Neural Attention Search
作者: Difan Deng, Marius Lindauer
分类: cs.CL, cs.AI
发布日期: 2025-02-18 (更新: 2025-10-23)
备注: 35 pages, 11 figures
💡 一句话要点
提出神经注意力搜索(NAtS)框架,用于降低Transformer模型推理时KV缓存大小,从而降低推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经注意力搜索 Transformer KV缓存 模型压缩 推理加速 长文本处理 注意力机制
📋 核心要点
- Transformer模型推理时KV缓存占用大量内存,限制了长序列处理和部署。
- NAtS通过学习token的重要性,动态丢弃不重要的token,从而减少KV缓存大小。
- 实验表明,NAtS能在降低KV缓存的同时,保持模型性能,适用于从头训练和微调。
📝 摘要(中文)
本文提出了一种名为神经注意力搜索(NAtS)的框架,该框架能够自动评估序列中每个token的重要性,并确定是否可以在若干步骤后丢弃相应的token。这种方法可以有效地减少基于Transformer的模型在推理过程中所需的KV缓存大小,从而降低推理成本。在本文中,我们设计了一个包含三种token类型的搜索空间:(i)全局Token将被保留并被所有后续token查询。(ii)局部Token存活到下一个全局token出现。(iii)滑动窗口Token对固定大小的后续token的推理产生影响。类似于One-Shot神经架构搜索方法,这种token类型信息可以通过可学习的注意力掩码与架构权重联合学习。在新Transformer的从头训练和现有大型语言模型的微调实验表明,NAtS可以有效地减少模型所需的KV缓存大小,同时保持模型的性能。
🔬 方法详解
问题定义:Transformer模型在推理阶段,需要维护一个KV缓存来存储所有token的键(Key)和值(Value)向量,以便进行注意力计算。随着序列长度的增加,KV缓存的大小也会线性增长,导致内存占用过高,推理速度变慢,尤其是在处理长文本时,这个问题更加突出。现有的方法通常采用模型压缩、量化等技术,但这些方法可能会导致模型性能下降。
核心思路:NAtS的核心思路是学习每个token的重要性,并根据其重要性动态地决定是否保留该token在KV缓存中。通过丢弃不重要的token,可以有效地减少KV缓存的大小,从而降低推理成本。这种方法的关键在于如何准确地评估token的重要性,并在保证模型性能的前提下,尽可能多地丢弃token。
技术框架:NAtS框架包含一个可学习的注意力掩码,用于评估每个token的重要性。该掩码与架构权重联合学习,使得模型能够自动地学习到哪些token是重要的,哪些token是可以丢弃的。框架定义了三种token类型:全局Token、局部Token和滑动窗口Token。全局Token始终保留在KV缓存中,局部Token保留到下一个全局Token出现,滑动窗口Token只影响固定大小的后续token。通过这三种token类型的组合,可以灵活地控制KV缓存的大小。
关键创新:NAtS的关键创新在于提出了一种基于神经注意力的token重要性评估方法,并将其与架构权重联合学习。与传统的token剪枝方法不同,NAtS能够自动地学习到哪些token是重要的,从而避免了手动选择token的困难。此外,NAtS还定义了三种token类型,使得可以更加灵活地控制KV缓存的大小。
关键设计:NAtS使用一个可学习的注意力掩码来评估每个token的重要性。该掩码的输出是一个概率值,表示该token被保留的概率。在训练过程中,使用交叉熵损失函数来优化该掩码,使得重要的token的保留概率接近1,不重要的token的保留概率接近0。此外,还使用了一个正则化项来防止掩码过于稀疏。三种token类型的具体实现方式未知,论文中可能没有详细描述。
🖼️ 关键图片
📊 实验亮点
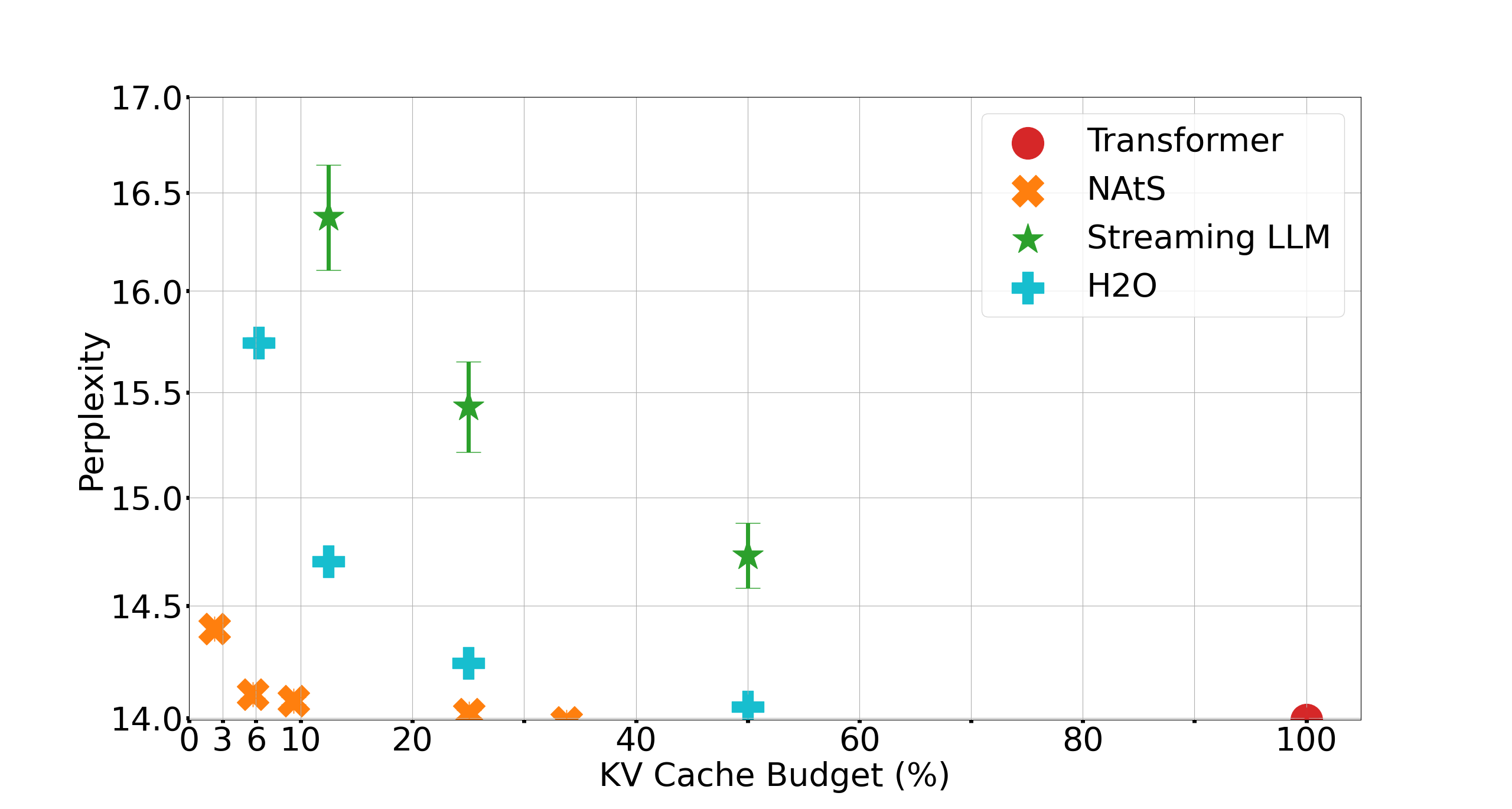
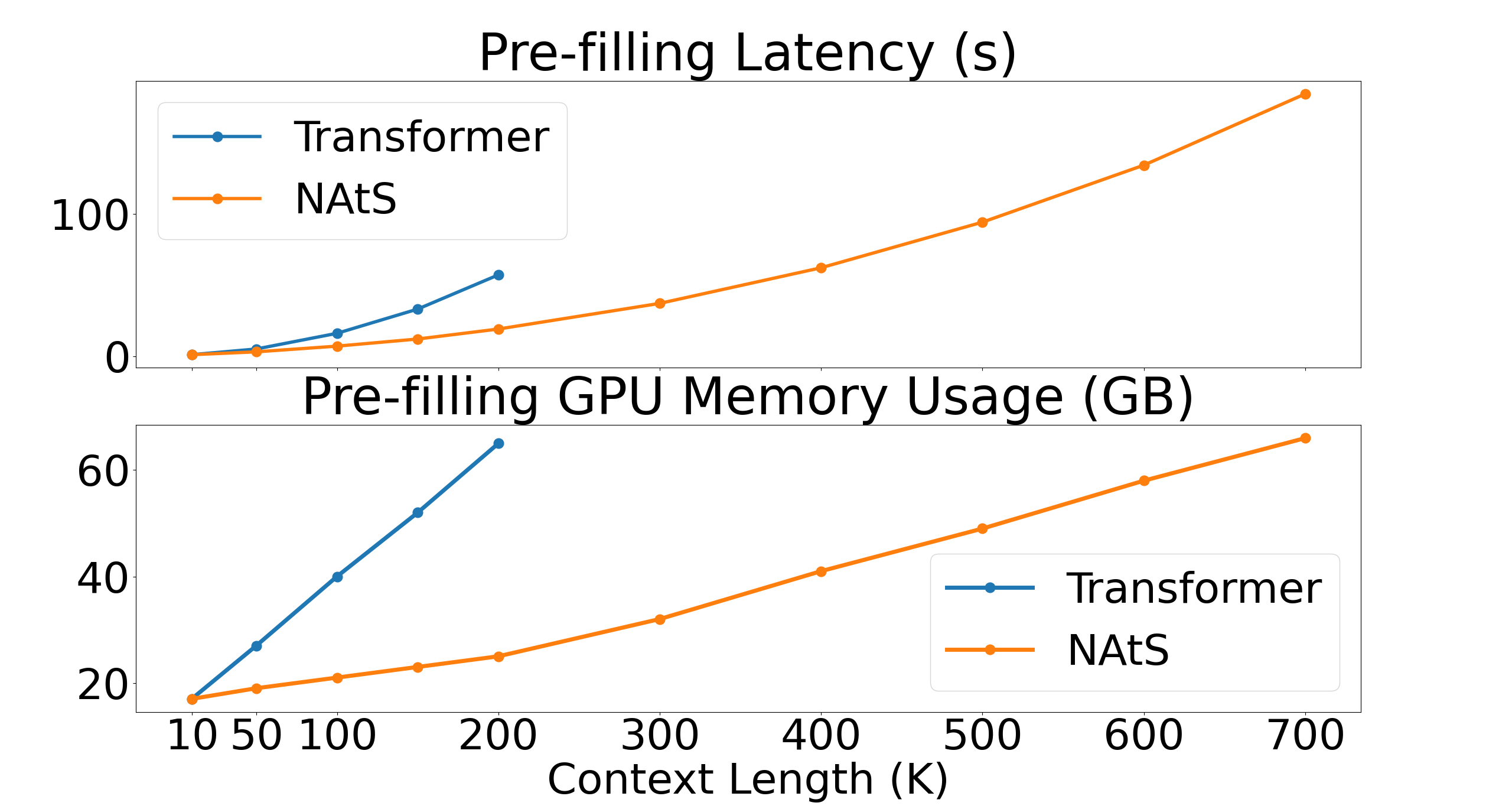
论文通过在新Transformer的从头训练和现有大型语言模型的微调实验验证了NAtS的有效性。实验结果表明,NAtS能够在显著降低KV缓存大小的同时,保持模型的性能。具体的性能数据和提升幅度未知,需要在论文中查找。
🎯 应用场景
NAtS可应用于各种基于Transformer的自然语言处理任务,尤其是在需要处理长文本的场景下,如机器翻译、文本摘要、问答系统等。通过降低KV缓存的大小,可以显著降低推理成本,使得这些模型能够部署在资源受限的设备上,如移动设备、嵌入式系统等。此外,NAtS还可以用于加速模型的训练过程,通过减少KV缓存的大小,可以减少内存占用,从而提高训练速度。
📄 摘要(原文)
We present Neural Attention Search (NAtS), a framework that automatically evaluates the importance of each token within a sequence and determines if the corresponding token can be dropped after several steps. This approach can efficiently reduce the KV cache sizes required by transformer-based models during inference and thus reduce inference costs. In this paper, we design a search space that contains three token types: (i) Global Tokens will be preserved and queried by all the following tokens. (ii) Local Tokens survive until the next global token appears. (iii) Sliding Window Tokens have an impact on the inference of a fixed size of the next following tokens. Similar to the One-Shot Neural Architecture Search approach, this token-type information can be learned jointly with the architecture weights via a learnable attention mask. Experiments on both training a new transformer from scratch and fine-tuning existing large language models show that NAtS can efficiently reduce the KV cache size required for the models while maintaining the models' performance.