Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications
作者: Yiming Zeng, Wanhao Yu, Zexin Li, Tao Ren, Yu Ma, Jinghan Cao, Xiyan Chen, Tingting Yu
分类: cs.CL
发布日期: 2025-02-19 (更新: 2025-10-15)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
FineEdit:通过微调LLM实现精准和目标明确的文本编辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本编辑 微调 基准数据集 结构化文本 代码编辑 LaTeX编辑
📋 核心要点
- 现有LLM在精确文本编辑任务中表现不足,尤其在结构化和领域规范要求高的场景。
- FineEdit通过在InstrEditBench基准上进行专门训练,提升LLM的文本编辑能力。
- 实验表明,FineEdit在多个领域编辑任务上显著优于现有模型,提升幅度高达40%。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理领域取得了显著进展,在文本生成、摘要和推理等任务中表现出强大的能力。最近,它们在自动化精确文本编辑任务方面的潜力受到了关注,尤其是在编程代码、LaTeX和结构化数据库语言等专业领域。然而,当前最先进的LLM在执行精确的、指令驱动的编辑方面仍然存在困难,特别是在需要结构准确性和严格遵守领域规范时。为了应对这些挑战,我们引入了InstrEditBench,这是一个自动化的基准数据集,包含超过30,000个结构化编辑任务,涵盖维基百科文章、LaTeX文档、源代码和数据库语言等不同领域。基于此基准,我们开发了FineEdit,一个专门为准确、上下文感知的文本修改而训练的编辑模型。实验评估表明,FineEdit优于最先进的模型,在单轮编辑上比Gemini模型提高了约10%,比Llama-3.2-3B提高了高达30%,并且在直接编辑任务上超过Mistral-7B-OpenOrca的性能超过40%。FineEdit还可以有效地推广到实际的多轮编辑场景,突显了其在实际应用中的价值。为了促进进一步的研究和可重复性,我们发布了FineEdit。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在精确文本编辑任务中的不足。现有LLM在处理需要高度结构化和严格遵守领域规范的文本编辑任务时,例如编程代码、LaTeX文档和数据库语言,表现出明显的局限性。它们难以准确理解指令并执行相应的修改,导致编辑结果不符合预期或破坏文本的结构完整性。现有方法缺乏针对此类任务的专门训练和评估,难以满足实际应用的需求。
核心思路:论文的核心思路是构建一个专门用于训练和评估LLM文本编辑能力的基准数据集InstrEditBench,并在此基础上开发一个经过微调的编辑模型FineEdit。通过在InstrEditBench上进行训练,FineEdit能够学习到不同领域文本的结构和规范,从而更准确地理解编辑指令并执行相应的修改。这种方法的核心在于数据驱动,通过大量高质量的训练数据来提升模型的编辑能力。
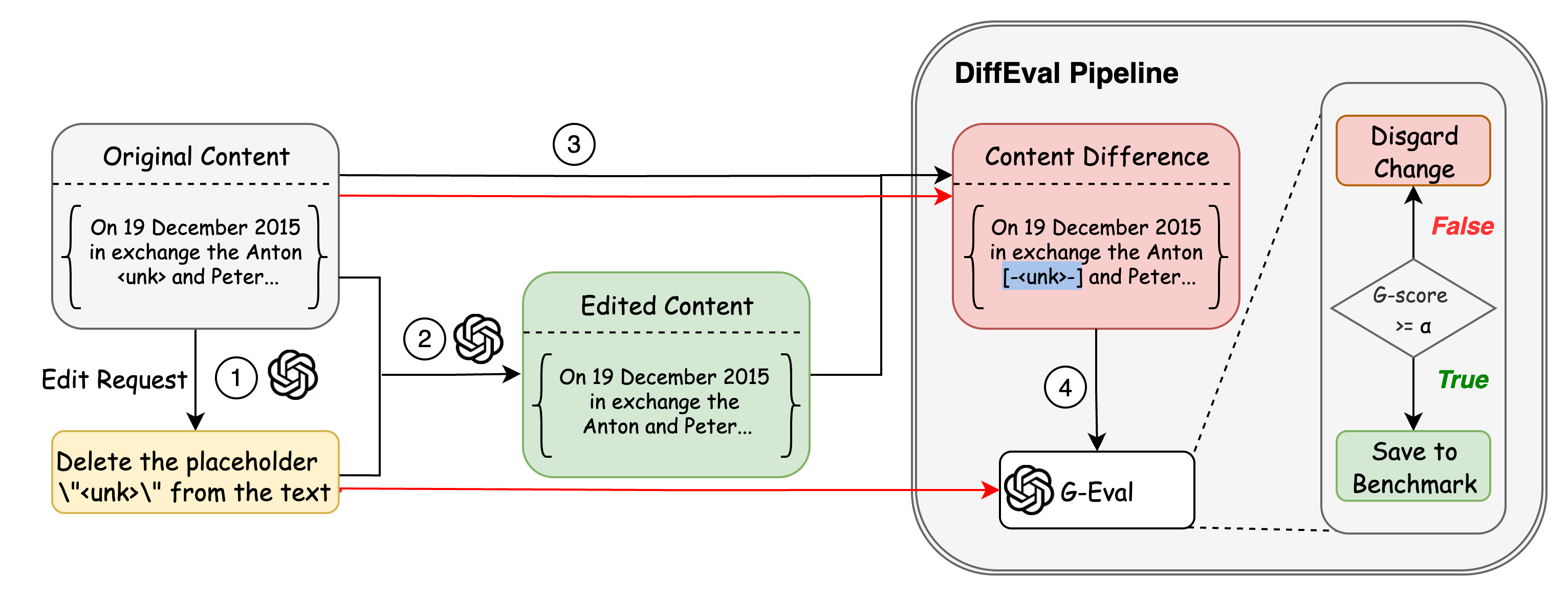
技术框架:FineEdit的技术框架主要包含两个部分:InstrEditBench基准数据集和FineEdit编辑模型。InstrEditBench是一个包含超过30,000个结构化编辑任务的自动化基准数据集,涵盖维基百科文章、LaTeX文档、源代码和数据库语言等多个领域。FineEdit是一个基于LLM的编辑模型,通过在InstrEditBench上进行微调,专门用于精确文本编辑任务。训练过程采用监督学习的方式,模型接收原始文本和编辑指令作为输入,输出修改后的文本。
关键创新:论文最重要的技术创新点在于InstrEditBench基准数据集的构建和FineEdit编辑模型的训练。InstrEditBench提供了一个全面、多样化的评估平台,可以有效地衡量LLM在精确文本编辑任务中的能力。FineEdit通过在InstrEditBench上进行微调,显著提升了LLM的编辑性能,克服了现有模型在结构化文本编辑方面的局限性。与现有方法相比,FineEdit更加注重数据驱动和领域知识的学习,从而实现了更准确、更可靠的文本编辑。
关键设计:InstrEditBench数据集包含多种类型的编辑任务,例如插入、删除、替换和移动文本等。数据集中的每个任务都包含原始文本、编辑指令和目标文本。FineEdit模型基于预训练的LLM,例如Llama或Mistral,并通过微调来适应文本编辑任务。微调过程中,采用交叉熵损失函数来衡量模型输出与目标文本之间的差异。为了提高模型的泛化能力,论文还采用了数据增强技术,例如随机替换、插入和删除文本等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FineEdit在InstrEditBench基准上显著优于现有模型。在单轮编辑任务中,FineEdit比Gemini模型提高了约10%,比Llama-3.2-3B提高了高达30%,并且在直接编辑任务上超过Mistral-7B-OpenOrca的性能超过40%。此外,FineEdit还能够有效地推广到实际的多轮编辑场景,证明了其在实际应用中的价值。
🎯 应用场景
FineEdit在多个领域具有广泛的应用前景,例如自动化代码重构、文档校对、数据库迁移和知识库维护等。它可以帮助用户更高效地完成文本编辑任务,提高工作效率和准确性。未来,FineEdit可以进一步扩展到更多领域,并与其他AI技术相结合,例如自然语言理解和知识图谱,从而实现更智能、更个性化的文本编辑服务。
📄 摘要(原文)
Large Language Models (LLMs) have significantly advanced natural language processing, demonstrating strong capabilities in tasks such as text generation, summarization, and reasoning. Recently, their potential for automating precise text editing tasks across specialized domains, such as programming code, LaTeX, and structured database languages, has gained attention. However, current state-of-the-art LLMs still struggle with executing precise, instruction-driven edits, particularly when structural accuracy and strict adherence to domain conventions are required. To address these challenges, we introduce InstrEditBench, an automated benchmark dataset comprising over 30,000 structured editing tasks spanning diverse domains, including Wikipedia articles, LaTeX documents, source code, and database languages. Using this benchmark, we develop FineEdit, a specialized editing model explicitly trained for accurate, context-aware text modifications. Experimental evaluations demonstrate that FineEdit outperforms state-of-the-art models, achieving improvements of approximately 10\% over Gemini models on single-turn edits, up to 30\% over Llama-3.2-3B, and exceeding Mistral-7B-OpenOrca performance by over 40\% on direct editing tasks. FineEdit also effectively generalizes to realistic multi-turn editing scenarios, highlighting its practical applicability. To facilitate further research and reproducibility, we release FineEdit at https://github.com/StuRinDQB/FineEdit} and https://huggingface.co/datasets/YimingZeng/FineEdit_bench.