLM)的自提升,即通过自身生成的合成数据来微调LLM,从而提高其性能,同时避免大量的外部监督。与现有依赖种子数据或第三方模型辅助的自提升方法不同,Crescent完全自主地生成高质量的合成问答数据。该框架首先通过诱导提示让LLM生成原始问题,然后利用基于拒绝采样的自去重方法对问题进行多样化处理,最后将问题反馈给LLM并通过多数投票收集相应的答案。实验表明,Crescent揭示了在零外部监督信号下实现真正自提升的潜力,尤其是在数学推理方面。Crescent生成的问答对足以(i)提高LLM的推理能力,同时保持其通用性能(尤其是在零样本设置下);(ii)比基于种子数据集增强的现有方法更有效地将LLM知识提炼到较弱的模型中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在缺乏外部监督的情况下,如何通过自身生成的数据进行微调,从而提升其推理能力的问题。现有自提升方法依赖于种子数据集或第三方模型的辅助,这限制了模型的自主性和泛化能力,并且增加了额外的成本。
核心思路:Crescent的核心思路是构建一个完全自主的自提升框架,通过精心设计的流程,让LLM能够生成高质量的训练数据,并利用这些数据来提升自身的推理能力。该方法避免了对外部资源的依赖,从而实现了真正的自提升。
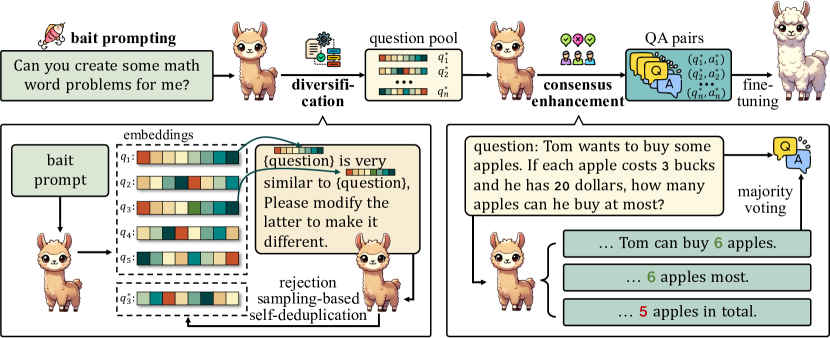
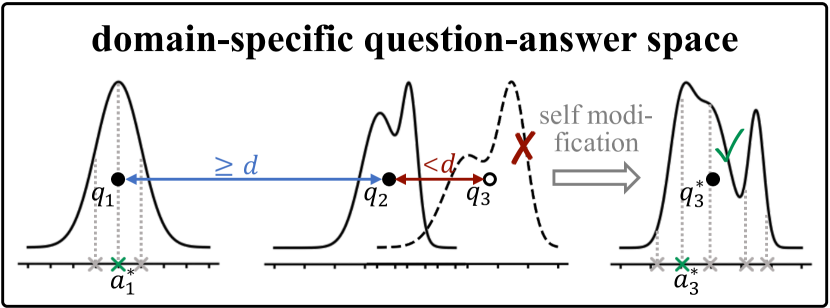
技术框架:Crescent框架包含三个主要阶段:问题生成、问题多样化和答案收集。首先,利用一个“诱导提示”让LLM生成原始问题。然后,使用基于拒绝采样的自去重方法来增加问题的多样性,避免生成重复或相似的问题。最后,将生成的问题反馈给LLM,并通过多数投票的方式收集答案,以提高答案的准确性。
关键创新:Crescent的关键创新在于其完全自主的数据生成流程。它不需要任何外部的种子数据集或第三方模型的辅助,而是完全依靠LLM自身的能力来生成高质量的训练数据。这种方法不仅降低了成本,还提高了模型的自主性和泛化能力。
关键设计:在问题生成阶段,使用了精心设计的“诱导提示”来引导LLM生成高质量的问题。在问题多样化阶段,使用了基于拒绝采样的自去重方法,通过计算问题之间的相似度,避免生成重复或相似的问题。在答案收集阶段,使用了多数投票的方法,通过多次生成答案并选择出现次数最多的答案,来提高答案的准确性。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Crescent框架能够有效提升LLM的数学推理能力,同时保持其通用性能。与基于种子数据集增强的现有方法相比,Crescent能够更有效地将LLM知识提炼到较弱的模型中。具体的性能提升数据在摘要中有所提及,但未给出具体数值。
🎯 应用场景
Crescent框架具有广泛的应用前景,可用于提升各种LLM的推理能力,尤其是在资源受限或缺乏外部监督的场景下。该方法可以应用于教育、金融、医疗等领域,帮助LLM更好地解决实际问题。此外,Crescent的自提升思想也可以推广到其他机器学习模型,促进人工智能技术的进一步发展。
📄 摘要(原文)
Self-improving large language models (LLMs) -- i.e., to improve the performance of an LLM by fine-tuning it with synthetic data generated by itself -- is a promising way to advance the capabilities of LLMs while avoiding extensive supervision. Existing approaches to self-improvement often rely on external supervision signals in the form of seed data and/or assistance from third-party models. This paper presents Crescent -- a simple yet effective framework for generating high-quality synthetic question-answer data in a fully autonomous manner. Crescent first elicits the LLM to generate raw questions via a bait prompt, then diversifies these questions leveraging a rejection sampling-based self-deduplication, and finally feeds the questions to the LLM and collects the corresponding answers by means of majority voting. We show that Crescent sheds light on the potential of true self-improvement with zero external supervision signals for math reasoning; in particular, Crescent-generated question-answer pairs suffice to (i) improve the reasoning capabilities of an LLM while preserving its general performance (especially in the 0-shot setting); and (ii) distil LLM knowledge to weaker models more effectively than existing methods based on seed-dataset augmentation.