RLTHF: Targeted Human Feedback for LLM Alignment
作者: Yifei Xu, Tusher Chakraborty, Emre Kıcıman, Bibek Aryal, Eduardo Rodrigues, Srinagesh Sharma, Roberto Estevao, Maria Angels de Luis Balaguer, Jessica Wolk, Rafael Padilha, Leonardo Nunes, Shobana Balakrishnan, Songwu Lu, Ranveer Chandra
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-19 (更新: 2025-08-06)
备注: Presented at ICML 2025
💡 一句话要点
RLTHF:通过有针对性的人工反馈实现LLM对齐,降低标注成本并提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人类反馈强化学习 模型对齐 人机协作 主动学习
📋 核心要点
- RLHF依赖大量高质量人工标注,成本高昂;AI反馈泛化性不足,难以保证模型对齐效果。
- RLTHF结合LLM初始对齐和选择性人工标注,利用奖励模型识别难标注样本,并进行针对性修正。
- 实验表明,RLTHF仅需少量人工标注即可达到完全人工标注水平,且下游任务性能更优。
📝 摘要(中文)
为了解决在基于人类反馈的强化学习(RLHF)中高质量人工标注成本高昂以及AI反馈泛化能力有限的问题,本文提出了RLTHF,一种人机混合框架。该框架结合了基于LLM的初始对齐和选择性的人工标注,以最小的代价实现完全人工标注级别的对齐。RLTHF利用奖励模型的奖励分布来识别被LLM错误标记的难以标注的样本,并通过整合战略性的人工修正,同时利用LLM正确标记的样本,迭代地增强对齐效果。在HH-RLHF和TL;DR数据集上的评估表明,RLTHF仅需6-7%的人工标注工作量即可达到完全人工标注级别的对齐。此外,在RLTHF精心策划的数据集上训练的下游任务模型,其性能优于在完全人工标注数据集上训练的模型,突显了RLTHF的有效性。
🔬 方法详解
问题定义:现有RLHF方法依赖大量人工标注,成本高昂。AI反馈虽然可以降低成本,但泛化能力有限,难以保证LLM与人类偏好对齐。因此,需要一种更高效的方法,在降低标注成本的同时,保证LLM的对齐效果。
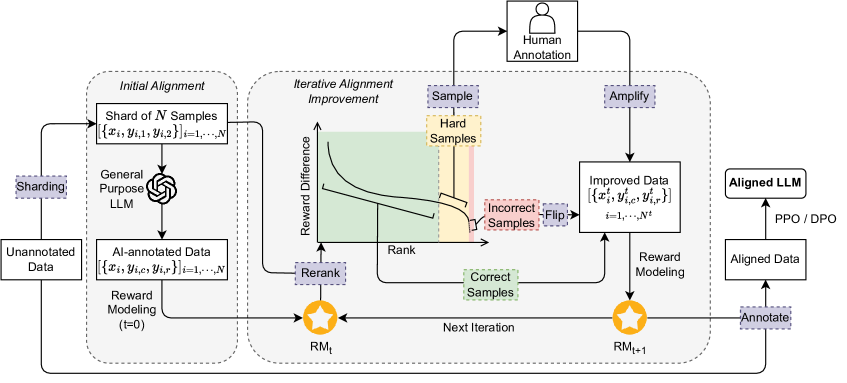
核心思路:RLTHF的核心思路是结合LLM的初始对齐能力和人工标注的准确性,通过选择性地对LLM难以正确标注的样本进行人工修正,从而以最小的代价实现与完全人工标注相当的对齐效果。这样既能利用LLM的标注能力,又能避免其错误标注带来的负面影响。
技术框架:RLTHF框架包含以下几个主要阶段:1) 使用LLM进行初始标注;2) 训练一个奖励模型,用于评估LLM标注的质量;3) 利用奖励模型的奖励分布,识别LLM难以正确标注的样本;4) 对这些难标注样本进行人工修正;5) 将人工修正后的数据与LLM正确标注的数据合并,用于训练LLM。这个过程可以迭代进行,不断提升LLM的对齐效果。
关键创新:RLTHF的关键创新在于提出了一种人机混合的标注框架,能够有效地利用LLM的标注能力,同时避免其错误标注带来的负面影响。通过奖励模型识别难标注样本,并进行针对性的人工修正,可以显著降低标注成本,并提升LLM的对齐效果。与完全依赖人工标注或AI反馈的方法相比,RLTHF具有更高的效率和更好的泛化能力。
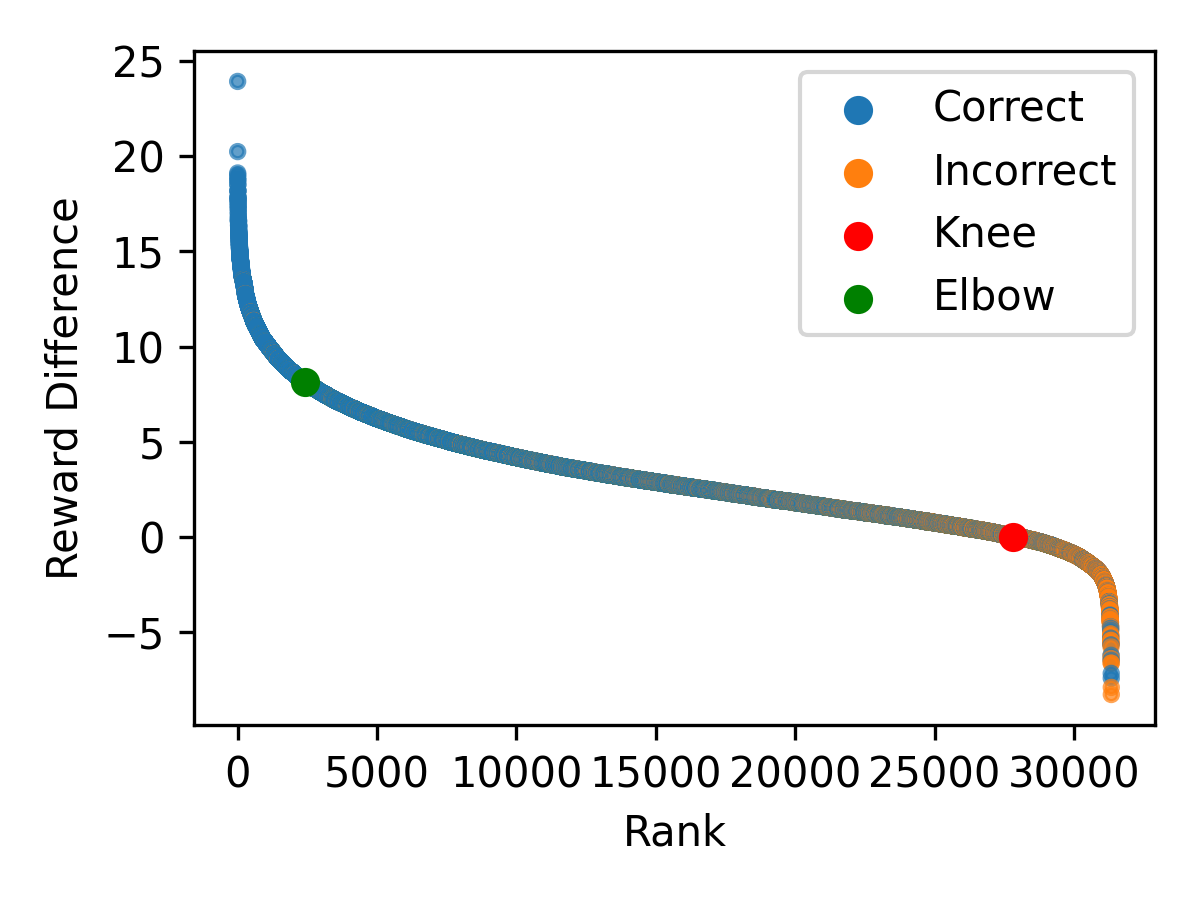
关键设计:奖励模型的设计至关重要,它需要能够准确地评估LLM标注的质量。奖励模型的输入是LLM生成的文本和对应的人工标注(或LLM标注),输出是一个奖励值,表示LLM标注的质量。奖励模型可以使用各种机器学习模型,例如Transformer模型。此外,如何选择难标注样本也是一个关键问题。RLTHF使用奖励模型的奖励分布来识别难标注样本,例如选择奖励值低于某个阈值的样本。具体的阈值需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
在HH-RLHF和TL;DR数据集上的实验结果表明,RLTHF仅需6-7%的人工标注工作量即可达到完全人工标注级别的对齐效果。更重要的是,在RLTHF精心策划的数据集上训练的下游任务模型,其性能优于在完全人工标注数据集上训练的模型,这表明RLTHF不仅降低了标注成本,还提升了模型的泛化能力。
🎯 应用场景
RLTHF可广泛应用于各种需要LLM与人类偏好对齐的场景,例如对话系统、文本摘要、代码生成等。通过降低标注成本,RLTHF使得LLM能够更好地服务于人类,并促进LLM在各个领域的应用。该方法还有助于提升LLM的安全性,避免生成有害或不当内容。
📄 摘要(原文)
Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF.