Improving Multi-turn Task Completion in Task-Oriented Dialog Systems via Prompt Chaining and Fine-Grained Feedback
作者: Moghis Fereidouni, Md Sajid Ahmed, Adib Mosharrof, A. B. Siddique
分类: cs.CL
发布日期: 2025-02-18 (更新: 2025-12-26)
备注: 7 pages
💡 一句话要点
RealTOD框架通过提示链和细粒度反馈,显著提升面向任务对话系统中多轮任务完成的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 面向任务对话系统 多轮对话 大型语言模型 提示学习 细粒度反馈 API调用 零样本学习
📋 核心要点
- 现有面向任务对话系统中的大型语言模型在多轮任务完成时,尤其是在生成与外部系统交互所需的API调用时,表现出可靠性不足的问题。
- RealTOD框架通过提示链自动生成schema对齐的上下文示例,实现零样本泛化,并利用细粒度反馈纠正API调用中的错误。
- 实验表明,RealTOD显著提升了API调用准确率,并在SGD和BiTOD基准测试中超越了现有技术水平,同时在人工评估中表现出更优的任务完成质量。
📝 摘要(中文)
本文提出RealTOD框架,旨在提升基于大型语言模型(LLM)的面向任务对话(TOD)系统中多轮任务完成的可靠性。该框架通过提示链和细粒度反馈两个关键机制实现改进。提示链通过自动合成与目标任务模式对齐的上下文示例,实现零样本泛化到新领域。细粒度反馈则验证每个生成的API调用,对照领域模式识别具体错误,并提供有针对性的纠正提示。为评估任务完成可靠性,本文引入了完整的API调用准确率作为鲁棒的指标,以及捕获常见失败模式的详细子指标。在SGD和BiTOD基准上使用四个LLM进行的大量实验表明,RealTOD提高了完整的API准确率,在SGD上超过了最先进的AutoTOD 37.10%,在BiTOD上超过了基于监督学习的基线SimpleTOD 10.32%。人工评估进一步证实,集成RealTOD的LLM在任务完成、流畅性和信息性方面优于现有方法。
🔬 方法详解
问题定义:论文旨在解决面向任务对话系统中,大型语言模型在多轮对话中生成准确API调用的问题。现有方法在复杂任务和新领域泛化能力不足,容易产生不符合schema的API调用,导致任务失败。
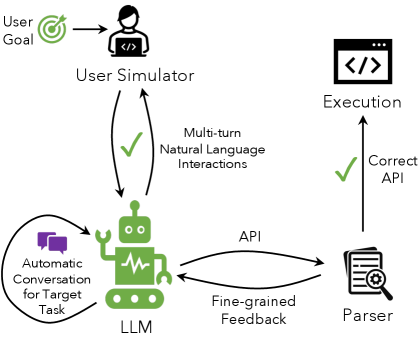
核心思路:RealTOD的核心思路是利用提示链(Prompt Chaining)实现零样本泛化,并结合细粒度反馈(Fine-grained Feedback)机制纠正API调用中的错误。通过提示链,模型可以学习到如何根据给定的schema生成正确的API调用。细粒度反馈则可以及时发现并纠正API调用中的错误,提高整体的准确性。
技术框架:RealTOD框架主要包含两个阶段:提示链阶段和细粒度反馈阶段。在提示链阶段,系统根据目标领域的schema自动生成一个上下文示例,该示例包含用户意图和对应的API调用。这个示例被添加到模型的输入提示中,引导模型生成正确的API调用。在细粒度反馈阶段,系统验证模型生成的API调用是否符合schema,如果发现错误,则生成一个纠正提示,并将其添加到模型的输入中,引导模型生成更正后的API调用。
关键创新:RealTOD的关键创新在于将提示链和细粒度反馈相结合,实现零样本泛化和错误纠正。提示链使得模型能够快速适应新的领域,而细粒度反馈则能够有效地纠正API调用中的错误。此外,论文还提出了Full API Call Accuracy这一新的评估指标,能够更全面地评估模型的性能。
关键设计:提示链通过从schema中提取关键信息,并使用预定义的模板生成上下文示例。细粒度反馈则使用schema验证器来检查API调用是否符合schema,并根据错误类型生成不同的纠正提示。具体的参数设置和网络结构未知,因为论文侧重于框架设计而非特定模型的微调。
🖼️ 关键图片


📊 实验亮点
RealTOD在SGD数据集上相比AutoTOD提升了37.10%的Full API Call Accuracy,在BiTOD数据集上相比SimpleTOD提升了10.32%。人工评估也表明,RealTOD在任务完成、流畅性和信息性方面均优于现有方法,证明了该框架的有效性。
🎯 应用场景
RealTOD框架可应用于各种面向任务的对话系统,例如智能助手、客户服务机器人等。通过提升多轮对话中API调用的准确性,可以显著提高用户体验,并降低人工干预的需求。该研究对于构建更可靠、更智能的对话系统具有重要的实际价值和潜在影响。
📄 摘要(原文)
Task-oriented dialog (TOD) systems facilitate users in accomplishing complex, multi-turn tasks through natural language. While instruction-tuned large language models (LLMs) have demonstrated strong performance on a range of single-turn NLP tasks, they often struggle with reliable multi-turn task completion in TOD settings, particularly when generating API calls required to interact with external systems. To address this, we introduce RealTOD, a novel framework that improves LLM-based TOD systems through (1) prompt chaining and (2) fine-grained feedback. Prompt chaining enables zero-shot generalization to new domains by automatically synthesizing a schema-aligned in-context example for the target task. Fine-grained feedback verifies each generated API call against the domain schema, identifies specific errors, and provides targeted correction prompts. To evaluate task completion reliability, we introduce full API Call Accuracy as a robust metric, along with detailed sub-metrics to capture common failure modes. We conduct extensive experiments on the SGD and BiTOD benchmarks using four LLMs. RealTOD improves Full API accuracy, surpassing state-of-the-art AutoTOD by 37.10% on SGD and supervised learning-based baseline SimpleTOD by 10.32% on BiTOD. Human evaluations further confirm that LLMs integrated with RealTOD achieve superior task completion, fluency, and informativeness compared to existing methods.