Thinking Outside the (Gray) Box: A Context-Based Score for Assessing Value and Originality in Neural Text Generation
作者: Giorgio Franceschelli, Mirco Musolesi
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2025-02-18 (更新: 2025-09-25)
💡 一句话要点
提出基于上下文的评分方法,提升神经文本生成中的价值和原创性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经文本生成 原创性评估 强化学习 上下文评分 大型语言模型
📋 核心要点
- 大型语言模型在创造性任务中应用广泛,但其生成结果常缺乏多样性,提高采样温度等方法又会降低生成质量。
- 论文提出一种基于上下文的评分方法,该方法基于信息论,旨在定量评估生成文本的价值和原创性。
- 实验表明,该评分方法可作为强化学习的奖励信号,用于微调大型语言模型,从而提升生成文本的价值和原创性,例如在诗歌生成和数学问题解决等任务中。
📝 摘要(中文)
尽管大型语言模型在创造性任务中得到越来越多的应用,但其输出通常缺乏多样性。常用的解决方案,如提高采样温度,可能会降低结果的质量。在设计用于创造性任务的AI系统中,如何处理这种权衡仍然是一个开放的挑战。本文借鉴信息论,提出了一种基于上下文的评分方法,用于定量评估价值和原创性。该评分鼓励准确性和对请求的遵守,同时促进与已学习分布的差异。我们证明了我们的评分可以作为强化学习框架中的奖励,用于微调大型语言模型以获得最佳性能。我们通过考虑各种创造性任务(如诗歌生成和数学问题解决)的实验验证了我们的策略,证明它可以提高生成解决方案的价值和原创性。
🔬 方法详解
问题定义:现有的大型语言模型在创造性任务中,如诗歌生成、数学问题求解等,生成的文本往往缺乏原创性和价值,容易陷入重复和模式化的内容。简单地提高采样温度虽然可以增加多样性,但会牺牲生成文本的质量和准确性。因此,如何在保证生成质量的前提下,提升文本的原创性和价值是一个亟待解决的问题。
核心思路:论文的核心思路是设计一个基于上下文的评分函数,该函数能够同时衡量生成文本的价值(例如,准确性、相关性)和原创性(例如,与模型学习到的分布的差异)。通过信息论的视角,该评分函数能够激励模型生成既符合要求又具有新颖性的文本。
技术框架:该方法主要包含两个阶段:首先,定义基于上下文的评分函数,该函数结合了价值和原创性两个方面的考量。其次,将该评分函数作为强化学习的奖励信号,用于微调预训练的大型语言模型。通过强化学习,模型能够学习到如何生成更高价值和更具原创性的文本。整体流程是:输入prompt -> 大型语言模型生成文本 -> 上下文评分函数评估文本 -> 强化学习更新模型参数 -> 迭代优化。
关键创新:该方法最重要的创新在于提出了一个能够同时评估价值和原创性的上下文评分函数。传统的评估方法往往只关注生成文本的准确性或流畅性,而忽略了原创性。该评分函数通过信息论的原理,将价值和原创性有机结合,从而能够更全面地评估生成文本的质量。
关键设计:评分函数的设计是关键。具体来说,价值部分可能通过计算生成文本与prompt的相关性或准确性来衡量,例如使用BLEU score或ROUGE score。原创性部分则可能通过计算生成文本与模型学习到的分布的差异来衡量,例如使用KL散度或perplexity。最终的评分函数可能是价值和原创性两部分的加权和,权重系数需要根据具体任务进行调整。强化学习部分,可以使用常见的策略梯度算法,如REINFORCE或PPO,来更新模型参数。
🖼️ 关键图片

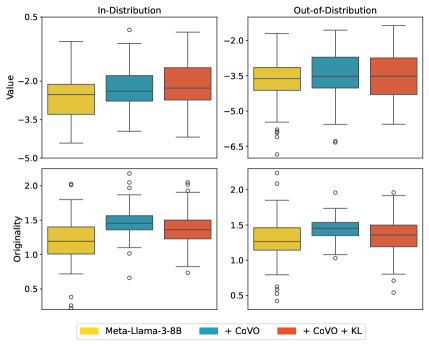
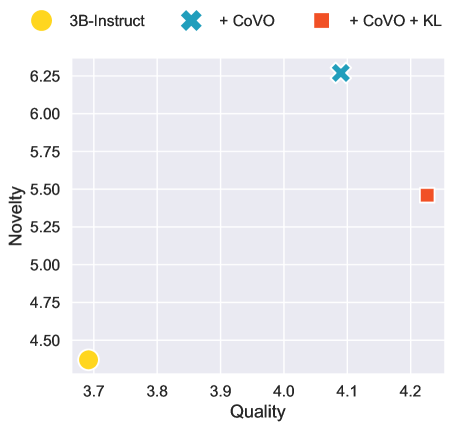
📊 实验亮点
实验结果表明,该方法在诗歌生成和数学问题解决等创造性任务中,显著提升了生成文本的价值和原创性。与传统的基于采样温度的方法相比,该方法能够在保证生成质量的前提下,更好地探索新的文本空间。具体的性能数据(例如,评分函数的数值提升)和对比基线(例如,不同采样温度下的生成结果)需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于各种需要创造性文本生成的领域,例如:自动诗歌创作、故事生成、剧本撰写、广告文案生成、以及教育领域的个性化学习内容生成等。通过提升生成文本的价值和原创性,可以提高用户体验,并为相关应用带来更大的商业价值和学术价值。未来,该方法还可以扩展到其他模态的生成任务,例如图像生成、音乐生成等。
📄 摘要(原文)
Despite the increasing use of large language models for creative tasks, their outputs often lack diversity. Common solutions, such as sampling at higher temperatures, can compromise the quality of the results. Dealing with this trade-off is still an open challenge in designing AI systems for creativity. Drawing on information theory, we propose a context-based score to quantitatively evaluate value and originality. This score incentivizes accuracy and adherence to the request while fostering divergence from the learned distribution. We show that our score can be used as a reward in a reinforcement learning framework to fine-tune large language models for maximum performance. We validate our strategy through experiments considering a variety of creative tasks, such as poetry generation and math problem solving, demonstrating that it enhances the value and originality of the generated solutions.