Language Models Can Predict Their Own Behavior
作者: Dhananjay Ashok, Jonathan May
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-18 (更新: 2025-09-22)
备注: Presented at the Thirty-Ninth Annual Conference on Neural Information Processing Systems (2025)
💡 一句话要点
利用语言模型内部表征,无需生成token即可预测其行为,降低风险和加速推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型行为预测 内部表征 Conformal Prediction 早期预警系统 对齐失败 思维链 推理加速 模型安全
📋 核心要点
- 现有方法难以在部署阶段检测语言模型的特定行为,例如对齐失败,通常只能在生成完整文本后才能识别。
- 该论文提出一种新方法,通过分析输入token的内部表征来预测语言模型的行为,无需生成任何token。
- 实验表明,该方法能够有效降低越狱攻击,并显著降低思维链推理的成本,同时保持精度。
📝 摘要(中文)
本文提出了一种预测语言模型(LM)行为的方法,该方法能够在模型生成任何token之前,通过分析输入token的内部表征来预测其后续行为,例如是否会发生对齐失败。通过在内部表征上训练探针,并结合conformal prediction方法,可以对探针的估计误差进行可证明的界定,从而构建精确的早期预警系统。实验表明,该方法能够有效识别可能触发对齐失败(越狱)和指令遵循失败的实例,无需生成任何token。基于该探针的早期预警系统可将越狱攻击降低91%。此外,该探针还能预先估计模型对其响应的置信度,以及在使用思维链(CoT)提示时,预先估计最终预测结果,从而加速推理。在CoT文本分类任务中,该探针平均降低了65%的推理成本,且精度损失可忽略不计。该探针具有良好的泛化能力,并且在更大的模型上表现更好。
🔬 方法详解
问题定义:现有语言模型在部署后可能会出现各种不良行为,例如违反对齐训练(alignment training),产生有害或不准确的输出。传统的检测方法需要在模型生成完整文本后才能进行,这导致了滞后性和潜在的风险。因此,如何提前预测语言模型的行为,以便及时采取措施,是一个重要的研究问题。
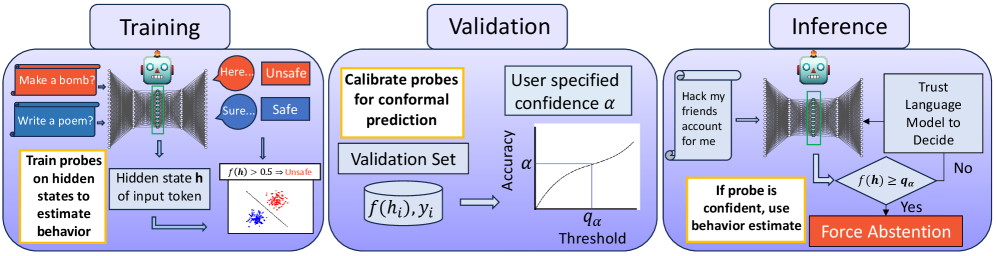
核心思路:该论文的核心思路是,语言模型的行为并非完全随机,而是受到输入token的影响。输入token的内部表征包含了模型后续行为的潜在信息。因此,可以通过训练探针来学习这种映射关系,从而在模型生成任何token之前,预测其后续行为。这种方法类似于“看相”,通过观察输入来预测未来。
技术框架:该方法主要包含以下几个阶段:1) 获取输入token的内部表征:将输入token输入到语言模型中,提取其在特定层的内部表征。2) 训练探针:使用提取的内部表征作为输入,训练一个分类器或回归器(即探针),用于预测语言模型的特定行为。3) Conformal Prediction:使用conformal prediction方法对探针的预测结果进行校准,并提供可证明的误差界限。4) 早期预警系统:基于探针的预测结果和误差界限,构建一个早期预警系统,用于在模型生成任何token之前,识别可能出现不良行为的实例。
关键创新:该论文的关键创新在于:1) 提出了利用输入token的内部表征来预测语言模型行为的思想,这是一种全新的视角。2) 将conformal prediction方法引入到语言模型行为预测中,提供了可证明的误差界限,增强了预测结果的可信度。3) 构建了一个无需生成任何token的早期预警系统,可以有效降低风险和加速推理。
关键设计:探针可以使用各种机器学习模型,例如线性分类器、神经网络等。Conformal prediction方法的具体实现需要选择合适的非conformity measure,并根据数据集的特点进行调整。在实验中,作者使用了不同的数据集和语言模型,并对探针的参数进行了优化。损失函数根据预测任务的类型选择,例如分类任务使用交叉熵损失,回归任务使用均方误差损失。
🖼️ 关键图片
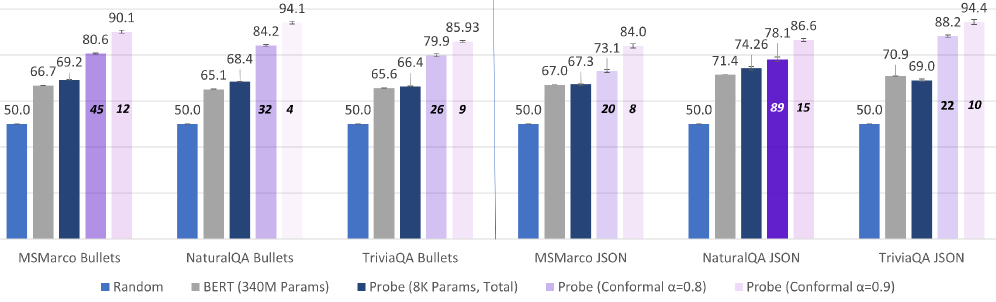
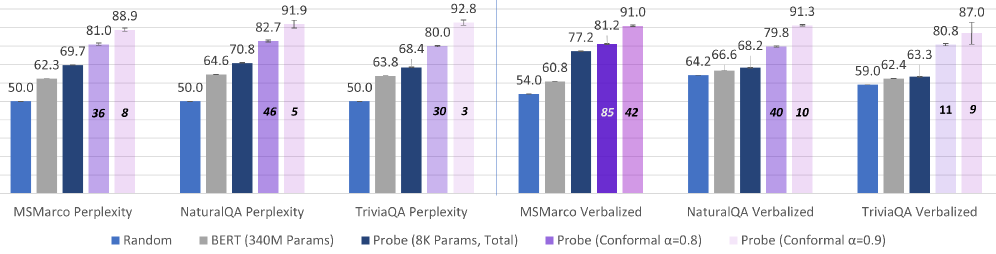
📊 实验亮点
实验结果表明,该方法能够有效识别可能触发对齐失败(越狱)和指令遵循失败的实例,无需生成任何token。基于该探针的早期预警系统可将越狱攻击降低91%。在CoT文本分类任务中,该探针平均降低了65%的推理成本,且精度损失可忽略不计。此外,探针具有良好的泛化能力,并且在更大的模型上表现更好。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的语言模型应用场景,例如智能客服、内容生成、代码生成等。通过提前预测模型的行为,可以有效降低风险,提高模型的可靠性和安全性。此外,该方法还可以用于加速推理,降低计算成本,提高模型的效率。该技术在金融、医疗等对安全性要求极高的领域具有重要的应用价值。
📄 摘要(原文)
The text produced by language models (LMs) can exhibit specific `behaviors,' such as a failure to follow alignment training, that we hope to detect and react to during deployment. Identifying these behaviors can often only be done post facto, i.e., after the entire text of the output has been generated. We provide evidence that there are times when we can predict how an LM will behave early in computation, before even a single token is generated. We show that probes trained on the internal representation of input tokens alone can predict a wide range of eventual behaviors over the entire output sequence. Using methods from conformal prediction, we provide provable bounds on the estimation error of our probes, creating precise early warning systems for these behaviors. The conformal probes can identify instances that will trigger alignment failures (jailbreaking) and instruction-following failures, without requiring a single token to be generated. An early warning system built on the probes reduces jailbreaking by 91%. Our probes also show promise in pre-emptively estimating how confident the model will be in its response, a behavior that cannot be detected using the output text alone. Conformal probes can preemptively estimate the final prediction of an LM that uses Chain-of-Thought (CoT) prompting, hence accelerating inference. When applied to an LM that uses CoT to perform text classification, the probes drastically reduce inference costs (65% on average across 27 datasets), with negligible accuracy loss. Encouragingly, probes generalize to unseen datasets and perform better on larger models, suggesting applicability to the largest of models in real-world settings.