Facilitating Long Context Understanding via Supervised Chain-of-Thought Reasoning
作者: Jingyang Lin, Andy Wong, Tian Xia, Shenghua He, Hui Wei, Mei Han, Jiebo Luo
分类: cs.CL
发布日期: 2025-02-18 (更新: 2025-12-01)
备注: Main Conference of EMNLP 2025, Project Page: https://long-pai.github.io/
💡 一句话要点
提出基于监督式思维链推理的长文本理解方法,并构建金融领域合成数据集LongFinanceQA。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 思维链推理 监督学习 金融领域 合成数据集 代理推理 LLM微调
📋 核心要点
- 现有LLM在长文本处理中,简单增加输入长度难以有效提升理解能力,缺乏显式的推理过程。
- 论文提出监督式思维链推理方法,通过中间推理步骤提升LLM在长文本中的准确性和可解释性。
- 构建金融领域合成数据集LongFinanceQA,并使用PAI框架生成CoT推理,实验表明该方法在长文本理解任务上性能显著提升。
📝 摘要(中文)
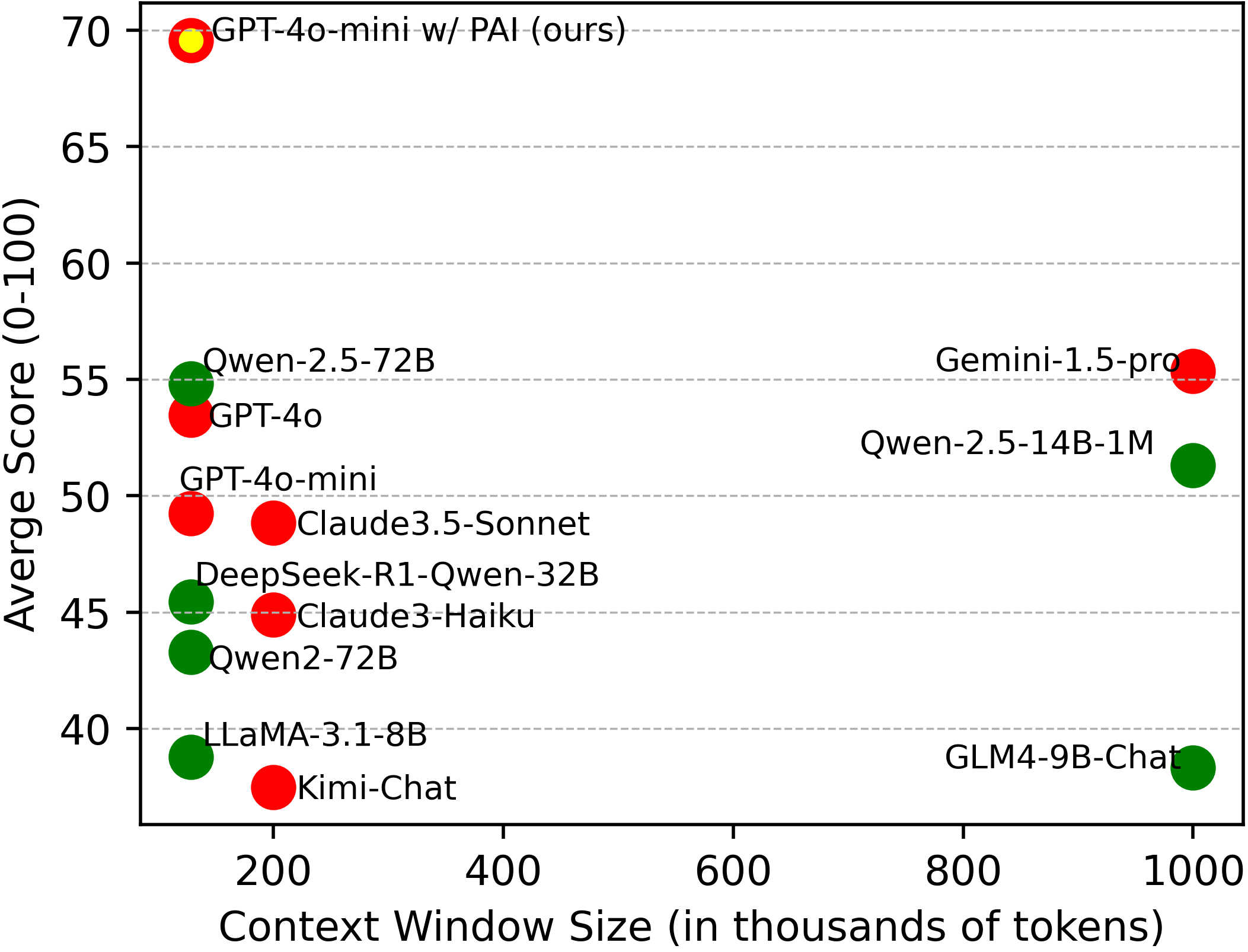
大型语言模型(LLMs)处理长序列的能力不断增强。然而,简单地扩展输入序列长度并不一定能带来有效的长文本理解。本研究将思维链(CoT)推理以监督方式集成到LLM中,以促进有效的长文本理解。为此,我们引入了LongFinanceQA,这是一个金融领域的合成数据集,旨在改进长文本推理。与现有的长文本合成数据不同,LongFinanceQA包含最终结论之前的中间CoT推理,这鼓励LLM执行显式推理,从而提高长文本理解的准确性和可解释性。为了生成合成CoT推理,我们提出了基于属性的代理推理(PAI),这是一个模拟类人推理步骤的代理框架,包括属性提取、检索和总结。我们在Loong基准上评估了GPT-4o-mini w/ PAI的推理能力,优于标准GPT-4o-mini 20.0%。此外,我们在LongFinanceQA上微调了LLaMA-3.1-8B-Instruct,在Loong的金融子集上实现了28.0%的提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理长文本时,仅仅增加输入长度而无法有效提升理解能力的问题。现有的方法缺乏显式的推理过程,导致模型难以捕捉长文本中的关键信息和逻辑关系,从而影响最终的预测准确性和可解释性。
核心思路:论文的核心思路是将思维链(Chain-of-Thought, CoT)推理以监督的方式集成到大型语言模型中。通过引入中间推理步骤,鼓励模型进行显式的推理,从而提高模型在长文本理解任务中的准确性和可解释性。这种方法模拟了人类在处理复杂问题时的思考过程,有助于模型更好地理解长文本中的语义信息。
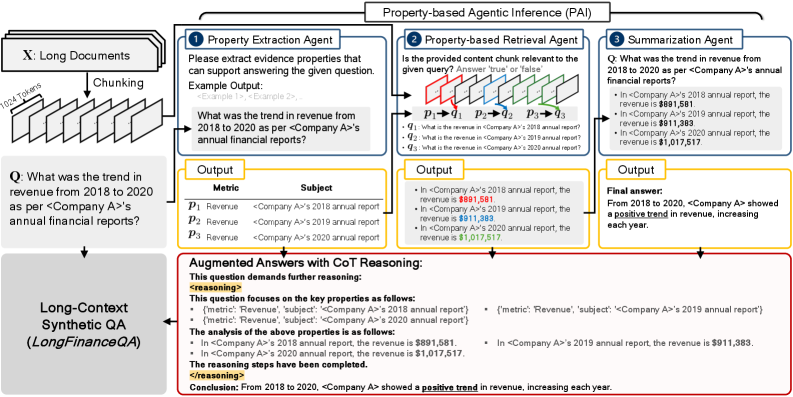
技术框架:论文提出的技术框架主要包括两个部分:一是构建金融领域的合成数据集LongFinanceQA,二是提出基于属性的代理推理(Property-based Agentic Inference, PAI)框架。LongFinanceQA数据集包含最终结论之前的中间CoT推理,用于训练模型进行显式推理。PAI框架模拟类人推理步骤,包括属性提取、检索和总结,用于生成合成CoT推理。整体流程是先使用PAI框架生成LongFinanceQA数据集,然后使用该数据集对LLM进行微调,最后在长文本理解任务上进行评估。
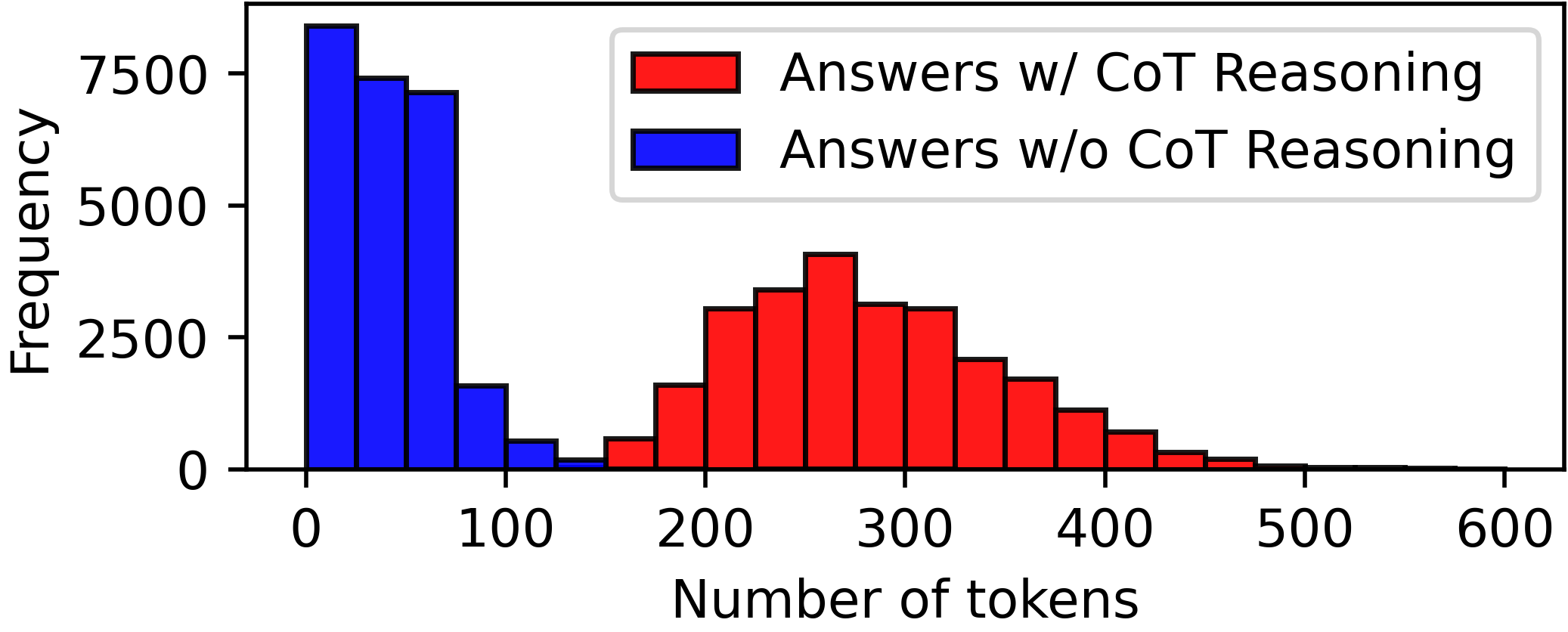
关键创新:论文最重要的技术创新点在于将CoT推理以监督的方式集成到LLM中,并提出了PAI框架用于生成合成CoT推理。与现有方法相比,该方法鼓励模型进行显式推理,从而提高模型在长文本理解任务中的准确性和可解释性。此外,LongFinanceQA数据集的构建也为长文本理解领域的研究提供了新的资源。
关键设计:PAI框架的关键设计包括属性提取、检索和总结三个步骤。属性提取用于从长文本中提取关键信息;检索用于从外部知识库中检索相关信息;总结用于将提取的信息和检索的信息进行整合,生成中间推理步骤。LongFinanceQA数据集的关键设计在于包含最终结论之前的中间CoT推理,用于训练模型进行显式推理。在实验中,论文使用了GPT-4o-mini和LLaMA-3.1-8B-Instruct等大型语言模型,并对这些模型进行了微调。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o-mini w/ PAI在Loong基准测试中优于标准GPT-4o-mini 20.0%。此外,在LongFinanceQA上微调LLaMA-3.1-8B-Instruct后,在Loong的金融子集上实现了28.0%的性能提升。这些结果充分证明了论文提出的方法在长文本理解任务上的有效性。
🎯 应用场景
该研究成果可应用于金融文档处理、法律文本分析、科研报告解读等需要长文本理解的领域。通过提升LLM在长文本理解方面的能力,可以有效提高信息提取、问答系统和智能决策的效率和准确性,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have enabled them to process increasingly longer sequences, ranging from 2K to 2M tokens and even beyond. However, simply extending the input sequence length does not necessarily lead to effective long-context understanding. In this study, we integrate Chain-of-Thought (CoT) reasoning into LLMs in a supervised manner to facilitate effective long-context understanding. To achieve this, we introduce LongFinanceQA, a synthetic dataset in the financial domain designed to improve long-context reasoning. Unlike existing long-context synthetic data, LongFinanceQA includes intermediate CoT reasoning before the final conclusion, which encourages LLMs to perform explicit reasoning, improving accuracy and interpretability in long-context understanding. To generate synthetic CoT reasoning, we propose Property-based Agentic Inference (PAI), an agentic framework that simulates human-like reasoning steps, including property extraction, retrieval, and summarization. We evaluate PAI's reasoning capabilities by assessing GPT-4o-mini w/ PAI on the Loong benchmark, outperforming standard GPT-4o-mini by 20.0%. Furthermore, we fine-tune LLaMA-3.1-8B-Instruct on LongFinanceQA, achieving a 28.0% gain on Loong's financial subset.